Шпаргалка по регулярным выражениям. в примерах
Содержание:
- Объект RegExp
- Скобочные группы ― ()
- Группировка
- Основы основ
- Практические примеры сложных регулярных выражений
- Строковые методы, поиск и замена
- Описание
- Ещё один реальный пример
- Найти все / Заменить все
- Поиск совпадений: метод exec
- Квантификаторы
- PHP regex extracting matches
- Повторения (квантификаторы)
- Синтаксис регулярных выражений
- Метасимволы
Объект RegExp
Объект типа , или, короче, регулярное выражение, можно создать двумя путями
/pattern/флаги
new RegExp("pattern")
— регулярное выражение для поиска (о замене — позже), а флаги — строка из любой комбинации символов (глобальный поиск), (регистр неважен) и (многострочный поиск).
Первый способ используется часто, второй — иногда. Например, два таких вызова эквивалентны:
var reg = /ab+c/i
var reg = new RegExp("ab+c", "i")
При втором вызове — т.к регулярное выражение в кавычках, то нужно дублировать
// эквивалентны
re = new RegExp("\\w+")
re = /\w+/
При поиске можно использовать большинство возможностей современного PCRE-синтаксиса.
Скобочные группы ― ()
a(bc) создаём группу со значением bc -> тестa(?:bc)* оперетор ?: отключает группу -> тестa(?<foo>bc) так, мы можем присвоить имя группе -> тест
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Если присвоить группам имена (используя ), то можно получить их значения, используя результат сопоставления, как словарь, где ключами будут имена каждой группы.
Группировка
Группы (подмаски) в регулярных выражениях делаются с помощью метасимвола группировки .
Например в выражении xyz+ знак плюс относится только к букве и это выражение ищет слова типа , , . Но если поставить скобки то квантифиактор относится уже к последовательности и регулярка ищет слова , , .
Пример
Попробуй сам
Результат выполнения кода:
1
Ещё примеры:
| Выражение | Описание |
|---|---|
| ^{1,}$ | Любое слово, хотя бы одна буква, число или |
| +@ | Соответствует строке с символом @ в начале, за которым следует любая буква нижнего регистра, число от 0 до 9 или буква верхнего регистра. |
| ()() | wy, wz, xy, или xz |
| + | Один или более символов нижнего регистра |
Практические упражнения по регулярным выражениям PHP.
Назад
Вперёд
Основы основ
Для начала нужно понять что в Regex есть специальные символы (например символ начала строки — ), если вы хотите просто найти данный символ, то нужно ввести обратный слеш перед символом для того, чтобы символ не работал как команда.
Для того чтобы найти текст, нужно собственно просто ввести этот текст:
Якори
— символ который обозначает начало строки
— символ который обозначает конец строки
Найдем строки которые начинаются с The Beginning:
Найдем строки, которые заканчиваются на The End:
Найдем строки, которые начинаются и заканчиваются на The Beginning and The End:
Найдем пустые строки:
Квантификаторы
— символ, который указывает на то, что выражение до него должно встретиться 0 или 1 раз
— символ, который указывает на то, что выражение до него должно встретиться один или больше раз
— символ, который указывает на то, что выражение до него должно встретиться 0 или неопределённое количество раз
— скобки с одним аргументом указывают сколько раз выражение до них должно встретиться
— скобки с двумя аргументами указывают на то, от скольки до скольки раз выражение до них должно встретиться
— скобки объединяют какое-то предложение в выражение. Обычно используется в связке с квантификаторами
Давайте попробуем найти текст, в котором будут искаться все слова, содержащие ext или ex:
Давайте попробуем найти текст, в котором слова будут содержать ext или e:
Найти все размеры одежды (XL, XXL, XXXL):
Найти все слова, у которых есть неограниченное число символов c, после которых идёт haracter:
Найти выражение, в котором слово word повторяется от одного до неограниченного количества раз:
Найти выражение, в котором выражение ch повторяется от 3 до неограниченного количества раз:
Выражение «или»
— символ, который обозначает оператор «или»
— выражение в квадратных скобках ставит или между каждым подвыражением
Найти все слова, в которых есть буквы a,e,c,h,p:
Найти все выражения в которых есть ch или pa:
Escape-последовательности
— отмечает один символ, который является цифрой (digit)\
— отмечает символ, который не является цифрой
— отмечает любой символ (число или букву (или подчёркивание)) (word)
— отмечает любой пробельный символ (space character)
— отмечает любой символ (один)
Выражения в квадратных скобках
Кроме того, что квадратные скобки служат оператором «или» между каждым символом, который в них заключён, они также могут служить и для некоторых перечислений:
— один символ от 0 до 9
— любой символ от a до z
— любой символ от A до Z
— любой символ кроме a — z
Найти все выражения, в которых есть английские буквы в нижнем регистре или цифры:
Флаги
Флаги — символы (набор символов), которые отвечают за то, каким именно образом будет происходить поиск.
Форма условия поиска в Regex выглядит вот так:
— флаг, который будет отмечать все выражения, которые соответствуют условиям поиска (по умолчанию поиск возвращает только первое выражение, которое подходит по условию) (global)
— флаг, который заставляет искать выражения вне зависимости от региста (case insensitive)
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
После этого нам нужно ограничить количество символов следующим кодом:
{4,20}
Теперь собираем это регулярное выражение вместе:
^{4,20}$
В случае Perl-совместимого регулярного выражения заключите его символами ‘‘. Итоговый PHP-код выглядит так:
<?php
$pattern = '/^{4,20}$/';
$username = "demo_user-123";
if (preg_match($pattern, $username)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
2) Проверка шестнадцатеричного кода цвета регулярным выражением
Шестнадцатеричный код цвета выглядит так: , также допустимо использование краткой формы, например . В обоих случаях код цвета начинается с и затем идут ровно 3 или 6 цифр или букв от a до f.
Итак, проверяем начало кода:
^#
Затем проверяем диапазон допустимых символов:
После этого проверяем допустимую длину кода (она может быть либо 3, либо 6). Полный код регулярного выражения выйдет следующим:
^#(({3}$)|({6}$))
Здесь мы используем логический оператор, чтобы сначала проверить код вида , а затем код вида . Итоговый PHP-код проверки регулярным выражением выглядит так:
<?php
$pattern = '/^#(({3}$)|({6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
john.doe@test.com john@demo.ua john_123.doe@test.info
Как мы можем видеть, символ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как . В шаблоне мы можем написать это следующим образом:
^+
Доменное имя всегда имеет, скажем, имя и tld (top-level domain) – т.е, доменную зону. Доменная зона – это , , и тому подобное. Это означает, что шаблон регулярного выражения для домена будет выглядеть так:
+\.{2,5}$
Теперь, если мы соберем все в кучу, то получим полный шаблон регулярного выражения для проверки адреса электронной почты:
^+@+\.{2,5}$
В коде PHP эта проверка будет выглядеть следующим образом:
<?php
$pattern = '/^+@+\.{2,5}$/';
$email = "john_123.doe@test.info";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
-
3633
-
35
-
Опубликовано 16/04/2019
-
PHP, Уроки программирования
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Описание
int preg_match_all (string pattern, string subject, array matches )
Ищет в subject все совпадения с регулярным выражением pattern и помещает их в
matches в порядке, специфицированном в order.
После нахождения первого совпадения последующий поиск продолжается до нахождения последнего совпадения.
flags может быть комбинацией следующих флагов (обратите внимание, что нет смысла использовать
PREG_PATTERN_ORDER вместе с PREG_SET_ORDER):
- PREG_PATTERN_ORDER
-
Упорядочивает результаты таким образом, что $matches это массив
полных совпадений с патэрном, $matches это массив строк, совпавших с первым субпатэрном в скобках, и так далее.preg_match_all ("|<+>(.*)</+>|U", "<b>example: </b><div align=left>this is a test</div>", $out, PREG_PATTERN_ORDER); print $out.", ".$out." "; print $out.", ".$out." ";Этот пример выдаст:
<b>example: </b>, <div align=left>this is a test</div> example: , this is a test
Итак, $out содержит массив строк, совпавших со всем патэрном, а $out содержит массив строк, заключённых в тэги.
- PREG_SET_ORDER
-
Упорядочивает результаты таким образом, что $matches это массив
первого набора совпадений, $matches это массив второго набора совпадений, и так далее.preg_match_all ("|<+>(.*)</+>|U", "<b>example: </b><div align=left>this is a test</div>", $out, PREG_SET_ORDER); print $out.", ".$out." "; print $out.", ".$out." ";Этот пример выдаст:
<b>example: </b>, example: <div align=left>this is a test</div>, this is a test
В данном случае $matches это первый набор совпадений, а $matches содержит текст, совпавший с полным патэрном, $matches
содержит текст, совпавший с первым субпатэрном, и так далее. Аналогично $matches это второй набор совпадений, etc. - PREG_OFFSET_CAPTURE
-
Если этот флаг установлен, для каждого возникшего совпадения будет
возвращено дополнительное строковое смещение. Заметьте, что это изменяет return-значение
в массиве, где каждый элемент является массивом, состоящим из совпавшей
строки в смещении 0 и её строкового смещения в subject — в смещении 1.
Этот флаг доступен, начиная с PHP 4.3.0.
Если никакой флаг упорядочивания не задан, принимается PREG_PATTERN_ORDER.
Возвращает количество полных совпадений с патэрном (это может быть нуль), или FALSE при ошибке.
|
Пример 2. Поиск совпадений с HTML-тэгами (greedy/жадный)
|
Этот пример выдаст:
matched: <b>bold text</b> part 1: <b> part 2: bold text part 3: </b> matched: <a href=howdy.php>click me</a> part 1: <a href=howdy.php> part 2: click me part 3: </a> |
См. также preg_match(),
preg_replace()
и preg_split().
Ещё один реальный пример
Практически на любом современном сайте все адреса вида: https://php.zone/post/892
Эти адреса нужно обрабатывать прямо в коде, и понимать, что показать пользователю. Это называется «роутинг» — специальные правила, по которым нужно преобразовать адрес, по которому пришел пользователь, в конкретное действие на стороне сервера. То есть получив адрес вида /post/892 ваш код должен понять, что:
- это post, то есть статья
- идентификатор этой статьи — 892
Дальше он ищет статью в базе данных с таким идентификатором и возвращает её пользователю.
Вопрос: как это сделать? Да проще простого! Создать список шаблонов для всех страниц сайта. И когда прилетает запрос на /post/+ — то искать статью с каким-то идентификатором. Да, да, вы уже догадались, сделать это можно с помощью регулярок. И это будет вашим домашним заданием.
Найти все / Заменить все
Эти две задачи решаются в javascript принципиально по-разному.
Начнём с «простого».
Для замены всех вхождений используется метод String#replace.
Он интересен тем, что допускает первый аргумент – регэксп или строку.
Если первый аргумент – строка, то будет осуществлён поиск подстроки, без преобразования в регулярное выражение.
Попробуйте:
Как видите, заменился только один плюс, а не оба.
Чтобы заменить все вхождения, String#replace обязательно нужно использовать с регулярным выражением.
В режиме регулярного выражения плюс придётся экранировать, но зато заменит все вхождения (при указании флага ):
Вот такая особенность работы со строкой.
Очень полезной особенностью является возможность работать с функцией вместо строки замены. Такая функция получает первым аргументом – все совпадения, а последующими аргументами – скобочные группы.
Следующий пример произведёт операции вычитания:
В javascript нет одного универсального метода для поиска всех совпадений.
Для поиска без запоминания скобочных групп – можно использовать String#match:
Как видите, оно исправно ищет все совпадения (флаг у регулярного выражения обязателен), но при этом не запоминает скобочные группы. Эдакий «облегчённый вариант».
В сколько-нибудь сложных задачах важны не только совпадения, но и скобочные группы. Чтобы их найти, предлагается использовать многократный вызов RegExp#exec.
Для этого регулярное выражение должно использовать флаг . Тогда результат поиска, запомненный в свойстве объекта используется как точка отсчёта для следующего поиска:
Проверка нужна т.к. значение является хорошим и означает, что вхождение найдено в самом начале строки (поиск успешен). Поэтому необходимо сравнивать именно с .
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Квантификаторы
А теперь, допустим мы хотим найти совпадения по маске «ку***» — «ку» и три любых символа. Да пожалуйста: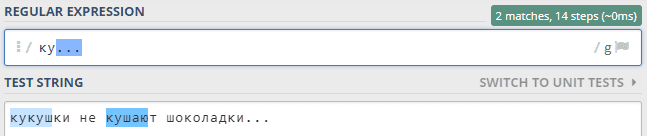
Однако, для таких случаев принято использовать квантификаторы — это такие конструкции в регулярных выражениях, которые позволяют задать число символов, стоящих перед ними.
Для этого используются 2 числа в фигурных скобках. {ОТ, ДО} — от скольки повторений и до скольки.
Например, мы хотим найти в тексте все комбинации точек, идущих друг за другом, в количестве от одной до трёх. Тогда наш паттерн примет следующий вид: «.{1,3}» — символ точки, повторяющийся от одного до трех раз.
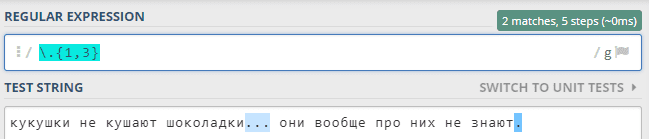
Если что-то должно повториться точное число раз, например, 3, то пишется просто {3}.
Есть также квантификаторы, которые используются чаще других и для них сделаны специальные символы:
- ? (знак вопроса) — предшествующий символ либо есть, либо его может не быть. Аналог — {0, 1}.
Немного примеров:
Символ точки, повторяющийся от одного и более раз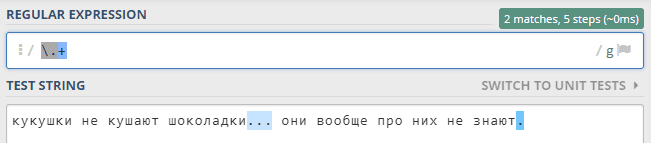
Восклицательный знак, перед которым либо есть вопросительный знак, либо нет
PHP regex extracting matches
The takes an optional third parameter.
If it is provided, it is filled with the results of the search.
The variable is an array whose first element contains the text that
matched the full pattern, the second element contains
the first captured parenthesized subpattern, and so on.
extract_matches.php
<?php
$times = ;
$pattern = "/(\d\d):(\d\d):(\d\d)/";
foreach ($times as $time) {
$r = preg_match($pattern, $time, $match);
if ($r) {
echo "The $match is split into:\n";
echo "Hour: $match\n";
echo "Minute: $match\n";
echo "Second: $match\n";
}
}
In the example, we extract parts of a time string.
$times = ;
We have three time strings in English locale.
$pattern = "/(\d\d):(\d\d):(\d\d)/";
The pattern is divided into three subpatterns using square
brackets. We want to refer specifically to exactly to
each of these parts.
$r = preg_match($pattern, $time, $match);
We pass a third parameter to the
function. In case of a match, it contains text parts of
the matched string.
if ($r) {
echo "The $match is split into:\n";
echo "Hour: $match\n";
echo "Minute: $match\n";
echo "Second: $match\n";
}
The contains the text that matched the full
pattern, contains text that matched the first
subpattern, the second, and
the third.
$ php extract_matches.php The 10:10:22 is split into: Hour: 10 Minute: 10 Second: 22 The 23:23:11 is split into: Hour: 23 Minute: 23 Second: 11 The 09:06:56 is split into: Hour: 09 Minute: 06 Second: 56
This is the output of the example.
Повторения (квантификаторы)
Комбинация типа означает, что цифра должна повторяться два раза. Но бывают задачи, когда повторений очень много или мы не знаем, сколько именно. В таких члучаях нужно использовать специальные метасимволы.
Повторения символов или комбинаций описываются с помощью квантификаторов (метасимволов, которые задают количественные отношения). Есть два типа квантификаторов: общие (задаются с помощью фигурных скобок ) и сокращенные (сокращения наиболее распространенных квантификаторов). Фигурные скобки задают число повторений предыдущего символа (в этом случае выражение ищет от 1 до 7 идущих подряд букв «x»).
| Квантификатор | Описанте |
|---|---|
| a+ | Один и более раз a |
| a* | Ноль и более раз a |
| a? | Одна a или пусто |
| a{3} | 3 раза a |
| a{3,5} | От 3 до 5 раз a |
| a{3,} | 3 и более раз a |
Примечание: Если в выражении требуется поиск одного из метасимволов, вы можете использовать обратный слэш . Например, для поиска одного или нескольких вопросительных знаков можно использовать следующее выражение:
Синтаксис регулярных выражений
Регулярное выражение представляет собой строку, которая всегда начинается с символа разделителя, за ним следует шаблон регулярного выражения, затем еще один символ разделителя и, наконец, необязятельный список модификаторов.
$exp = "/wm-school/i";
В приведенном выше примере, в качестве символа разделителя используется слэш , wm-school — это шаблон, по которому идет поиск, а символ , расположенный после второго разделителя — это модификатор, позволяющий вести поиск без учета регистра.
В качестве символа разделителя может быть любой символ, кроме буквы, цифры, обратной косой черты или пробела. Самый распространенный разделитель — это слэш , но если ваш шаблон содержит слэш, удобно выбрать другие разделители, такие как или .
Метасимволы
В приведенных выше примерах использовались очень простые шаблоны. Метасимволы позволяют нам выполнять более сложные сопоставления с образцом, например проверять правильность адреса электронной почты. Давайте теперь посмотрим на часто используемые метасимволы.
| Метасимвол | Описание | Пример |
|---|---|---|
| . | Соответствует любому отдельному символу, кроме новой строки | /./ соответствует всему, что имеет один символ |
| ^ | Соответствует началу или строке/исключает символы | /^PH/ соответствует любой строке, начинающейся с PH |
| $ | Соответствует шаблону в конце строки | /ru$/ соответствует it-blog.ru и т.д. |
| * | Соответствует любому нулю (0) или более символов | /com*/ соответствует computer, communication и т. д. |
| + | Требуется, чтобы предшествующие символы появлялись хотя бы раз | /yah+oo/ соответствует yahoo |
| \ | Используется для экранирования метасимволов | /yahoo+\.com/ трактует точку как буквальное значение |
| Символы внутри скобках | // соответствует abc | |
| a-z | Соответствует строчным буквам | /a-z/ соответствует cool, happy и т.д. |
| A-Z | Соответствует заглавным буквам | /A-Z/ соответствует WHAT, HOW, WHY и т.д. |
| 0-9 | Соответствует любому числу от 0 до 9 | /0-4/ соответствует 0,1,2,3,4 |
Приведенный выше список содержит только наиболее часто используемые метасимволы в регулярных выражениях.
Давайте теперь рассмотрим довольно сложный пример, который проверяет действительность адреса электронной почты.
<?php
$my_email = "name@company.com
";
if (preg_match("/^+@+\.{2,5}$/", $my_email)) {
echo "$my_email это действительный адрес электронной почты";
}
else
{
echo "$my_email это не действительный адрес электронной почты";
}
?>
