Линейный коэффициент корреляции пирсона
Содержание:
- Введение
- Использование ПО при проведении корреляционного анализа
- Задачи корреляционного анализа
- Обследование данных
- Что такое Определение коэффициента корреляции?
- Расчет коэффициента корреляции
- 3) уравнение линейной регрессии на
- Коэффициент корреляции и ПАММ-счета
- Краткий обзор ковариации, корреляции и причинно-следственной связи
- Индекс множественной корреляции
- Корреляция и диверсификация
- 9.1.3. Простая линейная регрессия
- Как работает функция ПИРСОН в Excel?
- Правила отбора факторов корреляционного анализа
- Значения коэффициента корреляции
- Статистика корреляции и инвестирование
Введение
Чтобы рассчитать коэффициент корреляции, необходимо воспользоваться специальной функцией КОРРЕЛ. Формула содержит аргументы для двух массивов данных, между которыми нужно найти зависимость. Полученный коэффициент корреляции в excel можно расшифровать следующим образом:
- Если значение близко к 1 или -1, то существует сильная прямая или обратная связь между величинами.
- Коэффициент около 0,5 или -0,5 говорит о том, что между массивами слабая взаимосвязь.
- Если получается число близкое к нулю, то величины не связаны между собой.
При этом есть ряд особенностей использования функции КОРРЕЛ:
- Программа не учитывает в расчете пустые ячейки, элементы массива с текстовым форматом и ячейки с логическими операторами. При этом числа в виде текста будут учтены.
- Размеры двух массивов должны быть одинаковыми, в противном случае редактор выдаст ошибку типа Н/Д.
- При корреляционном анализе нельзя использовать пустые столбцы или диапазон с нулевыми значениями.
Использование ПО при проведении корреляционного анализа
Описываемый вид статистической обработки данных может осуществляться с помощью программного обеспечения, в частности, MS Excel. Корреляционный анализ в Excel предполагает вычисление следующих параметров с использованием функций:
1. Коэффициент корреляции определяется с помощью функции КОРРЕЛ (массив1; массив2). Массив1,2 — ячейка интервала значений результативных и факторных переменных.
Линейный коэффициент корреляции также называется коэффициентом корреляции Пирсона, в связи с чем, начиная с Excel 2007, можно использовать функцию ПИРСОН (PEARSON) с теми же массивами.
Графическое отображение корреляционного анализа в Excel производится с помощью панели «Диаграммы» с выбором «Точечная диаграмма».
После указания исходных данных получаем график.
2. Оценка значимости коэффициента парной корреляции с использованием t-критерия Стьюдента. Рассчитанное значение t-критерия сравнивается с табличной (критической) величиной данного показателя из соответствующей таблицы значений рассматриваемого параметра с учетом заданного уровня значимости и числа степеней свободы. Эта оценка осуществляется с использованием функции СТЬЮДРАСПОБР (вероятность; степени_свободы).
3. Матрица коэффициентов парной корреляции. Анализ осуществляется с помощью средства «Анализ данных», в котором выбирается «Корреляция». Статистическую оценку коэффициентов парной корреляции осуществляют при сравнении его абсолютной величины с табличным (критическим) значением. При превышении расчетного коэффициента парной корреляции над таковым критическим можно говорить, с учетом заданной степени вероятности, что нулевая гипотеза о значимости линейной связи не отвергается.
Задачи корреляционного анализа
Исходя из приведенных выше определений, можно сформулировать следующие задачи описываемого метода: получить информацию об одной из искомых переменных с помощью другой; определить тесноту связи между исследуемыми переменными.
Корреляционный анализ предполагает определение зависимости между изучаемыми признаками, в связи с чем задачи корреляционного анализа можно дополнить следующими:
- выявление факторов, оказывающих наибольшее влияние на результативный признак;
- выявление неизученных ранее причин связей;
- построение корреляционной модели с ее параметрическим анализом;
- исследование значимости параметров связи и их интервальная оценка.
Обследование данных
Когда вы сталкиваетесь с новым набором данных, первая задача состоит в том, чтобы его обследовать с целью понять, что именно он содержит.
Файл all-london-2012-athletes.tsv достаточно небольшой. Мы можем обследовать данные при помощи pandas, как мы делали в первой серии постов «Python, исследование данных и выборы», воспользовавшись функцией :
Если выполнить этот пример в консоли интерпретатора Python либо в блокноте Jupyter, то вы должны увидеть следующий ниже результат:
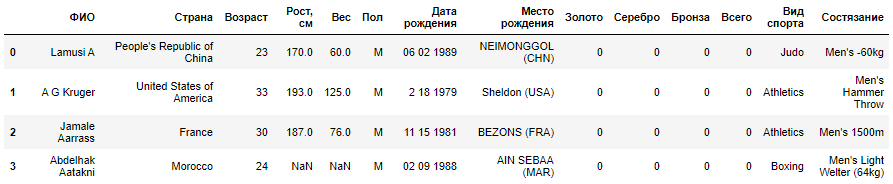
Столбцы данных (нам повезло, что они ясно озаглавлены) содержат следующую информацию:
-
ФИО атлета
-
страна, за которую он выступает
-
возраст, лет
-
рост, см.
-
вес, кг.
-
пол «М» или «Ж»
-
дата рождения в виде строки
-
место рождения в виде строки (со страной)
-
число выигранных золотых медалей
-
число выигранных серебряных медалей
-
число выигранных бронзовых медалей
-
всего выигранных золотых, серебряных и бронзовых медалей
-
вид спорта, в котором он соревновался
-
состязание в виде списка, разделенного запятыми
Даже с учетом того, что данные четко озаглавлены, очевидно присутствие пустых мест в столбцах с ростом, весом и местом рождения
При наличии таких данных следует проявлять осторожность, чтобы они не сбили с толку
Визуализация данных
В первую очередь мы рассмотрим разброс роста спортсменов на Олимпийских играх 2012 г. в Лондоне. Изобразим эти значения роста в виде гистограммы, чтобы увидеть характер распределения данных, не забыв сначала отфильтровать пропущенные значения:
Этот пример сгенерирует следующую ниже гистограмму:
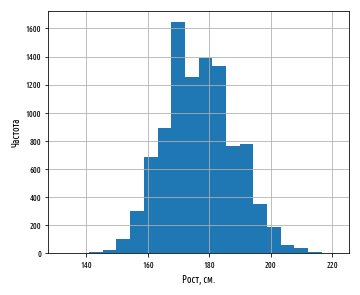
Как мы и ожидали, данные приближенно нормально распределены. Средний рост спортсменов составляет примерно 177 см. Теперь посмотрим на распределение веса олимпийских спортсменов:
Приведенный выше пример сгенерирует следующую ниже гистограмму:
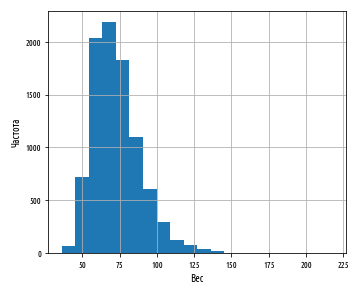
Данные показывают четко выраженную асимметрию. Хвост с правой стороны намного длиннее, чем с левой, и поэтому мы говорим, что асимметрия — положительная. Мы можем оценить асимметрию данных количественно при помощи функции библиотеки pandas :
К счастью, эта асимметрия может быть эффективным образом смягчена путем взятия логарифма веса при помощи функции библиотеки numpy :
Этот пример сгенерирует следующую ниже гистограмму:
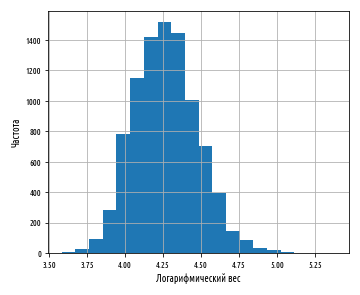
Теперь данные намного ближе к нормальному распределению. Из этого следует, что вес распределяется согласно логнормальному распределению.
Что такое Определение коэффициента корреляции?
Коэффициент корреляции – это статистическая мера силы взаимосвязи между относительными движениями двух переменных. Диапазон значений от -1,0 до 1,0. Расчетное число больше 1,0 или меньше -1,0 означает, что при измерении корреляции произошла ошибка. Корреляция -1,0 показывает идеальную отрицательную корреляцию, а корреляция 1,0 показывает идеальную положительную корреляцию. Корреляция 0,0 показывает отсутствие линейной зависимости между движением двух переменных.
Статистику корреляции можно использовать в финансах и инвестировании. Например, коэффициент корреляции может быть рассчитан для определения уровня корреляции между ценой на сырую нефть и ценой акций нефтедобывающей компании, такой как Exxon Mobil Corporation. Поскольку нефтяные компании получают большую прибыль по мере роста цен на нефть, корреляция между двумя переменными очень положительная.
Расчет коэффициента корреляции
Разберем расчёт на нескольких образцах. К примеру, есть табличные данные, где по месяцам описаны в отдельных столбцах траты на рекламное продвижение и объём продаж. Исходя из таблицы, будем выяснять уровень зависимости объема продаж от денег, затраченных на рекламное продвижение.
Способ 1: определение корреляции через Мастер функций
КОРРЕЛ – функция, позволяющая реализовать корреляционный анализ. Общий вид – КОРРЕЛ(массив1;массив2). Подробная инструкция:
- Необходимо произвести выделение ячейки, в которой планируется выводить итог расчета. Нажать «Вставить функцию», находящуюся слева от текстового поля для ввода формулы.
 1
1
- Открывается «Мастер функций». Здесь необходимо найти КОРРЕЛ, кликнуть на нее, затем на «ОК».
 2
2
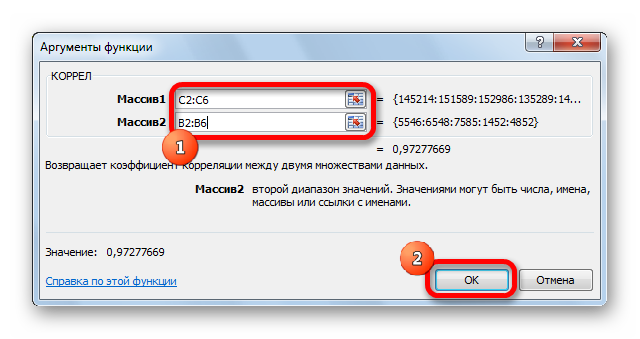
- Открылось окошко аргументов. В строку «Массив1» необходимо ввести координаты интервалы 1-го из значений. В рассматриваемом примере — это столбец «Величина продаж». Нужно просто произвести выделение всех ячеек, которые находятся в этой колонке. В строку «Массив2» аналогично необходимо добавить координаты второй колонки. В рассматриваемом примере — это столбец «Затраты на рекламу».
 3
3
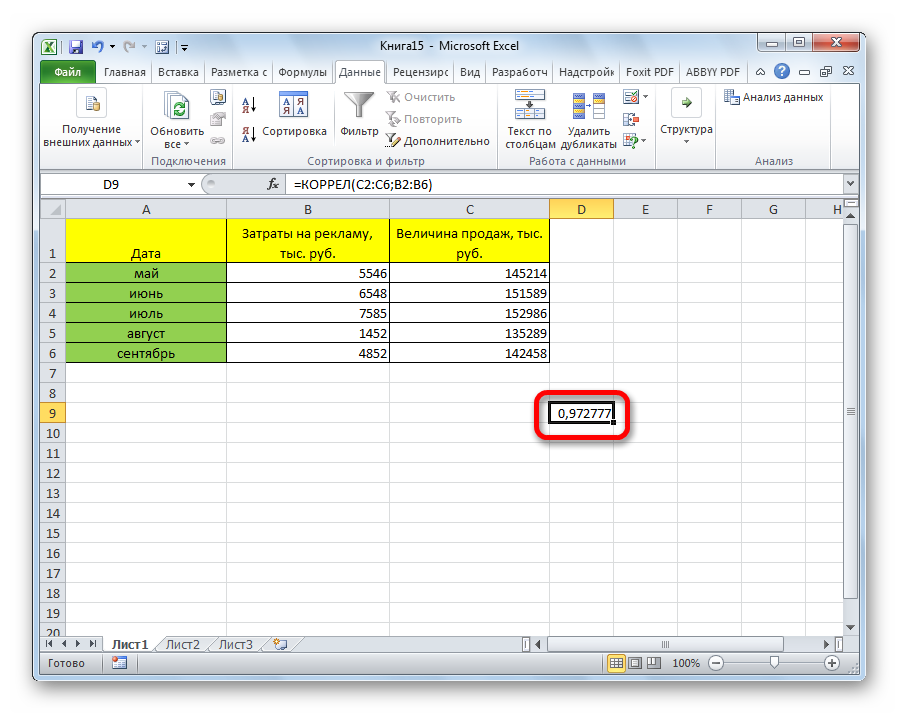
- После введения всех диапазонов кликаем на кнопку «ОК».
Коэффициент отобразился в той ячейке, которая была указана в начале наших действий. Полученный результат 0,97. Этот показатель отображает высокую зависимость первой величины от второй.
 4
4
Способ 2: вычисление корреляции с помощью Пакета анализа
Существует еще один метод определения корреляции. Здесь используется одна из функций, находящаяся в пакете анализа. Перед ее использованием нужно провести активацию инструмента. Подробная инструкция:
- Переходим в раздел «Файл».
 5
5
- Открылось новое окошко, в котором нужно кликнуть на раздел «Параметры».
- Жмём на «Надстройки».
- Находим в нижней части элемент «Управление». Здесь необходимо выбрать из контекстного меню «Надстройки Excel» и кликнуть «ОК».
 6
6
- Открылось специальное окно надстроек. Ставим галочку рядом с элементом «Пакет анализа». Кликаем «ОК».
- Активация прошла успешно. Теперь переходим в «Данные». Появился блок «Анализ», в котором необходимо кликнуть «Анализ данных».
- В новом появившемся окошке выбираем элемент «Корреляция» и жмем на «ОК».
 7
7
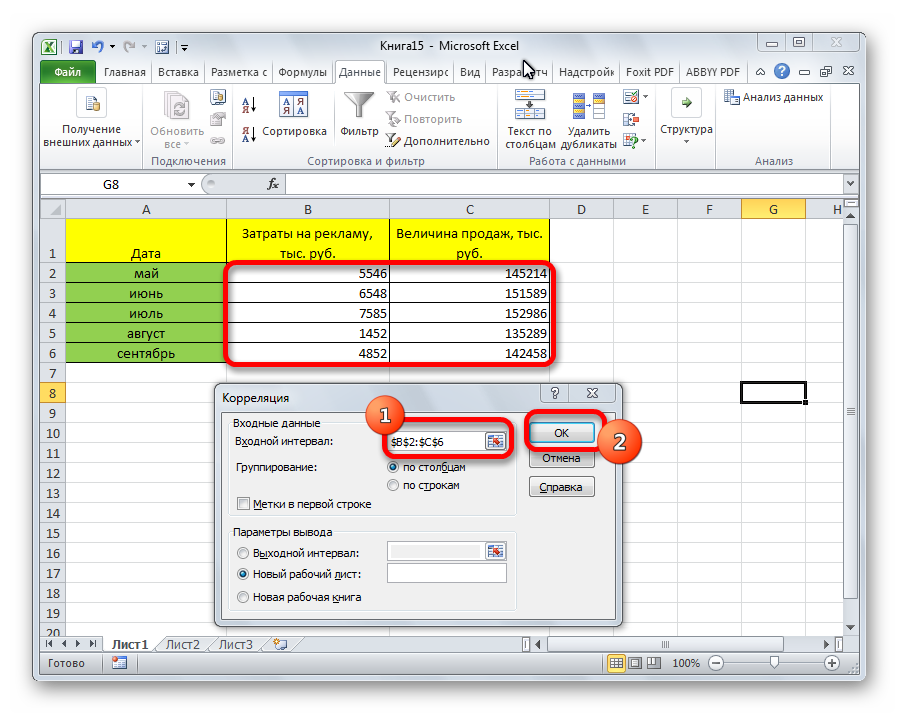
- На экране появилось окошко настроек анализа. В строчку «Входной интервал» необходимо ввести диапазон абсолютно всех колонок, принимающих участие в анализе. В рассматриваемом примере — это столбики «Величина продаж» и «Затраты на рекламу». В настройках отображения вывода изначально выставлен параметр «Новый рабочий лист», что означает показ результатов на другом листе. По желанию можно поменять локацию вывода результата. После проведения всех настроек нажимаем на «ОК».
 8
8
Вывелись итоговые показатели. Результат такой же, как и в первом методе – 0,97.
3) уравнение линейной регрессии на
Это и есть та самая оптимальная прямая , которая проходит максимально близко ко всем точкам. Обычно её находят методом наименьших квадратов, и мы пойдём знакомым путём
Заполним расчётную таблицу:
Обратите внимание, что в отличие от задач урока МНК у нас появился дополнительный столбец , он потребуется в дальнейшем, для расчёта коэффициента корреляции
Сократим оба уравнения на 2, всё попроще будет:
Систему решим по формулам Крамера: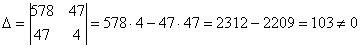 , значит, система имеет единственное решение.
, значит, система имеет единственное решение.

Таким образом, искомое уравнение регрессии:
Данное уравнение показывает, что с увеличением количества прогулов («икс») на 1 единицу суммарная успеваемость падает в среднем на 6,0485 (коэффициент «а») – примерно на 6 баллов.
Почему это регрессия именно « на » и о происхождении самого термина «регрессия» я рассказал чуть ранее, в параграфе . Если кратко, то полученные с помощью уравнения средние значения успеваемости («игреки») регрессивно возвращают нас к первопричине – количеству прогулов.
Найдём пару удобных точек для построения прямой:
отметим их на чертеже (малиновый цвет) и проведём линию регрессии: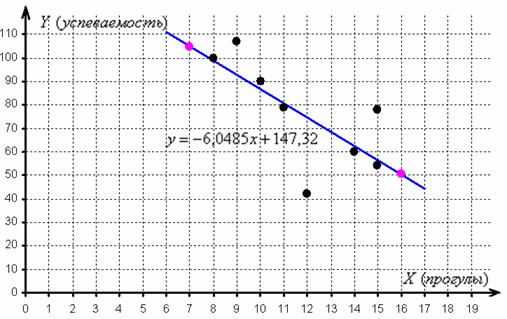
Говорят, что уравнение регрессии аппроксимирует (приближает) эмпирические данные (точки), и с помощью него можно интерполировать (восстановить) неизвестные промежуточные значения, так при количестве прогулов среднеожидаемая успеваемость составит балла.
И, конечно, осуществимо прогнозирование, так при среднеожидаемая успеваемость составит баллов. Единственное, нежелательно брать «иксы», которые расположены слишком далеко от эмпирических точек, поскольку прогноз, скорее всего, не будет соответствовать действительности. Например, при значение может вообще оказаться невозможным, ибо у успеваемости есть свой фиксированный «потолок». И, разумеется, «икс» или «игрек» в нашей задаче не могут быть отрицательными.
Второй вопрос касается тесноты зависимости. Очевидно, что чем ближе расположены эмпирические точки к прямой, тем теснее зависимость – тем уравнение регрессии достовернее отражает ситуацию, и тем качественнее полученная модель. И наоборот, если многие точки разбросаны вдали от прямой, то признак зависит от вовсе не линейно (если вообще зависит) и линейная функция плохо отражает реальную картину.
Прояснить данный вопрос нам поможет:
Коэффициент корреляции и ПАММ-счета
С расчётом корреляции я как студент экономического ВУЗа познакомился еще на втором курсе
Тем не менее, долгое время недооценивал важность расчёта корреляции именно для подбора ПАММ-портфеля. 2018 год очень четко показал, что ПАММ-счета с похожими стратегиями в случае кризиса могут вести себя очень похоже
Случилось так, что с середины года отказала не просто одна стратегия управляющего, а большинство торговых систем, завязанных на активные движения валютной пары EUR/USD:

Рынок был для каждого управляющего по-своему неблагоприятным, но присутствие их всех в портфеле привело к большой просадке. Совпадение? Не совсем, ведь это были ПАММ-счета с похожими элементами в торговых стратегиях. Без опыта торговли на рынке Форекс может быть сложно понять, как это работает, но по корреляционной таблице степень взаимосвязи видна и так:

Мы ранее рассматривали корреляцию вплоть до +1, но как видите на практике даже совпадение в районе 20-30% уже говорит о некоторой схожести ПАММ-счетов и, как следствие, результатов торговли.
Чтобы снизить шансы на повторение ситуации, как в 2018 году, я считаю в портфель стоит подбирать ПАММ-счета с низкой взаимной корреляцией. По сути, нам нужны уникальные стратегии с разными подходами и разными валютными парами для торговли. На практике, конечно, сложнее подобрать прибыльные счета с уникальными стратегиями, но если хорошо покопаться в рейтинге ПАММ-счетов, то все возможно. К тому же, низкая взаимная корреляция снижает требования для диверсификации, 5-6 счетов вполне хватит.
Пару слов о расчёте коэффициента корреляции для ПАММ-счетов. Достать сами данные относительно несложно, в Альпари прямо с сайта, для остальных площадок через сайт investflow.ru. Однако с ними нужно сделать небольшие преобразования.
Данные о прибыльности ПАММов изначально хранятся в формате накопленной доходности, нам это не подходит. Корреляция стандартных графиков доходности двух прибыльных ПАММ-счетов всегда будет очень высокой, просто потому что они все движутся в правый верхний угол:

У всех счетов положительная корреляция от 0.5 и выше за редким исключением, так мы ничего не поймем. Реальное сходство стратегий ПАММ-счетов можно увидеть только по дневным доходностям. Рассчитать их не особо сложно, если знаете нужные формулы доходности. Если прибыль или убыток двух ПАММ-счетов совпадают по дням и по процентам, высока вероятность что их стратегии имеют общие элементы — и коэффициент корреляции нам это покажет:

Как видите, некоторые корреляции стали нулевыми, а некоторые остались на высоком уровне. Мы теперь видим, какие ПАММ-счета действительно похожи между собой, а какие не имеют ничего общего.
Напоследок давайте разберёмся, что делать и как посчитать корреляцию, если у вас появилась в этом необходимость.
Краткий обзор ковариации, корреляции и причинно-следственной связи
В предыдущей статье мы обсудили ковариацию, корреляцию и причинно-следственную связь.
- Дисперсия количественно определяет мощность случайных отклонений в наборе данных.
- Ковариация количественно определяет взаимосвязь между отклонениями в двух отдельных наборах данных. Более конкретно, она фиксирует склонность значений в двух наборах данных к изменению вместе (то есть к совместному изменению) линейным образом.
- Ковариация измеряет корреляцию двух переменных.
- Корреляция не доказывает причинно-следственную связь – если две переменные коррелированы, мы не можем автоматически сделать вывод, что изменения в одной переменной вызывают изменения в другой переменной. Тем не менее, если мы подозреваем наличие причинно-следственной связи и можем продемонстрировать корреляцию, у нас есть веские основания для дальнейшего изучения возможности причинной связи путем сбора дополнительных данных или проведения новых экспериментов.
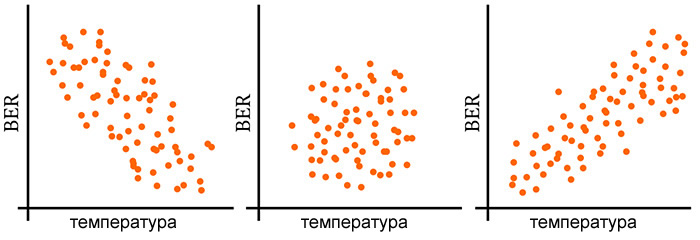 Рисунок 1 – Примеры из предыдущей статьи отрицательной корреляции (слева), отсутствия корреляции (в центре) и положительной корреляции (справа). BER означает коэффициент битовых ошибок.
Рисунок 1 – Примеры из предыдущей статьи отрицательной корреляции (слева), отсутствия корреляции (в центре) и положительной корреляции (справа). BER означает коэффициент битовых ошибок.
Индекс множественной корреляции
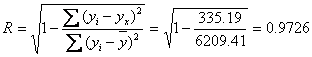 22табл
22табл
4. Оценка значения результативного признака при заданных значениях факторов. Y(0.0,0.0,) = -32.24 + 0.2412 * 0.0 + 0.1151 * 0.0 = -32.24
Доверительные интервалы с вероятностью 0.95 для индивидуального значения результативного признака. S2 =
XT(XTX)-1Xгде XT =
(XTX)-1
| 5.8295 | -0.0116 | -0.0002 |
| -0.0116 | 0.0001 | -0 |
| -0.0002 | -0 |
2YY
5. Проверка гипотез относительно коэффициентов уравнения регрессии (проверка значимости параметров множественного уравнения регрессии).
1) t-статистика Статистическая значимость коэффициента регрессии b подтверждается
Статистическая значимость коэффициента регрессии b1 подтверждается Статистическая значимость коэффициента регрессии b2 подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими: (bi — t i Si; bi + t i S i) b : (-44.2749;-20.2039)
b 1: (0.204;0.2784) b 2: (0.0887;0.1415)
2) F-статистика. Критерий Фишера Fkp = 4.35 Поскольку F > Fkp, то коэффициент детерминации статистически значим и уравнение регрессии статистически надежно
6. Проверка на наличие гетероскедастичности методом графического анализа остатков. В этом случае по оси абсцисс откладываются значения объясняющей переменной Xi, а по оси ординат квадраты отклонения ei2.
| y | y(x) | e=y-y(x) | e2 |
| 130.34 | 131.53 | -1.19 | 1.43 |
| 126.83 | 132.94 | -6.11 | 37.35 |
| 108.61 | 105.5 | 3.11 | 9.67 |
| 116.01 | 112.67 | 3.34 | 11.16 |
| 135.44 | 132.68 | 2.76 | 7.63 |
| 142.88 | 149.54 | -6.66 | 44.39 |
| 158.69 | 151.81 | 6.88 | 47.28 |
| 168.49 | 170.91 | -2.42 | 5.87 |
| 174.8 | 178.48 | -3.68 | 13.56 |
| 187.15 | 174.63 | 12.52 | 156.86 |
Корреляция и диверсификация
Как знания о корреляции активов могут помочь лучше вкладывать деньги? Думаю, вы все хорошо знакомы с золотым правилом инвестора — не клади все яйца в одну корзину. Речь, естественно, идёт о диверсификации инвестиционных активов в портфеле. Корреляция и диверсификация неразрывно связаны, что понятно даже из названия — английское diversify означает «разнообразить», а как коэффициент корреляции как раз показывает схожесть или различие двух явлений.
Другими словами, инвестировать в финансовые инструменты с высокой корреляцией не очень хорошо. Почему? Все просто — похожие активы плохо диверсифицируются. Вот пример портфеля двух активов с корреляцией +1:

Как видите, график портфеля во всех деталях повторяет графики каждого из активов — рост и падение обоих активов синхронны. Диверсификация в теории должна снижать инвестиционные риски за счёт того, что убытки одного актива перекрываются за счёт прибыли другого, но здесь этого не происходит совершенно. Все показатели просто усредняются:

Портфель даёт небольшой выигрыш в снижении рисков — но только по сравнению с более доходным Активом 1. А так, никаких преимуществ по сути нет, нам лучше просто вложить все деньги в Актив 1 и не париться.
А вот пример портфеля двух активов с корреляцией близкой к 0:

Где-то графики следуют друг за другом, где-то в противоположных направлениях, какой-либо однозначной связи не наблюдается. И вот здесь диверсификация уже работает:

Мы видим заметное снижение СКО, а значит портфель будет менее волатильным и более стабильно расти. Также видим небольшое снижение максимальной просадки, особенно если сравнивать с Активом 1. Инвестиционные инструменты без корреляции достаточно часто встречаются и из них имеет смысл составлять портфель.
Впрочем, это не предел. Наиболее эффективный инвестиционный портфель можно получить, используя активы с корреляцией -1:

Уже знакомое вам «зеркало» позволяет довести показатели риска портфеля до минимальных:
Несмотря на то, что каждый из активов обладает определенным риском, портфель получился фактически безрисковым. Какая-то магия, не правда ли? Очень жаль, но на практике такого не бывает, иначе инвестирование было бы слишком лёгким занятием.
9.1.3. Простая линейная регрессия
Применение линейного регрессионного анализа имеет специфические черты по сравнению с другими методами обработки данных. Его непосредственное употребление ограничено, в основном, задачами о предсказании значений зависимой переменной по известным значениям аргумента (или аргументов), что в психологии задача не слишком востребованная. Однако, во-первых, линейная регрессия входит как часть во многие другие методы (например, анализ медиации и модерации, о которых речь пойдет в следующей главе), и, во-вторых, служит простым примером отыскания наилучших параметров для модели определенного типа, и психологу полезно понимать суть этого метода. Качество каждого набора параметров, а затем и модели в целом, оценивается процентом дисперсии, который остался вне предсказаний, сделанных моделью по данным значениям аргументов. Замечательным результатом для читателя будет здесь улавливание аналогий с двухфакторным дисперсионным анализом.
Как работает функция ПИРСОН в Excel?
Рассмотрим пример расчета корреляции Пирсона между двумя массивами данных при помощи функции PEARSON в MS EXCEL. Первый массив представляет собой значения температур, второй давление в определенный летний период. Пример заполненной таблицы изображен на рисунке:

Пример решения с функцией ПИРСОН при анализе в Excel
- Выберем ячейку С17 в которой должен будет посчитаться критерий Пирсона как результат и нажмем кнопку мастер функций «fx» или комбинацию горячих клавиш (SHIFT+F3). Откроется мастер функций, в поле Категория необходимо выбрать «Статистические». В списке статистических функций выбрать PEARSON и нажать Ok:

В меню аргументов выбрать Массив 1, в примере это утренняя температура воздуха, а затем массив 2 – атмосферное давление.

В результате в ячейке С17 получим коэффициент корреляции Пирсона. В нашем случае он отрицательный и приблизительно равен -0,14.

Данный показатель -0,14 по Пирсону, который вернула функция, говорит об неблагоприятной зависимости температуры и давления в раннее время суток.
Правила отбора факторов корреляционного анализа
При применении данного метода необходимо определиться с факторами, оказывающими влияние на результативные показатели. Их отбирают с учетом того, что между показателями должны присутствовать причинно-следственные связи. В случае создания многофакторной корреляционной модели отбирают те из них, которые оказывают существенное влияние на результирующий показатель, при этом взаимозависимые факторы с коэффициентом парной корреляции более 0,85 в корреляционную модель предпочтительно не включать, как и такие, у которых связь с результативным параметром носит непрямолинейный или функциональный характер.
Значения коэффициента корреляции
Охарактеризовать силу корреляционной связи можно прибегнув к шкале Челдока, в которой определенному числовому значению соответствует качественная характеристика.

- 0-0,3 – корреляционная связь очень слабая;
- 0,3-0,5 – слабая;
- 0,5-0,7 – средней силы;
- 0,7-0,9 – высокая;
- 0,9-1 – очень высокая сила корреляции.
Шкала может использоваться и для отрицательной корреляции. В этом случае качественные характеристики заменяются на противоположные.
Можно воспользоваться упрощенной шкалой Челдока, в которой выделяется всего 3 градации силы корреляционной связи:
- очень сильная – показатели ±0,7 — ±1;
- средняя – показатели ±0,3 — ±0,699;
- очень слабая – показатели 0 — ±0,299.
Данный статистический показатель позволяет не только проверить предположение о существовании линейной взаимосвязи между признаками, но и установить ее силу.
История разработки критерия корреляции
Критерий корреляции Пирсона был разработан командой британских ученых во главе с Карлом Пирсоном (1857-1936) в 90-х годах 19-го века, для упрощения анализа ковариации двух случайных величин. Помимо Карла Пирсона над критерием корреляции Пирсона работали также Фрэнсис Эджуорт и Рафаэль Уэлдон.
Для чего используется критерий корреляции Пирсона?
Критерий корреляции Пирсона позволяет определить, какова теснота (или сила) корреляционной связи между двумя показателями, измеренными в количественной шкале. При помощи дополнительных расчетов можно также определить, насколько статистически значима выявленная связь.
Например, при помощи критерия корреляции Пирсона можно ответить на вопрос о наличии связи между температурой тела и содержанием лейкоцитов в крови при острых респираторных инфекциях, между ростом и весом пациента, между содержанием в питьевой воде фтора и заболеваемостью населения кариесом.
Условия и ограничения применения критерия хи-квадрат Пирсона
- Сопоставляемые показатели должны быть измерены в количественной шкале (например, частота сердечных сокращений, температура тела, содержание лейкоцитов в 1 мл крови, систолическое артериальное давление).
- Посредством критерия корреляции Пирсона можно определить лишь наличие и силу линейной взаимосвязи между величинами. Прочие характеристики связи, в том числе направление (прямая или обратная), характер изменений (прямолинейный или криволинейный), а также наличие зависимости одной переменной от другой – определяются при помощи регрессионного анализа.
- Количество сопоставляемых величин должно быть равно двум. В случае анализ взаимосвязи трех и более параметров следует воспользоваться методом факторного анализа.
- Критерий корреляции Пирсона является параметрическим, в связи с чем условием его применения служит нормальное распределение каждой из сопоставляемых переменных. В случае необходимости корреляционного анализа показателей, распределение которых отличается от нормального, в том числе измеренных в порядковой шкале, следует использовать коэффициент ранговой корреляции Спирмена.
- Следует четко различать понятия зависимости и корреляции. Зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
Например, рост ребенка зависит от его возраста, то есть чем старше ребенок, тем он выше. Если мы возьмем двух детей разного возраста, то с высокой долей вероятности рост старшего ребенка будет больше, чем у младшего. Данное явление и называется зависимостью, подразумевающей причинно-следственную связь между показателями. Разумеется, между ними имеется и корреляционная связь, означающая, что изменения одного показателя сопровождаются изменениями другого показателя.
В другой ситуации рассмотрим связь роста ребенка и частоты сердечных сокращений (ЧСС). Как известно, обе эти величины напрямую зависят от возраста, поэтому в большинстве случаев дети большего роста (а значит и более старшего возраста) будут иметь меньшие значения ЧСС. То есть, корреляционная связь будет наблюдаться и может иметь достаточно высокую тесноту. Однако, если мы возьмем детей одного возраста, но разного роста, то, скорее всего, ЧСС у них будет различаться несущественно, в связи с чем можно сделать вывод о независимости ЧСС от роста.
Приведенный пример показывает, как важно различать фундаментальные в статистике понятия связи и зависимости показателей для построения верных выводов
Статистика корреляции и инвестирование
Корреляция между двумя переменными особенно полезна при инвестировании на финансовых рынках. Например, корреляция может быть полезна при определении того, насколько хорошо взаимный фонд работает по сравнению с его эталонным индексом или другим фондом или классом активов. Добавляя паевой инвестиционный фонд с низкой или отрицательной корреляцией к существующему портфелю, инвестор получает выгоду от диверсификации .
Другими словами, инвесторы могут использовать активы или ценные бумаги с отрицательной корреляцией для хеджирования своего портфеля и снижения рыночного риска из-за волатильности или резких колебаний цен. Многие инвесторы хеджируют ценовой риск портфеля, что эффективно снижает любой прирост капитала или убытки, потому что они хотят дивидендного дохода или доходности от акций или ценных бумаг.
Статистика корреляции также позволяет инвесторам определять, когда изменяется корреляция между двумя переменными. Например, акции банка обычно имеют очень положительную корреляцию с процентными ставками, поскольку ставки по кредитам часто рассчитываются на основе рыночных процентных ставок. Если цена акций банка падает, а процентные ставки растут, инвесторы могут понять, что что-то не так. Если цены на акции аналогичных банков в секторе также растут, инвесторы могут сделать вывод, что падение акций банков не связано с процентными ставками. Вместо этого плохо работающий банк, вероятно, имеет дело с внутренней фундаментальной проблемой.