Регулярные выражения в python от простого к сложному. подробности, примеры, картинки, упражнения
Содержание:
- А теперь вернёмся к тем особенностям, которые были изложены в начале статьи
- re.sub()
- Связанные методы Re
- Example of re.M or Multiline Flags
- Параллелизм и конкурентность
- ООП
- 3.2. First Steps Towards Programming¶
- Sets
- And Now For Something Completely Different
- Странности, которые не странности
- Major new features of the 3.8 series, compared to 3.7
- Использование групп при заменах
- Функция python re.sub ()
- Методы
- Куда пойти отсюда?
А теперь вернёмся к тем особенностям, которые были изложены в начале статьи
1. Использование генератора дважды
В данном примере, список будет содержать элементы только в первом случае, потому что генераторное выражение — это итератор, а итераторы, как мы уже знаем — сущности одноразовые. И при повторном использовании не будут отдавать никаких элементов.
2. Проверка вхождения элемента в генератор
А теперь дважды проверим, входит ли элемент в последовательность:
В данном примере, элемент будет входить в последовательность только 1 раз, по причине того, что проверка на вхождение проверяется путем перебора всех элементов последовательности последовательно, и как только элемент обнаружен, поиск прекращается. Для наглядности приведу пример:
Как мы видим, при создании списка из генераторного выражения, в нём оказываются все элементы, после искомого. При повторном же создании, вполне ожидаемо, список оказывается пуст.
3. Распаковка словаря
При использовании в цикле , словарь будет отдавать ключи:
Так как распаковка опирается на тот же протокол итератора, то и в переменных оказываются именно ключи:
re.sub()
Здесь значение «sub» — это сокращение от substring, т.е. подстрока. В данном методе исходный шаблон сопоставляется с заданной строкой и, если подстрока найдена, она заменяется параметром repl.
Кроме того, у метода есть дополнительные аргументы. Это , счетчик, в нем указывается, сколько раз заменяется регулярное выражение. А также , в котором мы можем указать флаг регулярного выражения (например, )
Синтаксис:
В результате работы кода возвращается либо измененная строка, либо исходная.
Посмотрим на работу метода на следующем примере.
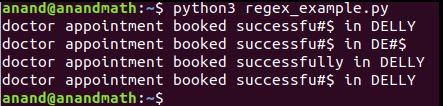
import re
# Шаблон 'lly' встречается в строке в "successfully" и "DELLY"
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY'))
# Благодаря использованию флага регистр игнорируется, и 'lly' находит два совпадения
# Когда совпадения найдены, 'lly' заменяется на '~*' в "successfully" и "DELLY".
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY', flags=re.IGNORECASE))
# Чувствительность к регистру: 'lLY' не находит совпадений, и ничего в строке не будет заменено
print(re.sub('lLY', '#$', 'doctor appointment booked successfully in DELLY'))
# С count = 1 заменяется только одно совпадение с шаблоном
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY', count=1, flags=re.IGNORECASE))
Связанные методы Re
Существует семь важных методов регулярного выражения, которые вы должны освоить:
- Re.findall (шаблон, строка) Метод возвращает список строковых совпадений. Читайте больше в Наше руководство в блоге Отказ
- Re.Search (шаблон, строка) Метод возвращает объект совпадения первого матча. Читайте больше в Наше руководство в блоге Отказ
- Re.match (шаблон, строка) Метод Возвращает объект совпадения, если установки Regeex в начале строки. Читайте больше в Наше руководство в блоге Отказ
- Re.fullmatch (шаблон, строка) Метод возвращает объект совпадения, если Regeex соответствует всей строке. Читайте больше в Наше руководство в блоге Отказ
- Re.compile (Pattern) Способ подготавливает шаблон регулярной экспрессии – и возвращает объект Regex, который вы можете использовать несколько раз в вашем коде. Читайте больше в Наше руководство в блоге Отказ
- Re.split (шаблон, строка) Метод возвращает список строк, сопоставив все вхождения шаблона в строке и разделить строку вдоль тех. Читайте больше в Наше руководство в блоге Отказ
- Re.sub (Re.sub (Pattern, Repl, String ,,) Метод возвращает новую строку, в которой все вхождения шаблона в старой строке заменены на REPL. Читайте больше в Наше руководство в блоге Отказ
Эти семь методов составляют 80% от того, что вам нужно знать, чтобы начать работу с функциональностью регулярных выражений Python.
Example of re.M or Multiline Flags
In multiline the pattern character match the first character of the string and the beginning of each line (following immediately after the each newline). While expression small “w” is used to mark the space with characters. When you run the code the first variable “k1” only prints out the character ‘g’ for word guru99, while when you add multiline flag, it fetches out first characters of all the elements in the string.

Here is the code
import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print(k1) print(k2)
- We declared the variable xx for string ” guru99…. careerguru99….selenium”
- Run the code without using flags multiline, it gives the output only ‘g’ from the lines
- Run the code with flag “multiline”, when you print ‘k2’ it gives the output as ‘g’, ‘c’ and ‘s’
- So, the difference we can see after and before adding multi-lines in above example.
Likewise, you can also use other Python flags like re.U (Unicode), re.L (Follow locale), re.X (Allow Comment), etc.
Python 2 Example
Above codes are Python 3 examples, If you want to run in Python 2 please consider following code.
# Example of w+ and ^ Expression
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+",xx)
print r1
# Example of \s expression in re.split function
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+", xx)
print (re.split(r'\s','we are splitting the words'))
print (re.split(r's','split the words'))
# Using re.findall for text
import re
list =
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print(z.groups())
patterns =
text = 'software testing is fun?'
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text):
print 'found a match!'
else:
print 'no match'
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'+@+', abc)
for email in emails:
print email
# Example of re.M or Multiline Flags
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^\w", xx)
k2 = re.findall(r"^\w", xx, re.MULTILINE)
print k1
print k2
Summary
A regular expression in a programming language is a special text string used for describing a search pattern. It includes digits and punctuation and all special characters like $#@!%, etc. Expression can include literal
- Text matching
- Repetition
- Branching
- Pattern-composition etc.
In Python, a regular expression is denoted as RE (REs, regexes or regex pattern) are embedded through Python re module.
- “re” module included with Python primarily used for string searching and manipulation
- Also used frequently for webpage “Scraping” (extract large amount of data from websites)
- Regular Expression Methods include re.match(),re.search()& re.findall()
- Other Python RegEx replace methods are sub() and subn() which are used to replace matching strings in re
- Python Flags Many Python Regex Methods and Regex functions take an optional argument called Flags
- This flags can modify the meaning of the given Regex pattern
- Various Python flags used in Regex Methods are re.M, re.I, re.S, etc.
Параллелизм и конкурентность
Питон предоставляет широкие возможности как для параллельного, так и для конкурентного программирования, однако не обходиться без особенностей.
Если вам нужен параллелизм, а это бывает когда ваши задачи требуют вычислений, то вам стоит обратить внимание на модуль. А если в ваших задачах много ожидания IO, то питон предоставляет массу вариантов на выбор, от тредов и gevent, до asyncio.
Все эти варианты выглядят вполне пригодными для использования (хотя треды значительно больше ресурсов требуют), но есть ощущение, что asyncio потихоньку выдавливает остальных, в том числе благодаря всяким плюшками типа uvloop
А если в ваших задачах много ожидания IO, то питон предоставляет массу вариантов на выбор, от тредов и gevent, до asyncio.
Все эти варианты выглядят вполне пригодными для использования (хотя треды значительно больше ресурсов требуют), но есть ощущение, что asyncio потихоньку выдавливает остальных, в том числе благодаря всяким плюшками типа uvloop.
Если кто не заметил — в питоне треды это не про параллельность, я недостаточно компетентен, чтобы хорошо рассказать про GIL, но по это теме достаточно материалов, поэтому и нет такой необходимости, главное, что нужно запомнить это то, что треды в питоне (точнее в CPython) ведут себя не так как это принято в других языках программирования — они исполняются только на одном ядре, а значит не подходят для случаев когда вам нужна настоящая параллельность, однако, выполнение тредов приостанавливается при ожидании ввода-вывода, поэтому их можно использовать для конкурентности.
ООП
ООП в питоне сделано весьма интересно (одни чего стоят) и это большая тема, однако сапиенс знакомый с ООП вполне может нагуглить всё (или найти на хабре), что ему захочется, поэтому нет смысла повторяться, хотя стоит оговорить, что питон следует немного другой философии — считается, что программист умнее машины и не является вредителем (UPD: подробнее), поэтому в питоне по умолчанию нет привычных по другим языкам модификаторов доступа: private методы реализуются добавлением двойного подчёркивания (что в рантайме изменяет имя метода не позволяя случайно его использовать), а protected одним подчёркиванием (что не делает ничего, это просто соглашение об именовании).
Те кто скучает по привычному функционалу могут поискать попытки привнести в питон такие возможности, мне нагуглилась пара вариантов (lang, python-access), но я их не тестировал и не изучал.
Единственный минус стандартных классов — шаблонный код во всяких дандер методах, лично мне нравится библиотека attrs, она значительно более питоническая.
Стоит упомянуть, что так в питоне всё объекты, включая функции и классы, то классы можно создавать динамически (без использования ) функцией .
Также стоит почитать про (на хабре) и дескрипторы (хабр).
Особенность, которую стоит запомнить — атрибуты класса и объекта это не одно и тоже, в случае неизменяемых атрибутов это не вызывает проблем так как атрибуты «затеняются» (shadowing) — создаются автоматически атрибуты объекта с таким же именем, а вот в случае изменяемых атрибутов можно получить не совсем то, что ожидалось:
получаем:
как можно увидеть — изменяли , а изменился и в т.к. этот атрибут (в отличии от ) принадлежит не экземпляру, а классу.
3.2. First Steps Towards Programming¶
Of course, we can use Python for more complicated tasks than adding two and two
together. For instance, we can write an initial sub-sequence of the
Fibonacci series
as follows:
>>> # Fibonacci series: ... # the sum of two elements defines the next ... a, b = , 1 >>> while a < 10 ... print(a) ... a, b = b, a+b ... 1 1 2 3 5 8
This example introduces several new features.
-
The first line contains a multiple assignment: the variables and
simultaneously get the new values 0 and 1. On the last line this is used again,
demonstrating that the expressions on the right-hand side are all evaluated
first before any of the assignments take place. The right-hand side expressions
are evaluated from the left to the right. -
The loop executes as long as the condition (here: )
remains true. In Python, like in C, any non-zero integer value is true; zero is
false. The condition may also be a string or list value, in fact any sequence;
anything with a non-zero length is true, empty sequences are false. The test
used in the example is a simple comparison. The standard comparison operators
are written the same as in C: (less than), (greater than),
(equal to), (less than or equal to), (greater than or equal to)
and (not equal to). -
The body of the loop is indented: indentation is Python’s way of grouping
statements. At the interactive prompt, you have to type a tab or space(s) for
each indented line. In practice you will prepare more complicated input
for Python with a text editor; all decent text editors have an auto-indent
facility. When a compound statement is entered interactively, it must be
followed by a blank line to indicate completion (since the parser cannot
guess when you have typed the last line). Note that each line within a basic
block must be indented by the same amount. -
The function writes the value of the argument(s) it is given.
It differs from just writing the expression you want to write (as we did
earlier in the calculator examples) in the way it handles multiple arguments,
floating point quantities, and strings. Strings are printed without quotes,
and a space is inserted between items, so you can format things nicely, like
this:>>> i = 256*256 >>> print('The value of i is', i) The value of i is 65536The keyword argument end can be used to avoid the newline after the output,
or end the output with a different string:>>> a, b = , 1 >>> while a < 1000 ... print(a, end=',') ... a, b = b, a+b ... 0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,
Footnotes
-
Since has higher precedence than , will be
interpreted as and thus result in . To avoid this
and get , you can use . -
Unlike other languages, special characters such as have the
same meaning with both single () and double () quotes.
The only difference between the two is that within single quotes you don’t
need to escape (but you have to escape ) and vice versa.
Sets
A set is a set of characters inside a pair of square brackets with a special meaning:
| Set | Description | Try it |
|---|---|---|
| Returns a match where one of the specified characters (, , or ) are present |
Try it » | |
| Returns a match for any lower case character, alphabetically between and |
Try it » | |
| Returns a match for any character EXCEPT , , and |
Try it » | |
| Returns a match where any of the specified digits (, , , or ) are present |
Try it » | |
| Returns a match for any digit between and |
Try it » | |
| Returns a match for any two-digit numbers from and | Try it » | |
| Returns a match for any character alphabetically between and , lower case OR upper case |
Try it » | |
| In sets, , , , , , , has no special meaning, so means: return a match for any character in the string |
Try it » |
And Now For Something Completely Different
trong>Mr. Praline (John Cleese): ‘ELLO POLLY!!! Testing! Testing! This is your nine o’clock alarm call!
(Takes parrot out of the cage , throws it up in the air and watches it plummet to the floor.)
Mr. Praline: Now that’s what I call a dead parrot.
Owner (Michael Palin): No, no… No, he’s stunned!
Mr. Praline: STUNNED?!
Owner: Yeah! You stunned him, just as he was wakin’ up! Norwegian Blues stun easily, major.
Mr. Praline: Um… now look, mate. I’ve definitely ‘ad enough of this. That parrot is definitely deceased, and when I purchased it not ‘alf an hour ago, you assured me that its total lack of movement was due to it bein’ tired and shagged out following a prolonged squawk.
Owner: Well, he’s… he’s, ah… probably pining for the fjords.
| Version | Operating System | Description | MD5 Sum | File Size | GPG |
|---|---|---|---|---|---|
| Gzipped source tarball | Source release | 83d71c304acab6c678e86e239b42fa7e | 24720640 | SIG | |
| XZ compressed source tarball | Source release | d9eee4b20155553830a2025e4dcaa7b3 | 18433456 | SIG | |
| macOS 64-bit Intel installer | macOS | for macOS 10.9 and later | 690ddb1be403a7efb202e93f3a994a49 | 29896827 | SIG |
| macOS 64-bit universal2 installer | macOS | experimental, for macOS 11 Big Sur and later; recommended on Apple Silicon | ae8a1ae082074b260381c058d0336d05 | 37300939 | SIG |
| Windows embeddable package (32-bit) | Windows | 659adf421e90fba0f56a9631f79e70fb | 7348969 | SIG | |
| Windows embeddable package (64-bit) | Windows | 3acb1d7d9bde5a79f840167b166bb633 | 8211403 | SIG | |
| Windows help file | Windows | a06af1ff933a13f6901a75e59247cf95 | 8597086 | SIG | |
| Windows installer (32-bit) | Windows | b355cfc84b681ace8908ae50908e8761 | 27204536 | SIG | |
| Windows installer (64-bit) | Windows | Recommended | 62cf1a12a5276b0259e8761d4cf4fe42 | 28296784 | SIG |
Странности, которые не странности
На первый взгляд мне показалось странным, что тип range не включает правую границу, но потом добрый человек мне неучу где мне нужно поучиться и оказалось, что всё вполне логично.
Отдельная большая тема это округления (хотя это проблема общая практически для всех языков программирования), помимо того, что округление используется какое угодно кроме того, что все изучали в школьном курсе математики, так на это ещё накладываются проблемы преставления чисел с плавющей точкой, отсылаю к подробной статье.
Грубо говоря вместо привычного, по школьному курсу математики, округления по алгоритма используется алгоритм , которые уменьшает вероятность искажений при статистическом анализе и поэтому рекомендуется стандартом IEEE 754.
Также я не мог понять почему , а потом, другой добрый человек, , что это неизбежно следует из самого математического определения, по которому, остаток не может быть отрицательным, что и приводит к такому необычному поведению для отрицательных чисел.
ACHTUNG! Теперь это опять странность и я ничего не понимаю, см. сей .
Major new features of the 3.8 series, compared to 3.7
- PEP 572, Assignment expressions
- PEP 570, Positional-only arguments
- PEP 587, Python Initialization Configuration (improved embedding)
- PEP 590, Vectorcall: a fast calling protocol for CPython
- PEP 578, Runtime audit hooks
- PEP 574, Pickle protocol 5 with out-of-band data
- Typing-related: PEP 591 (Final qualifier), PEP 586 (Literal types), and PEP 589 (TypedDict)
- Parallel filesystem cache for compiled bytecode
- Debug builds share ABI as release builds
- f-strings support a handy specifier for debugging
- is now legal in blocks
- on Windows, the default event loop is now
- on macOS, the spawn start method is now used by default in
- can now use shared memory segments to avoid pickling costs between processes
- is merged back to CPython
- is now 40% faster
- now uses Protocol 4 by default, improving performance
There are many other interesting changes, please consult the «What’s New» page in the documentation for a full list.
Использование групп при заменах
Использование групп добавляет замене (, работает не только в питоне, а почти везде) очень удобную возможность: в шаблоне для замены можно ссылаться на соответствующую группу при помощи . Например, если нужно даты из неудобного формата ММ/ДД/ГГГГ перевести в удобный ДД.ММ.ГГГГ, то можно использовать такую регулярку:
Если групп больше 9, то можно ссылаться на них при помощи конструкции вида .
Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена. Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию. Например, «зацензурим» все слова, начинающиеся на букву «Х»:
Ссылки на группы при поиске
При помощи и можно ссылаться на найденную группу и при поиске. Необходимость в этом встречается довольно редко, но это бывает полезно при обработке простых xml и html.
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок! Регулярные выражения для этого не подходят. Используйте другие инструменты. Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок. Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы. Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае 🙂 Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом. Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
Функция python re.sub ()
Функция Re.sub () заменяет одну или много совпадений со строкой в данном тексте. Поиск и замена происходят слева направо.
В этом руководстве мы узнаем, как использовать функцию re.sub () с помощью примеров программ.
Синтаксис – Re.Sub ()
Синтаксис функции re.sub ()
re.sub(pattern, repl, string, count=0, flags=0)
где
| шаблон | Шаблон, который должен быть найден в строке. |
| рентген | Значение, которое должно быть заменено в строку вместо сопоставленного шаблона. |
| нить | Строка, в которой должна быть сделана замена. |
| считать | Максимальное количество вхождений шаблонов, которые должны быть заменены. |
| флаги | Дополнительные флаги, такие как Re.ignorecase и т. Д. |
Возвращаемое значение
Функция возвращает объект списка.
Пример 1: re.sub () – заменить сопоставления шаблона с заменой строки
В этом примере мы возьмем строку и замените шаблоны, которые содержат непрерывное возникновение чисел со строкой Отказ Мы сделаем замену, используя функцию re.sub ().
Python Program
import re
pattern = '+'
string = 'Account Number - 12345, Amount - 586.32'
repl = 'NN'
print('Original string')
print(string)
result = re.sub(pattern, repl, string)
print('After replacement')
print(result)
Выход
Original string Account Number - 12345, Amount - 586.32 After replacement Account Number - NN, Amount - NN.NN
Пример 2: re.sub () – ограничить максимальное количество замены
Мы можем ограничить максимальное количество замены функции re.sub (), указав счет дополнительный аргумент.
В этом примере мы возьмем один и тот же шаблон, строку и замену, как в предыдущем примере. Но мы ограничим максимальное количество замены на 2.
Python Program
import re
pattern = '+'
string = 'Account Number - 12345, Amount - 586.32'
repl = 'NN'
print('Original string')
print(string)
result = re.sub(pattern, repl, string, count=2)
print('After replacement')
print(result)
Выход
Account Number - 12345, Amount - 586.32 After replacement Account Number - NN, Amount - NN.32
Только два сопоставления с рисунком заменяется на замену строки. Остальные совпадения не заменяются.
Пример 3: re.sub () – Дополнительные флаги
В этом примере мы пройдем дополнительные флаги аргумента Для функции re.sub (). Этот флаг сообщает FUNCH RE 2SSUB (), чтобы игнорировать случай, когда сопоставляя шаблон в строке.
Python Program
import re
pattern = '+'
string = 'Account Number - 12345, Amount - 586.32'
repl = 'AA'
print('Original string')
print(string)
result = re.sub(pattern, repl, string, flags=re.IGNORECASE)
print('After replacement')
print(result)
Выход
Original string Account Number - 12345, Amount - 586.32 After replacement AA AA - 12345, AA - 586.32
Резюме
В этом учете примеров Python мы узнали, как использовать функцию Re.sub () для замены или замены всех совпадений для данного шаблона в строке с помощью строки замены с помощью примерных программ.
Методы
Есть несколько доступных методов использования регулярных выражений. Здесь мы собираемся обсудить некоторые из наиболее часто используемых методов, а также привести несколько примеров того, как они используются. Эти методы включают:
- re.match();
- исследовать();
- re.findall();
- re.split();
- re.sub();
- re.compile().
re.match(шаблон, строка, флаги = 0)
Это выражение используется для сопоставления символа или набора символов в начале строки
Также важно отметить, что это выражение будет соответствовать только в начале строки, если данная строка состоит из нескольких строк.. Выражение ниже вернет None, потому что Python не появляется в начале строки.
Выражение ниже вернет None, потому что Python не появляется в начале строки.
# match.py import re result = re.match(r'Python', 'It\'s easy to learn Python. Python also has elegant syntax') print(result)
$ python match.py None
re.search(шаблон, строка)
Этот модуль будет проверять совпадение в любом месте заданной строки и возвращать результаты, если они найдены, и None, если они не найдены.
В следующем коде мы просто пытаемся определить, появляется ли слово «щенок» в строке «Дейзи нашла щенка».
# search.py
import re
if re.search("puppy", "Daisy found a puppy."):
print("Puppy found")
else:
print("No puppy")
Здесь мы сначала импортируем модуль re и используем его для поиска вхождения подстроки «щенок» в строке «Дейзи нашла щенка». Если он существует в строке, возвращается объект re.MatchObject, который считается «правдивым» при оценке в операторе if.
$ python search.py Puppy found
re.compile(шаблон, флаги = 0)
Этот метод используется для компиляции шаблона регулярного выражения в объект регулярного выражения, который можно использовать для сопоставления с помощью его методов match() и search(), которые мы обсуждали выше. Это также может сэкономить время, поскольку выполнение синтаксического анализа или обработки строк регулярных выражений может быть дорогостоящим в вычислительном отношении.
# compile.py
import re
pattern = re.compile('Python')
result = pattern.findall('Pythonistas are programmers that use Python, which is an easy-to-learn and powerful language.')
print(result)
find = pattern.findall('Python is easy to learn')
print(find)
$ python compile.py
Обратите внимание, что возвращается только соответствующая строка, в отличие от всего слова в случае «Pythonistas». Это более полезно при использовании строки регулярного выражения, в которой есть специальные символы соответствия.
re.sub(шаблон, repl, строка)
Как следует из названия, это выражение используется для поиска и замены новой строки в случае появления шаблона.
# sub.py import re result = re.sub(r'python', 'ruby', 'python is a very easy language') print(result)
$ python sub.py ruby is a very easy language
re.findall(шаблон, строка)
Как вы видели до этого раздела, этот метод находит и извлекает список всех вхождений в данной строке. Он сочетает в себе функции и свойства re.search() и re.match(). В следующем примере из строки будут извлечены все вхождения «Python».
# findall.py import re result = re.findall(r'Python', 'Python is an easy to learn, powerful programming language. Python also has elegant syntax') print(result)
$ python findall.py
Опять же, использование такой строки точного соответствия действительно полезно только для определения того, встречается ли строка регулярного выражения в данной строке или сколько раз.
re.split(шаблон, строка, maxsplit = 0, flags = 0)
Это выражение разделит строку в том месте, где в строке встречается указанный шаблон. Он также вернет текст всех групп в шаблоне, если в шаблоне используется расширенная функция, такая как захват круглых скобок.
# split.py
import re
result = re.split(r"y", "Daisy found a puppy")
if result:
print(result)
else:
print("No puppy")
Как вы можете видеть выше, образец символа «y» встречается три раза, и выражение разделено во всех случаях, где оно встречается.
$ python split.py
Куда пойти отсюда?
Резюме : Вы изучили несколько способов соответствия точного слова в строке. Вы можете использовать простой оператор членства Python. Вы можете использовать Regex по умолчанию без специальных метасимволов. Вы можете использовать слово границу Metacharacter соответствовать только целым словам. Вы можете соответствовать нечувствительному случаю регистра, используя аргумент флагов Отказ Вы можете соответствовать не только одному, но все вхождению слова в строке, используя или методы. И вы можете сопоставить все строки, содержащие и не содержащие определенного слова.
Steww. Это было некоторые теоретические вещи. Вы чувствуете, что вам нужны более практичные вещи рядом?
Затем ознакомьтесь с My Tracty-Heavy Python Freelancer Course, который помогает вам подготовиться к худшему и создать второй поток дохода, создавая процветающий кодирующий боковой бизнес онлайн.