Что такое postgresql? плюсы и минусы бесплатной базы данных
Содержание:
- Хранение данных
- Подключение к БД
- 2.1. Поддержка АТД в системе баз данных
- pgAdmin
- Partitioning & Inheritance
- 2019
- Принцип работы
- А куда сохраняются мои данные?
- Второй раунд
- Уровни блокировок таблиц
- Инициализация структуры БД
- datagrip
- Backup, Restore, Data Integrity, & Replication
- Режим совместимости конфигурации 1С
- Отказ от Windows
Хранение данных
MySQL
MySQL — это реляционная база данных, для хранения данных в таблицах используются различные движки, но работа с движками спрятана в самой системе. На синтаксис запросов и их выполнение движок не влияет. Поддерживаются такие основные движки MyISAM, InnoDB, MEMORY, Berkeley DB. Они отличаются между собой способом записи данных на диск, а также методами считывания.
Postgresql
Postgresql представляет из себя объектно реляционную базу данных, которая работает только на одном движке — storage engine. Все таблицы представлены в виде объектов, они могут наследоваться, а все действия с таблицами выполняются с помощью объективно ориентированных функций. Как и в MySQL все данные хранятся на диске, в специально отсортированных файлах, но структура этих файлов и записей в них очень сильно отличается.
Подключение к БД
Чтобы получить доступ к базам данных можно воспользоваться стандартной консолью psql.
Windows:
Если Вы хотите подключиться из
bash в Windows
не забудьте добавить местоположение
psql.exe
(у меня это C:\Program Files\PostgreSQL\12\bin) в PATH
Как это делается описано в статье
PATH
psql.exe -h localhost -p 5433 -U postgres
Linux:
sudo su — postgres
psql
psql (12.7 (Ubuntu 12.7-0ubuntu0.20.04.1))
Type «help» for help.
Если БД на локальном хосте
psql -h 127.0.0.1 -d DATABASENAME -U DATABASEUSERNAME
Получить данные о подключении
\conninfo
You are connected to database «postgres» as user «postgres» via socket in «/var/run/postgresql» at port «5432».
2.1. Поддержка АТД в системе баз данных
2.1.3. Расширяемые методы доступа для новых типов данных
Многообещающие возможности расширяемых методов доступа Postgres вдохновили один из моих первых исследовательских проектов в конце аспирантуры: обобщенные деревья поиска (Generalized Search Trees—GiST) [] и последующую концепцию теории индексируемости []. Я реализовал GiST в Postgres в течение семестра после получения докторской степени, что сделало добавление новой логики индексирования в Postgres еще проще. В диссертации Марселя Корнакера из Беркли (Marcel Kornacker) решены сложные задачи восстановления и одновременного доступа, поставленные расширяемым «шаблонным» типом индекса GiST [].
2.1.4. Оптимизатор обработки запросов с дорогостоящими UDF
Когда я поступил в аспирантуру, это была одна из трех тем, которые Стоунбрейкер написал на доске в своем кабинете как варианты для выбора темы моей диссертации. Кажется, второй темой было индексирование функций, а третьей я не помню.По иронии судьбы, код, написанный мною в аспирантуре, был полностью удален из дерева исходных текстов PostgreSQL молодым программистом по имени Нил Конвей (Neil Conway), который несколько лет спустя начал делать кандидатскую диссертацию под моим руководством в Калифорнийском университете в Беркли и теперь является одним из «кандидатских внуков» Стоунбрейкера.
pgAdmin

Им многие пользуются, но, скорее по привычке. Или потому что это бесплатно. pgAdmin4 — продукт странноватый, при этом в описании сказано, что это самый лучший опенсорс продукт для разработки и администрирования.
Как его использовать для администрирования — не очень понятно. pgAdmin’ом нельзя «заинитить» новый сервер, нельзя подправить pg_hba.conf или postgresql.conf. Видимо, имеются в виду скудные графики запросов в секунду, вывод подробностей конфигурации сервера и статистика в таблицах. Не уверен, в общем. Как вы испольуете pgAdmin для администрирования?
Как его использовать с точки зрения разработки — еще менее понятно. Субъективно, интерфейс в целом не удобен для разработки. Несмотря на то, что четвертую версию переписали на python + JS с jQuery, по сути, осталось всё то же самое.
Чтобы немного пояснить ситуацию, в голове разработчика такая картина: есть база на каком-то серваке, в ней — схемы, в схемах — таблицы и вьюхи. Т.е. таблица — максимум, 3-й уровень. А если база одна, то вообще второй уровень. Ткнул по таблице — увидел несколько первых строк.
В голове разработчика pgAdmin как-то так: «Смерть Кощеева на конце иглы, та игла в яйце, то яйцо в утке, та утка в зайце, тот заяц в сундуке, а сундук стоит на высоком дубу, и то дерево Кощей как свой глаз бережёт», а именно (см. картинку):
Есть группа серверов, в ней есть сервер, на сервере существуют базы, роли и т.д., из баз можно выбрать конкретную базу, в ней видно схемы, языки, еще бог знает что. В схемах можно выбрать нужную схему, в схеме 100500 всего, и где-то в конце списка «таблицы». В таблицах можно выбрать нужную таблицу, по ней надо кликнуть правой кнопкой мыши, там в большом списке выбираешь «view data», в этой «view data» есть «view first 100 rows» и уже там наконец-то смерть кощеева несколько строк для ознакомления.
Киллер-фичей pgAdmin является возможность дебажить хранимые процедуры pl/pgsql. Других бесплатных программ с этой возможностью я не встречал.
Partitioning & Inheritance
| 14 | 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | |
|
Default Partition |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Foreign Key references for partitioned tables |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Foreign table inheritance |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Logical Replication for Partitioned Tables |
Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Partitioning by a hash key |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Support for PRIMARY KEY, FOREIGN KEY, indexes, and triggers on partitioned tables |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Table Partitioning |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
UPDATE on a partition key |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
2019
Включение в продукты DeviceLock
22 октября 2019 года стало известно, что DeviceLock включил в свои продукты поддержку Postgres Pro и PostgreSQL. Подробнее .
Запуск программы сертификации специалистов по СУБД PostgreSQL
21 мая 2019 года Postgres Professional сообщил о запуске программы сертификации специалистов по СУБД PostgreSQL.

Программа сертификации предусматривает три уровня с возрастающей квалификацией:
- «Профессионал»
- «Эксперт»
- «Мастер»
Для получения сертификата необходимо пройти тестирование в офисе компании Postgres Professional и набрать проходной балл. Материалом для подготовки могут служить авторские курсы Postgres Professional, доступные на сайте, а также регулярно читаемые в сертифицированных учебных центрах. Ежегодно слушателями курсов становятся более 500 человек.
Тест для первого уровня — «Профессионал» — включает в себя 50 вопросов по основам администрирования PostgreSQL и длится 75 минут. Поскольку для каждого релиза PostgreSQL характерны свои особенности администрирования, сертификация соотносится с конкретной версией СУБД. Например, на май 2019 года доступен тест для 10-ой версии PostgreSQL DBA1-10. Для прошедших тестирование на знание PostgreSQL 10 и желающих в будущем подтвердить свои навыки для 11-ой версии достаточно будет пройти короткое дополнительное тестирование, сфокусированное на отличиях продуктов.
Для получения сертификата уровня «Эксперт» понадобится успешно пройти уже три теста:
- DBA2-10 (настройка и мониторинг PostgreSQL)
- DBA3-10 (резервное копирование и репликация PostgreSQL)
- QPT-10 (оптимизация запросов)
А переход на уровень «Мастер» предполагает выполнение практических заданий по работе с PostgreSQL. В дальнейших планах компании Postgres Professional – запуск программы сертификации для разработчиков приложений на PostgreSQL.
Иван Панченко прокомментировал запуск программы сертификации:
|
Специалисты по Postgres становятся все более востребованными на российском рынке, что подтверждают данные кадровых агентств. В такой ситуации необходимы единые стандарты и критерии для оценки уровня знаний. Во многом наша программа сертификации стала ответом на запросы заказчиков и партнеров, заинтересованных в независимом инструменте оценки и повышения квалификации своих сотрудников. Иван Панченко, заместитель генерального директора Postgres Professional |
Совместимость с Live Universal Interface
15 апреля 2019 года компания ФОРС Телеком сообщила о появлении в экосистеме программно-инструментальных средств, совместимых с открытой платформой Postgres Pro/PostgreSQL конструктора пользовательских веб-интерфейсов к базам данных — Live Universal Interface (LUI). Подробнее здесь.
Совместимость с TerraLink xDE
12 марта 2019 года TerraLink сообщил, что TerraLink xDE поддерживает OC семейства Linux и СУБД PostgreSQL. Подробнее .
Принцип работы
Для нужно выбрать:
- имя;
- регион;
- версию СУБД;
- конфигурацию нод;
- количество реплик, если кластер отказоустойчивый;
- подсеть, в которой будет создан кластер.
После запуска процесса создания в интерфейсе отобразится новый кластер. Все возможности по управлению кластером находятся на его странице, которая станет доступна после перехода кластера в статус Active.
Пользователям для работы доступен только сам кластер — доступа к нодам кластера нет, так как они находятся на стороне Selectel.
Внутри кластера находится вся функциональность по управлению. На странице кластера можно создавать базы данных, пользователей, назначать права доступа и масштабировать кластер.
Адреса серверов и подсеть, к которой подключен кластер, менять нельзя.
После создания кластера нужно и . Затем необходимо назначить пользователям права доступа на базы данных. В кластере можно создать до 50 баз данных и до 50 пользователей, все имена должны быть уникальными.
При подключении к кластеру нужно указать имя базы данных, имя пользователя, пароль, а также порт и адреса кластера. Подробнее о подключении к кластеру.
У всех пользователей в кластере одинаковые права.
А куда сохраняются мои данные?
Базы данных – это в первую очередь история про персистентность. И,.. Хьюстон, кажется у нас проблема… К настоящему моменту мы никак не управляем долговременным хранением нашей базы данных. Эту задачу целиком на себя берёт Docker, автоматически создавая volume для контейнера с БД. Есть целый ворох причин, почему это плохо, начиная от банальной невозможности просматривать содержимое volume’ов в бесплатной версии Docker Desktop и заканчивая лимитами дискового пространства.
Разумеется, хорошей практикой является полностью ручное управление физическим размещением создаваемых баз данных. Для этого нам нужно подмонтировать соответствующий каталог (куда будут сохраняться данные) в контейнер и при необходимости переопределить переменную окружения PGDATA:
Вариант с макросом, использующий для инициализации БД скрипты из предыдущего раздела:
С однострочниками на этом закончим. Все дальнейшие шаги будем осуществлять только через compose-файл:
При запуске этого скрипта рядом с ним создастся директория pgdata, где будут располагаться файлы БД.
Второй раунд
Тут уже практически пользовательская нагрузка. Операция, на которой проводится тестирование, – восстановление последовательности партионного
учета управленческих партий. Это последняя УПП на момент тестирования, код типовой. Также типовой клиент, у которого итоги рассчитаны на полгода назад. Я не знаю, почему у клиентов такая амнезия по поводу этой регламентной операции, но никто не хочет следить за итогами. Почему, никто объяснить тоже не может. Поэтому берем типовой код, типового клиента, в самих партиях за месяц 150 тысяч документов, а строк в документах около 2 миллионов.
Все это делаем в 10 потоков. Это уже чуть-чуть не типовой этап, сделана определенная обработка, но внутри все запросы типовые.
В результате у нас получилось, что Postgres всего на 4% лучше. Делалось все очень долго – порядка 18 часов. И бухгалтеры будут вынуждены весь день не работать, чтобы дождаться результатов.

Поскольку результат получился не очень большой, плюс 4%, решили вместо
мельдония использовать что-нибудь похлеще. Второй в рейтинге вредных советов интернета на запрос «1С + Postgres тормозит» оказалась рекомендация отключить autovacuum. Отключили.
Результат получился еще хуже – примерно на 5%. То есть если бы мы изначально настроили систему с помощью этого вредного совета, мы бы вообще раунд полностью проиграли, было бы минус 0,6%.
На этом хочу остановиться чуть подробнее. Что за зверь такой autovacuum, зачем он нужен. И почему разработчики Postgres на каждой конференции твердят: «Не отключайте autovacuum!», но народ упорно его отключает. Попытаюсь объяснить, как говорят, на пальцах.
Чтобы понять, для чего нужен autovacuum, нужно понять, как Postgres работает с данными. Операция insert – записали строчку. Помимо строчки, пишется еще два служебных параметры x min и x max. В x min записывается номер транзакции, которая выполнила этот insert. Операция delete на самом деле ничего не удаляет, она просто в служебное поле строки x max записывает номер транзакции, которая ее удалила. Потом идет самая прикольная операция update. На самом деле нет такой операции, это просто delete + insert.

А в мире 1С, к сожалению, просто обожают работать задним числом: для пользователей не вопрос перевести месяц или год. То есть апдейтов миллионы. У нас не столько растут данные с помощью insert, сколько с помощью update, мы постоянно что-то обновляем. Из-за этого база имеет эффект распухания. Ладно, пусть раздувается, скажем админам, что это их проблемы, пусть увеличивают диски. Они увеличат. Но если было бы все так просто, никто не заморачивался бы. Проблема в том, что данные хранятся не где-то в сферическом вакууме, они хранятся в страницах. И когда у вас в страницах хранится куча мертвых данных, а в Postgres есть такое страшное понятие, как мертвые строчки, и когда вы делаете запрос базе данных, движок вынужден поднять все страницы с данными, отфильтровать данные, в которых x max пустой, и только с ними потом работать. Вы каждый раз заставляете Postgres ставить олимпийские рекорды по поднятию данных с дисков, чтобы выдать вам выборку.

Что делает autovacuum? Autovacuum – это своеобразный пылесос, он циклически и периодически идёт к каждой таблице вашей базы данных и делает выборку всех данных, где x max не пустой и чистит их физически. Теперь туда insert возможен, у вас на страницах будет больше живых данных, чем мертвых. Эффект – вам проще поднимать страницы. Это первое.
Второе. Помимо чистого autovacuum, есть еще такой фоновый процесс autovacuum analyze. Это аналог фонового обновления статистики в MS SQL. Без него планировщик никогда не узнает, что вы в таблицу добавили данные. Было в таблице 100 записей, добавили вы миллион записей, но планировщик свято уверен, что там их 100. И при любом запросе не парится и не ищет никакие индексы. Он просит TableScan, ему его дают, а там миллион записей. И вы сидите и ждете несколько минут.
Поэтому никогда не выключайте autovacuum. Надо его правильно настраивать, но ни в коем случае не отключать. Он имеет кучу настроек, и если у вас autovacuum настроен достаточно агрессивно, то есть он срабатывает на очень маленьком проценте изменения данных в таблицах, то вам не нужны даже ночные и недельные регламенты над базой данных, которые имеются у MS SQL. Ничего не надо делать, просто ничего. Кое-что делают только админы, если точно знают, что в этой таблице недавно удалили огромный массив данных, и ее нужно, грубо говоря, сжать. Тогда делается autovacuum full – это реструктуризация таблицы в понятиях 1С. Рядом создается табличка, куда и копируются данные.
В других случаях вам никакие регламенты, ни ночные, ни недельные, не нужны. Autovacuum все сделает за вас. Только настраивайте его правильно.
Уровни блокировок таблиц
Команда LOCK TABLE предназначена для блокировки таблиц на время транзакции. Блокировкой называется временное ограничение доступа к таблице (в зависимости от выбранного режима). Сеанс, заблокировавший таблицу, пользуется нормальным доступом; последствия блокировки распространяются только на других пользователей, пытающихся получить доступ к заблокированной таблице.
Блокировка не означает отказа в доступе. С точки зрения пользователя, подключенного к базе данных и пытающегося обратиться к заблокированному ресурсу, блокировка приводит к задержке, но не к отказу в предоставлении доступа. Пользователю приходится ожидать либо завершения заблокированной команды пользователем, либо снятия блокировки с таблицы.
Некоторые команды SQL автоматически устанавливают блокировку для выполнения своих функций; в таких случаях PostgreSQL всегда выбирает минимально необходимый уровень блокировки. После завершения транзакции блокировка немедленно снимается.
Команда LOCK TABLE без параметра устанавливает максимально жесткий режим блокировки (ACCESS EXCLUSIVE). Чтобы ограничения были менее жесткими, следует явно задать нужный режим.
Блокировка таблиц возможна только в транзакциях. Выполнение команды LOCK TABLE вне транзакционного блока не приводит к ошибке, но установленная блокировка немедленно снимается. Транзакция создается командой BEGIN; команда COMMIT фиксирует изменения в базе данных и снимает блокировку.
Ситуация взаимной блокировки (deadlock) возникает в там случае, когда каждая из двух транзакций ожидает снятия блокировки другой транзакцией. Хотя PostgreSQL распознает взаимные блокировки и завершает их командой ROLLBACK, это все равно причиняет определенные неудобства. Приложения не должны сталкиваться с проблемой взаимных блокировок, поэтому проектируйте их так, чтобы объекты всегда блокировались в одинаковом порядке.
- ACCESS SHARE MODE. Устанавливается автоматически командой SELECT для таблиц, из которых производится выборка данных. В заблокированных таблицах запрещается выполнение команд ALTER TABLE, DROP TABLE и VACUUM. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровня ACCESS EXCLUSIVE MODE.
- ROW SHARE MODE. Устанавливается автоматически командами SELECT, содержащими секцию FOR UPDATE или FOR SHARE. В заблокированных таблицах запрещается выполнение команд ALTER TABLE, DROP TABLE и VACUUM. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровней EXCLUSIVE MODE и ACCESS EXCLUSIVE MODE.
- ROW EXCLUSIVE MODE. Устанавливается автоматически командами UPDATE, INSERT и DELETE. В заблокированных таблицах запрещается выполнение команд ALTER TABLE, DROP TABLE и CREATE INDEX. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровней SHARE MODE, SHARE ROW EXCLUSIVE MODE, EXCLUSIVE MODE и ACCESS EXCLUSIVE MODE.
- SHARE UPDATE EXCLUSIVE MODE . Устанавливается автоматически командами VACUUM (без FULL), ANALYZE и CREATE INDEX CONCURRENTLY.
- SHARE MODE. Устанавливается автоматически командами CREATE INDEX (без CONCURRENTLY). В заблокированных таблицах запрещается выполнение команд INSERT, UPDATE, DELETE, ALTER TABLE, DROP TABLE и VACUUM. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровней ROW EXCLUSIVE MODE, SHARE ROW EXCLUSIVE MODE, EXCLUSIVE MODE и ACCESS EXCLUSIVE MODE.
- SHARE ROW EXCLUSIVE MOOE. Специальный режим блокировки, практически идентичный режиму EXCLUSIVE MODE, но допускающий установку параллельных блокировок уровня ROW SHARE MODE.
- EXCLUSIVE MODE. Запрещает выполнение команд INSERT, UPDATE, DELETE, CREATE INDEX, ALTER TABLE, DROP TABLE и VACUUM, а также команд SELECT с секцией FOR UPDATE. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровней ROW SHARE MODE, ROW EXCLUSIVE MODE, SHARE MODE, SHARE ROW EXCLUSIVE MODE и ACCESS EXCLUSIVE MODE.
- ACCESS EXCLUSIVE MODE. Устанавливается автоматически командами ALTER TABLE, DROP TABLE и VACUUM. В этом режиме для заблокированных таблиц запрещаются любые команды или параллельные блокировки любого уровня.
Инициализация структуры БД
К текущему моменту мы научились запускать в контейнере необходимую нам версию PostgreSQL, переопределять суперпользователя и создавать базу данных с нужным именем.
Это хорошо, но чистая база данных вряд ли будет сильно полезна. Для работы/тестов/экспериментов нужно наполнить эту базу таблицами и другими объектами. Разумеется, всё это можно сделать вручную, но, согласитесь, гораздо удобнее, когда сразу после запуска вы автоматически получаете полностью готовую БД.
Разработчики официального образа PostgreSQL естественно предусмотрели этот момент и предоставили нам специальную точку входа для инициализации базы данных — docker-entrypoint-initdb.d. Любые *.sql или *.sh файлы в этом каталоге будут рассматриваться как скрипты для инициализации БД. Здесь есть несколько нюансов:
-
если БД уже была проинициализирована ранее, то никакие изменения к ней применяться не будут;
-
если в каталоге присутствует несколько файлов, то они будут отсортированы по имени с использованием текущей локали (по умолчанию en_US.utf8).
Инициализацию БД можно запустить через однострочник, но в этом случае требуется указывать абсолютный путь до каталога со скриптами:
Например, на моей машине это выглядит так:
В качестве обходного варианта можно использовать макрос, на лету определяя рабочую директорию, и запускать команду из каталога со скриптами:
Использование docker-compose файла в этом случае более удобно и позволяет указывать относительные пути:
Здесь хотелось бы акцентировать ваше внимание на одной простой вещи, о которой уже говорил в предыдущей статье: при создании миграций БД для ваших приложений отдавайте предпочтение чистому (plain) SQL. В этом случае их можно будет переиспользовать с минимальными затратами
datagrip
 IDE для баз. Несмотря на то, что продукт относительно свежий, он уже используется повсеместно. В основном за счет того, что сразу встроен в мегапопулярные продукты от компании JetBrains: IntelliJ IDEA, PyCharm, PhpStorm и т.д.
IDE для баз. Несмотря на то, что продукт относительно свежий, он уже используется повсеместно. В основном за счет того, что сразу встроен в мегапопулярные продукты от компании JetBrains: IntelliJ IDEA, PyCharm, PhpStorm и т.д.
Собственно, эта его встроенность одновременно является и главной киллер-фичей продукта: вы редактируете, например, php-код, в котором есть строка с sql-запросом, и внезапно понимаете, что IDE вам подсказывает (прямо в вашем коде) синтаксис SQL, названия таблиц и их полей, подчеркивает красненьким, если что-то написано не так, форматирует SQL и многое-многое другое. Конечно, в этом же IDE можно делать и то, что умеют другие GUI для баз: просматривать списки таблиц и других сущностей, отдельно делать запросы, экспорт таблиц в разные форматы и многое другое.
Из особенностей я бы отметил следующие вещи:
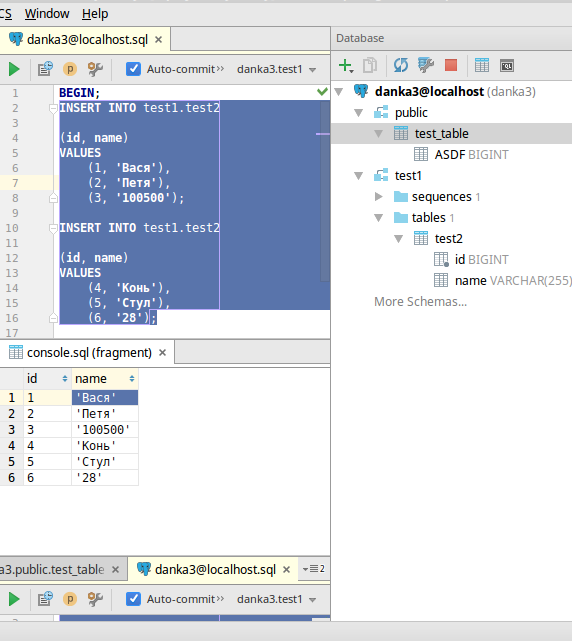
- можно выделить несколько insert’ов и нажать «Edit as table» (см. картинку). После чего отредактировать это в удобном табличном виде вместо sql-синтаксиса, причем там же можно добавлять строки, колонки, экспортировать в csv и т.д.
- Можно сравнивать результаты двух запросов. Это полезно, когда пытаешься упростить сложный запрос, и при этом ничего не сломать.
- встроенность в код проработана не до конца. К примеру, при переименовывании в каком-либо интерфейсе колонки таблицы, IDE не находит нужные строки с SQL в коде (при этом автокомплит в этих строках работал), и наоборот, находит какую-то чушь.
- Визуальной разработки не очень много. Т.е. вы можете сделать таблицу, но view уже не можете. Если таблица содержит какие-то id с foreign key (допустим, ссылка на некий словарь), хотелось бы при в вводе данных в таблицу выбирать значения из словаря, а не вбивать айдишки.
- Если посмотреть таблицу в какой-нибудь из схем, то Datagrip посылает запрос set search_path = имясхемы, что приводит к плохим последствиям, если используется pgbouncer (а он используется почти всегда в случае с php или когда много серверов), так что для dev-разработки лучше использовать разные подключения: для работы кода — через pgbouncer, для ide — напрямую к базе.
Datagrip активно развивается, в частности, исправлены некоторые раздражающие баги с подсветкой синтаксиса.
В целом хороший современный инструмент, рекомендую.
Backup, Restore, Data Integrity, & Replication
| 14 | 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Cascading streaming replication |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
Checksum on data pages |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
| Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No | |
|
Enable/Disable page checksums in an offline cluster |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Generic WAL facility |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No |
|
Hot Standby |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
Logical Replication |
Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No |
|
min_wal_size / max_wal_size |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Multiple synchronous standbys |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No |
|
Parallel pg_dump |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
|
pg_basebackup tool |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
pg_receivewal (formerly pg_receivexlog) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
Point-in-Time Recovery |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Quorum commit for synchronous replication |
Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No |
|
remote_apply mode |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No |
| Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | |
|
Streaming-only cascading replication |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
|
Streaming Replication |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
Synchronous replication |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
Time-delayed Standbys |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No |
|
Verify backup integrity (pg_verifybackup) |
Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Warm Standby |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
Режим совместимости конфигурации 1С
Приветствую, коллеги! В этой статье будет сделан обзор функции совместимости конфигурации 1С с другими версиями конфигураций 1С, а также рассмотрено, как выбрать и настроить режим совместимости конфигурации с версией 1С 8.3.
Во-первых, разберём главное понятие в этой статье: режим совместимости в конфигурации – это устройство, благодаря которому выводится номер версии системы, под которую станет открыто приложение 1С:Предприятие. Данный режим существует на платформе 1С начиная с версий 8.2 и 8.3 (платформа версии 1С:Предприятие 8.3 совместима с платформой версии 1С:Предприятие 8.2).
Отказ от Windows
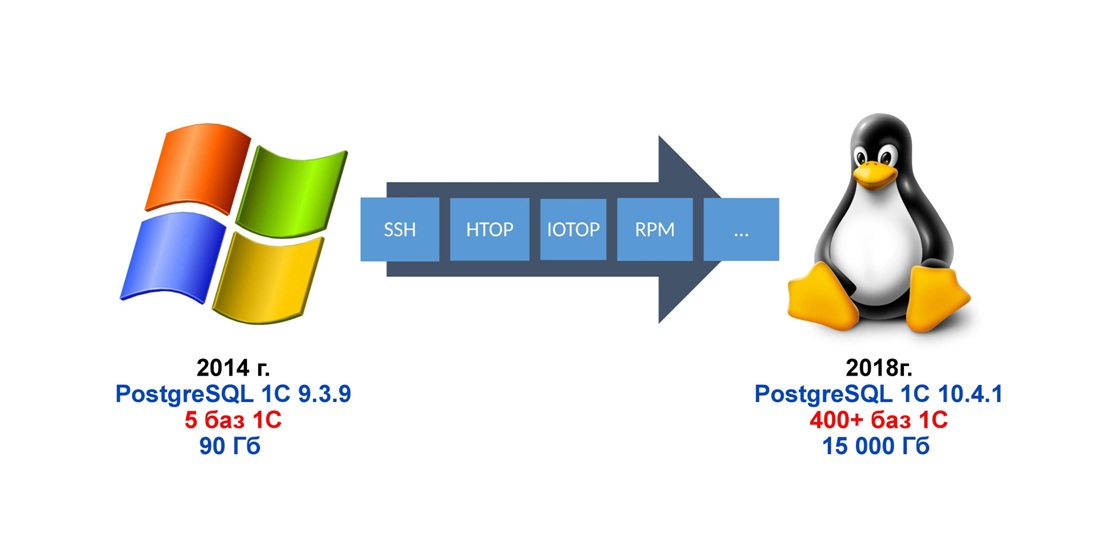
Но у нас время поджимало. И мы решили прыгать через пропасть незнания в Linux. Это вообще кошмар. То есть система Linux – хорошая, но кошмар для админов, которые всю жизнь жили на Windows. Ни красивых окошек, ни мышек, ни кликов, даже диспетчера задач нет. Есть какие-то черные окна с белыми буковками. Когда разберешься, буковки станут цветными. Но это все, что ожидает админа в Linux. Какие службы работают, как что куда поставить – ничего не понятно. Там уже бессонные ночи начались не только у 1С-ников, но и у админов. Но примерно на 20-ой инсталляции CentOS все, вроде, стало хорошо.

Запустили Postgres, и он тоже заработал. А мы к тому времени уже были крутые чуваки в настройке Postgres, и мы его сразу настроили: и статистику внесли в оперативную память, и все параметры включили как надо.
На текущий момент мы пришли к такой ситуации: у нас 400 с лишним баз, 15 терабайт данных, все это крутится на Postgres на Linux, все сервера Postgres имеют реплики, кто-то имеет каскадные реплики, кто-то имеет несколько реплик на один мастер. То есть это не просто какая-то одноранговая система баз данных. Мы там снимаем бэкапы (backup) с реплик, мы можем восстановить бэкап с рабочей базы в тестовую или базу разработчиков одной строчкой, сохраняя транзакционную целостность данных, при этом не создавая файла бэкапа.
Самое удивительное – все есть в документации! Ты на грабли наступил уже 15 раз, все попробовал, думаешь, что «открыл Америку». Заходишь в документацию, а там прямым текстом написано все то, что ты открывал до этого три дня. Понимать эту документацию ты начинаешь только тогда, когда несколько раз уже окунулся в саму практику.
Так мы счастливо живём до сих пор.