Регулярные выражения grep, egrep, sed в linux
Содержание:
- Grep IP addresses
- Синтаксис
- с GREP найдем любой текст в любом файле
- Изменение прав доступа. Команда chmod
- find — синтаксис и зачем оно нужно
- General output control
- 1.1, общая форма команды find
- Команды Linux, для работы с файлами
- Basic vs. extended regular expressions
- Регулярные выражения Linux
- Системные команды Linux
Grep IP addresses
Greping for IP addresses can get a little complex because we can’t just tell grep to look for four numbers separated by dots – well, we could, but that command has the potential to return invalid IP addresses as well.
The following command will find and isolate only valid IPv4 addresses:
$ grep -E -o "(25|2|??)\.(25|2|??)\.(25|2|??)\.(25|2|??)" /var/log/auth.log
We used this on our Ubuntu server just to see where the latest SSH attempts have been made from.
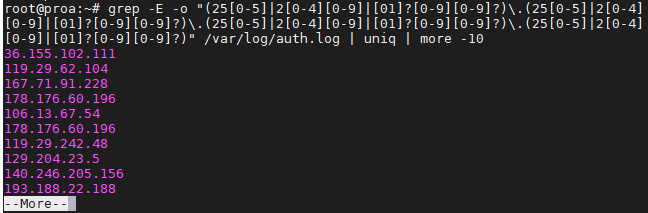
To avoid repeat information and prevent it from flooding your screen, you may want to pipe your grep commands to “uniq” and “more” as we did in the screenshot above.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*

Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*

Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test

Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root

Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»

Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file

Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file

Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
с GREP найдем любой текст в любом файле
Прежде всего мы объясним доступные варианты:
- –i: не будет различать верхний и нижний регистр.
- –w: заставить его находить только определенные слова.
- –v: выбирает строки, которые не совпадают.
- –n: показывает номер строки с запрошенными словами.
- –h: удаляет префикс из имени файла Unix в выводе.
- –r: рекурсивный поиск в каталогах.
- –R: как -r, но следуйте всем символическим ссылкам.
- –l: показывает только имена файлов с выделенными строками.
- –c- Показывает только одно количество выбранных строк для каждого файла.
- -Цвет: Отображает совпадающие шаблоны в цветах.
На изображении, которое вы указали в заголовке этой статьи, я искал слово «Изображения» в файле «830.desktop», который находится по этому пути. Как видите, я написал:
grep Imágenes /home/pablinux/Documentos/830.desktop
Имейте в виду, что в этой статье мы напишем примеры, которые необходимо изменить в соответствии с нашими поисковыми предпочтениями. Когда мы говорим «Файл», «Слово» и т. Д., Мы будем ссылаться на файл с его путем.. Если бы я просто написал «grep Images 830.desktop», я бы получил сообщение о том, что файл не существует. Или так было бы, если бы файл не находился в корневом каталоге.
Другие примеры:
- grep -i images /home/pablinux/Documentos/830.desktop, где «изображения» — это слово, которое мы хотим найти, а остальное — файл с его путем. В этом примере выполняется поиск «изображений» в файле «830.desktop» без учета регистра.
- grep -R изображения: он будет искать во всех строках каталога и всех его подкаталогах, где найдено слово «изображения».
- grep -c пример test.txt: это будет искать нас и показывать общее количество раз, когда «example» появляется в файле с именем «test.txt».
Изменение прав доступа. Команда chmod
Представим, что вы не хотите, чтобы ваш коллега видел ваши личные изображения. Это может быть достигнуто путем изменения прав доступа к файлам с помощью команды (сокр. от «change mode»). Используя эту команду, мы можем установить права доступа (Чтение, Запись, Выполнение) к файлу/каталогу для Владельца, Группы и всех Остальных пользователей.
Синтаксис команды следующий:
Существует два способа использования команды : символьный и числовой.
Использование команды chmod в символьном режиме
Чтобы задать параметры разрешений для каждой отдельной категории пользователей, применяются следующие символы:
— владелец;
— группа;
— остальные пользователи;
— для всех трех категорий (Владелец + Группа + Остальные).
А также используются следующие математические символы:
— добавление разрешений;
— удаление разрешений;
— переопределение существующих разрешений новым значением.
Теперь, когда вы знаете, как это работает, давайте попробуем использовать команду в символьном режиме и установим новые разрешения для ранее упомянутого файла Адреса.txt следующим образом:
чтение, запись и выполнение для Владельца;
чтение и запись для членов Группы;
чтение для Остальных пользователей.
В результате мы получаем:
Как видите, права доступа к файлу изменились с на , что нам и требовалось.
А если мы теперь хотим убрать разрешение на чтение файла для пользователей, не входящих в нашу группу и не являющихся владельцем файла, то достаточно выполнить следующее:
Результат:
Права доступа к файлу изменились с на .
Подумав, мы решаем дать полные права (за исключением права на выполнение) абсолютно всем пользователям системы, и выполняем команду:
Результат:
Права доступа к файлу изменились с на . Все пользователи могут читать и изменять наш файл, но ни у кого нет права на его выполнение.
Использование команды chmod в числовом режиме
Другой способ указать права доступа к файлу — применить команду в числовом режиме. В этом режиме каждое разрешение файла представлено некоторым числом (в восьмеричной системе счисления):
(чтение/просмотр) = 4
(запись/изменение) = 2
(выполнение) = 1
(не задано) =
Допускается объединение данных числовых значений, и таким образом одно число может использоваться для представления всего набора разрешений. В следующей таблице приведены цифры для всех типов разрешений:
| Число | Тип разрешения | Символ |
| Нет разрешения | −−− | |
| 1 | Выполнение | −−x |
| 2 | Запись | −w− |
| 3 (2+1) | Запись + Выполнение | −wx |
| 4 | Чтение | r−− |
| 5 (4+1) | Чтение + Выполнение | r−x |
| 6 (4+2) | Чтение + Запись | rw− |
| 7 (4+2+1) | Чтение + Запись + Выполнение | rwx |
Поскольку вы должны определить разрешения для каждой категории пользователей (Владелец, Группа, Остальные), команда будет включать в себя три числа (каждое из которых представляет собой сумму привилегий).
В качестве примера, давайте посмотрим на наш файл Адреса.txt, права которого, я напомню, мы сконфигурировали (в символьном режиме) с помощью команды:
Те же параметры разрешений, но уже в числовом формате, можно определить следующим образом:
Теперь поменяем разрешения файла так, чтобы Владелец мог читать и писать, Группа — только читать, а у Остальных — вообще не было прав на доступ. Судя по вышеприведенной таблице, для Владельца числовое представление прав доступа соответствует числу (), для Группы — числу (), а для Остальных — (). В совокупности должно получиться ():
Результат:
Как видите, права изменились с на , этого мы и хотели.
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
-regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);

Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.
General output control
| -c, —count | Instead of the normal output, print a count of matching lines for each input file. With the -v, —invert-match option (see below), count non-matching lines. |
| —color[=WHEN],—colour[=WHEN] | Surround the matched (non-empty) strings, matching lines, context lines, file names, line numbers, byte offsets, and separators (for fields and groups of context lines) with escape sequences to display them in color on the terminal. The colors are defined by the environment variable GREP_COLORS. The older environment variable GREP_COLOR is still supported, but its setting does not have priority. WHEN is never, always, or auto. |
| -L,—files-without-match | Instead of the normal output, print the name of each input file from which no output would normally be printed. The scanning stops on the first match. |
| -l,—files-with-matches | Instead of the normal output, print the name of each input file from which output would normally be printed. The scanning stops on the first match. |
| -m NUM,—max-count=NUM | Stop reading a file after NUM matching lines. If the input is standard input from a regular file, and NUM matching lines are output, grep ensures that the standard input is positioned after the last matching line before exiting, regardless of the presence of trailing context lines. This enables a calling process to resume a search. When grep stops after NUM matching lines, it outputs any trailing context lines. When the -c or —count option is also used, grep does not output a count greater than NUM. When the -v or —invert-match option is also used, grep stops after outputting NUM non-matching lines. |
| -o, —only-matching | Print only the matched (non-empty) parts of a matching line, with each such part on a separate output line. |
| -q, —quiet, —silent | Quiet; do not write anything to standard output. Exit immediately with zero status if any match is found, even if an error was detected. Also see the -s or —no-messages option. |
| -s, —no-messages | Suppress error messages about nonexistent or unreadable files. |
1.1, общая форма команды find
Общая форма команды find, приведенная в документе man:
на самом делеЭти параметры обычно не используются (по крайней мере, в моей повседневной работе, я не использовал их), общая форма приведенной выше команды поиска может быть упрощена до:
| команда | Описание |
|---|---|
| path | Путь к каталогу, который ищется командой find. Например, используйте. Для представления текущего каталога и / для представления корневого каталога системы. |
| expression | Выражение можно разделить на |
| -options | Укажите общие параметры команды find, подробно описанные в следующем разделе. |
| Команда find выводит сопоставленные файлы на стандартный вывод | |
| -exec | Команда find выполняет команду оболочки, заданную этим параметром для соответствующего файла. Соответствующая команда имеет вид,нотас участиемПространство между |
| -ok | Он имеет тот же эффект, что и -exec, за исключением того, что команда оболочки, заданная этим параметром, выполняется в более безопасном режиме.Перед выполнением каждой команды будет выдано приглашение, позволяющее пользователю определить, выполнять ли ее. |
пример 1:Удалить файлы с нулевым размером файла
(Вы также можете сделать это: rm -i Или найдите ./ -size 0 | xargs rm -f &)
Пример 2:Чтобы вывести список соответствующих файлов с помощью команды ls -l, вы можете поместить команду ls -l в опцию -exec команды find:
Пример 3:В каталоге / logs найдите файлы, время изменения которых составляет до 5 дней, и удалите их:
Пример 4:Найдите в текущем каталоге все файлы, имена которых заканчиваются на .conf и время изменения которых превышает 5 дней, и удалите их, но перед удалением выведите подсказку.
Некоторые люди также описывают структуру команды find следующим образом:
Команды Linux, для работы с файлами
Эти команды используются для обработки файлов и каталогов.
33. ls
Очень простая, но мощная команда, используемая для отображения файлов и каталогов. По умолчанию команда ls отобразит содержимое текущего каталога.
34. pwd
Linux pwd — это команда для показывает имя текущего рабочего каталога. Когда мы теряемся в каталогах, мы всегда можем показать, где мы находимся.
Пример ример ниже:
35. mkdir
В Linux мы можем использовать команду mkdir для создания каталога.
По умолчанию, запустив mkdir без какой-либо опции, он создаст каталог в текущем каталоге.
36. cat
Мы используем команду cat в основном для просмотра содержимого, объединения и перенаправления выходных файлов. Самый простой способ использовать cat— это просто ввести » имя_файла cat’.
В следующих примерах команды cat отобразится имя дистрибутива Linux и версия, которая в настоящее время установлена на сервере.
37. rm
Когда файл больше не нужен, мы можем удалить его, чтобы сэкономить место. В системе Linux мы можем использовать для этого команду rm.
38. cp
Команда Cp используется в Linux для создания копий файлов и каталогов.
Следующая команда скопирует файл ‘myfile.txt» из текущего каталога в «/home/linkedin/office«.
39. mv
Когда вы хотите переместить файлы из одного места в другое и не хотите их дублировать, требуется использовать команду mv.
40.cd
Команда Cd используется для изменения текущего рабочего каталога пользователя в Linux и других Unix-подобных операционных системах.
41. Ln
Символическая ссылка или программная ссылка — это особый тип файла, который содержит ссылку, указывающую на другой файл или каталог. Команда ln используется для создания символических ссылок.
Команда Ln использует следующий синтаксис:
42. touch
Команда Touch используется в Linux для изменения времени доступа к файлам и их модификации. Мы можем использовать команду touch для создания пустого файла.
44. head
Команда head используется для печати первых нескольких строк текстового файла. По умолчанию команда head выводит первые 10 строк каждого файла.
45. tail
Как вы, возможно, знаете, команда cat используется для отображения всего содержимого файла с помощью стандартного ввода. Но в некоторых случаях нам приходится отображать часть файла. По умолчанию команда tail отображает последние десять строк.
46. gpg
GPG — это инструмент, используемый в Linux для безопасной связи. Он использует комбинацию двух ключей (криптография с симметричным ключом и открытым ключом) для шифрования файлов.
50. uniq
Uniq — это инструмент командной строки, используемый для создания отчетов и фильтрации повторяющихся строк из файла.
53. tee
Команда Linux tee используется для связывания и перенаправления задач, вы можете перенаправить вывод и/или ошибки в файл, и он не будет отображаться в терминале.
54. tr
Команда tr (translate) используется в Linux в основном для перевода и удаления символов. Его можно использовать для преобразования прописных букв в строчные, сжатия повторяющихся символов и удаления символов.
Basic vs. extended regular expressions
In basic regular expressions the metacharacters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{, \|, \(, and \).
Traditional versions of egrep did not support the { metacharacter, and some egrep implementations support \{ instead, so portable scripts should avoid { in grep -E patterns and should use to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification. For example, the command grep -E ‘{1’ searches for the two-character string {1 instead of reporting a syntax error in the regular expression. POSIX allows this behavior as an extension, but portable scripts should avoid it.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- {n} — указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- — любой символ, кроме тех, что указаны в скобках;
- — любой символ из указанного диапазона;
- — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Системные команды Linux
Эти команды используются для просмотра информации и управления, связанной с системой Linux.
1. uname
Команда Uname используется в Linux для поиска информации об операционных системах. В Uname существует много опций, которые могут указывать имя ядра, версию ядра, тип процессора и имя хоста.
Следующая команда uname с опцией отображает всю информацию об операционной системе.
2. uptime
Информация о том, как долго работает система Linux, отображается с помощью команды uptime. Информация о времени безотказной работы системы собирается из файла ‘/proc/uptime‘. Эта команда также отобразит среднюю нагрузку на систему.
Из следующей команды мы можем понять, что система работает в течение последних 36 минут.
3. hostname
Вы можете отобразить имя хоста вашей машины, введя в своем терминале. С помощью опции вы можете просмотреть ip-адрес компьютера. А с помощью параметра вы можете просмотреть доменное имя.
4. last
Команда last в Linux используется для определения того, кто последним вошел в систему на вашем сервере. Эта команда отображает список всех пользователей, вошедших (и вышедших) из «/var/log/wtmp » с момента создания файла.
Вам просто нужно ввести «last» в своем терминале.
5. date
В Linux команда date используется для проверки текущей даты и времени системы. Эта команда позволяет задать пользовательские форматы для дат.
Например, используя «date +%D«, вы можете просмотреть дату в формате «ММ/ДД/ГГ«.
6. cal
По умолчанию команда cal отображает календарь текущего месяца. С помощью опции вы можете просмотреть календарь на весь год.
9. reboot
Команда reboot используется для перезагрузки системы Linux. Вы должны запустить эту команду из терминала с правами суперпользователя sudo.
10. shutdown
Команда shutdown используется для выключения или перезагрузки системы Linux. Эта команда позволяет планировать завершение работы и уведомлять пользователей сообщениями о выключении и перезагрузке.
По умолчанию компьютер (сервер) выключится через 1 минуту. Вы можете отменить расписание, выполнив команду:
Немедленное отключение тоже возможно, для этого используется опция «now»