Что такое семантическое ядро, зачем оно нужно и как его составить
Содержание:
- Транзакционные запросы:
- Этап 1. Сбор вариаций написания продукта и маркеров
- Информационные запросы:
- 7Search
- Бесплатный парсинг запросов конкурентов
- Формируем черновую структуру сайта
- Как группировать запросы
- Автоматический сбор и очистка СЯ
- Наложение семантического ядра на структуру сайта
- Сервисы для парсинга и кластеризации семантического ядра
- Что такое семантическое ядро простыми словами
Транзакционные запросы:
Это наиболее интересный вид запросов. Они говорят нам о том, что люди ищут сайт, на котором смогут совершить то или иное действие: купить, скачать и т.д. Данный вид запросов в основном используется в интернет магазинах, либо на сайтах, предоставляющих услуги.
Эти запросы зачастую весьма конкурентны, при этом именно они приносят целевую аудиторию на ваш сайт. Если вы продвигаете какую-либо страницу по транзакционному запросу, то на этой странице обязательно должно быть выполнено условие, что пользователь сможет совершить свою транзакцию.
Ответом на вопрос о том, стоит ли использовать транзакционные запросы на информационных сайтах, будет — стоит. Но, как я уже говорил выше, на этой странице вы должны предложить пользователю действие: либо это будет релевантная контекстная реклама, либо это вывод его на партнерскую программу.
Этап 1. Сбор вариаций написания продукта и маркеров
Перед сбором запросов необходимо выявить все возможные варианты написания продвигаемого продукта, а также маркеры (свойства). Для этого мы используем сервис подбора слов Яндекса.
Методика
Вписываем название нашего продукта в поисковую строку и нажимаем кнопку «Подобрать».
Детально просматриваем запросы из правой колонки полученных результатов и выявляем синонимы или иные варианты нашего запроса.
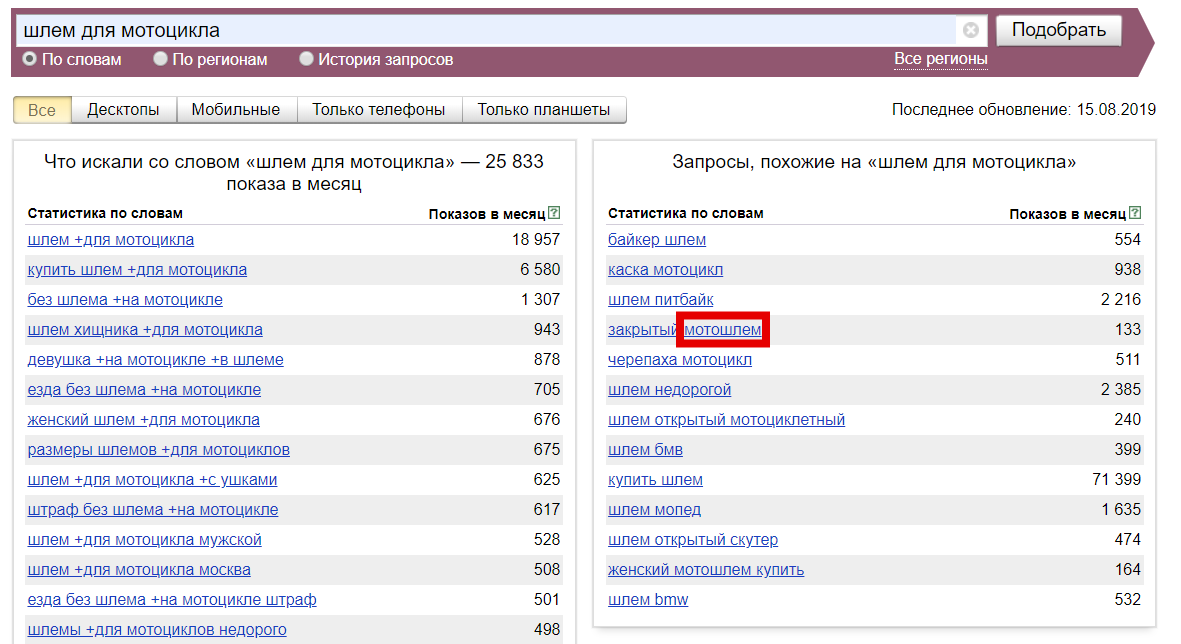
Переносим все найденные варианты названия продукта в отдельный файл.

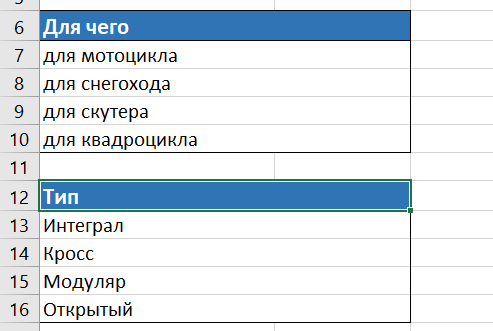
На следующем шаге следует собрать маркеры, то есть свойства, определяющие продукт. Данные маркеры можно объединить по типам схожих свойств, например, Цвет, Бренд, Тип и иных.
Для выявления маркеров есть два пути:
1.Сбор и последующая чистка всей семантики по названию продукта, например, «Мотошлем».
1.1. Плюс: Сбор всех существующих в спросе маркеров;
1.2. Минус: Долгий и трудозатратный процесс.
2. Поиск и анализ страниц конкурентов в ТОП 10, которые уже имеют страницы с нашим продуктом.
2.1. Плюс: Быстрый процесс;
2.2. Минус: Неполный сбор свойств, если они отсутствуют у конкурентов.
Используя второй вариант, находим сайты конкурентов по запросам названия продукта, взяв страницы из ТОП 10
Это возможно сделать вводом основного запроса прямо в поисковую систему или же воспользоваться инструментом полноценного поиска конкурентов по видимости их сайтов, как было рассказано в 4 пункте первого этапа данной статьи.
На странице конкурента, нужно обратить внимание на структуру категории, то есть существуют ли подкатегории, или посмотреть функционал фильтрации товаров. В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры
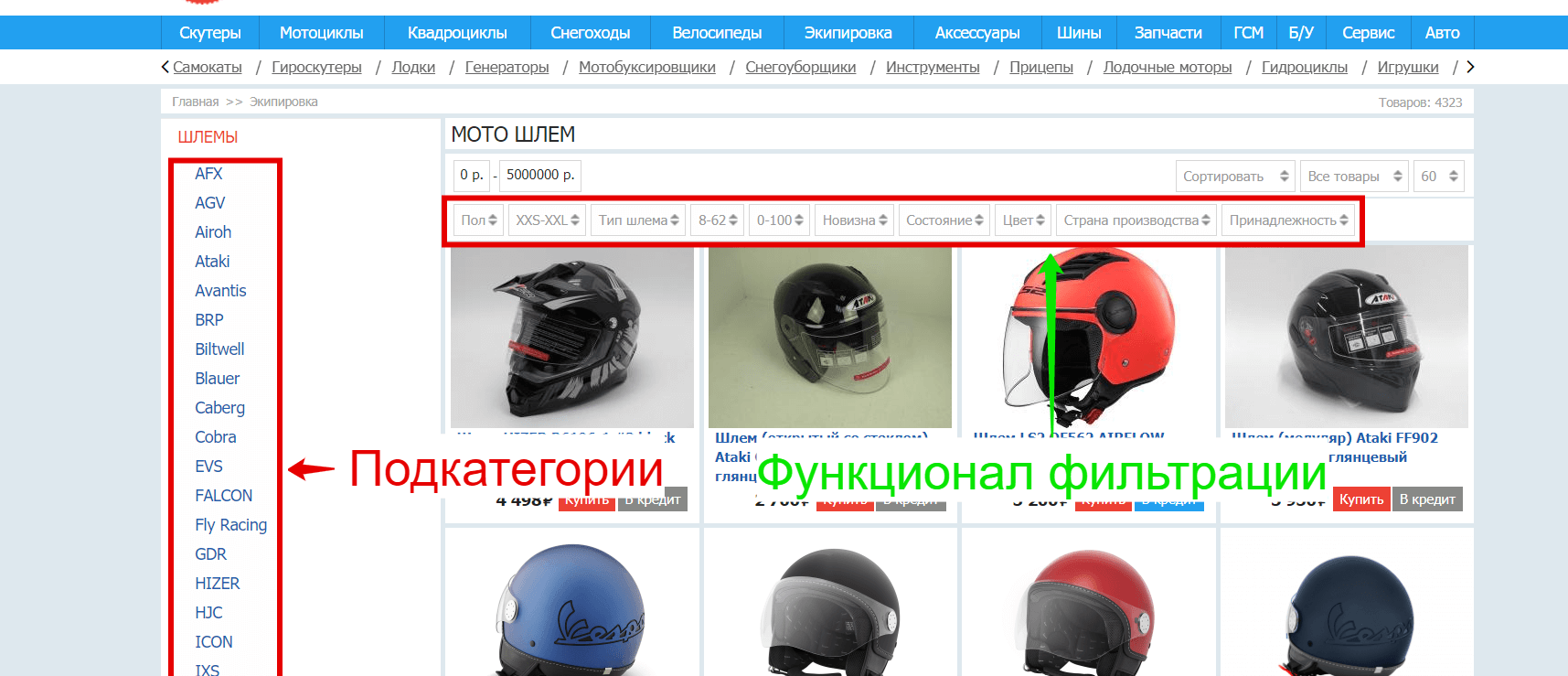
Копируем подкатегории и/или маркеры, которые нас интересуют, то есть то, что действительно есть у продвигаемого сайта в ассортименте, и выносим в наш файл:
Следующим шагом сцепляем все варианты написания нашего продукта с маркерами, чтобы получить различные запросы для последующего сбора семантического ядра уже по ним. Рекомендуем использовать функцию «СЦЕПИТЬ» в Microsoft Excel. В результате получим таблицу, аналогичную представленной ниже:
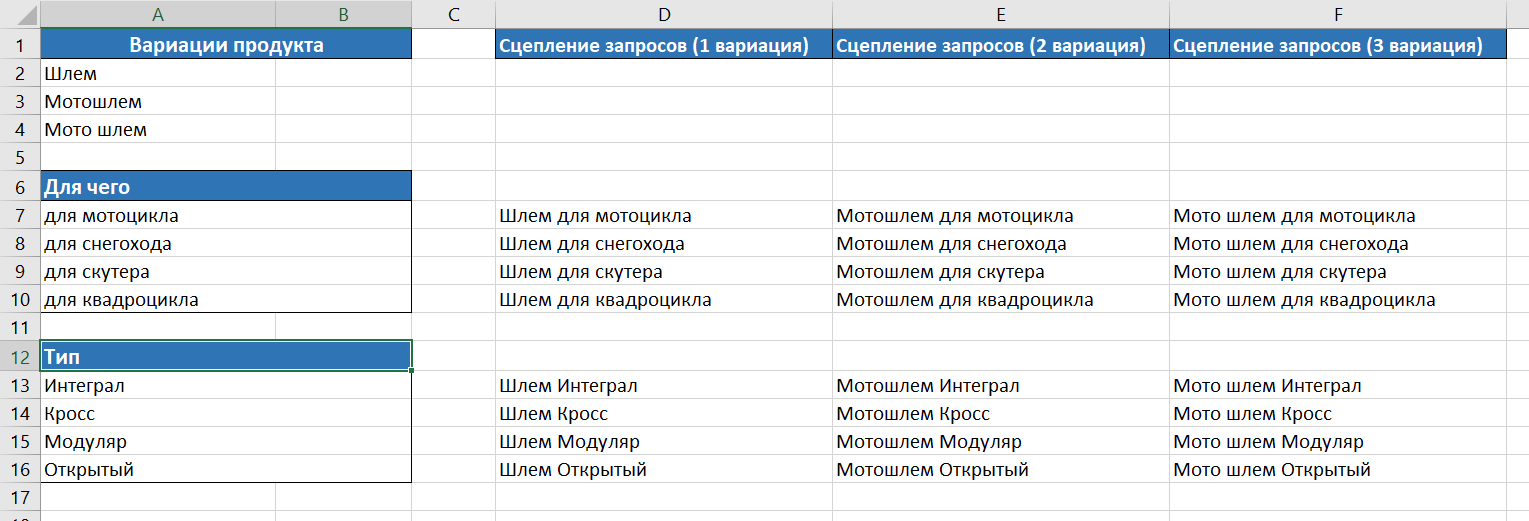
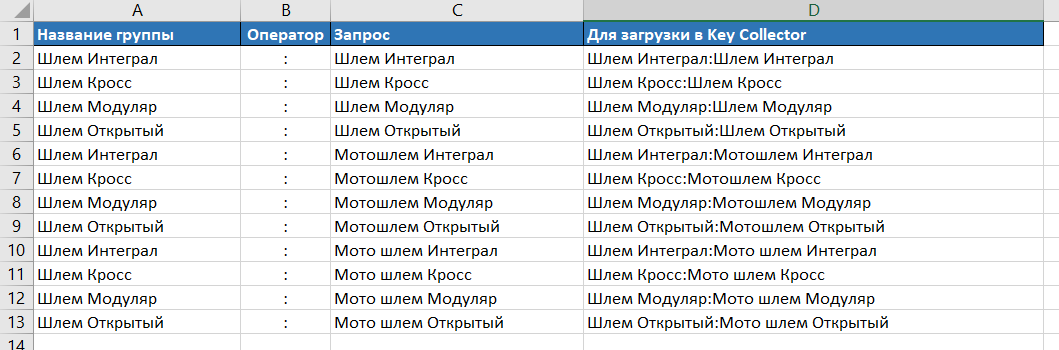
Для пакетной (разовой) загрузки всех ключевых слов в KeyCollector следует опять воспользоваться функцией «СЦЕПИТЬ» (формируем запросы в формате «Группа:Ключ»). Таким образом мы сможем разом добавить все запросы в единое поле программы, которая в свою очередь создаст необходимые группы и добавит в них соответствующие запросы для расширения ядра. Итоговый список запросов в необходимом формате:
Информационные запросы:
Данный вид запросов используется, когда человек ищет ответ на поставленный вопрос. Он будет переходить на все сайты из ТОПа выдачи, пока не найдет, как посчитает, исчерпывающий и достоверный ответ на свой вопрос.
Все информационные запросы несут в себе вопрос, и обычно начинаются со слов: «как», «где», «почему», «сколько» и т.д. «Отзывы», «советы», «инструкции» — данные слова тоже относятся к информационным запросам. Под каждый информационный запрос рекомендуется создавать отдельную страницу на сайте. Информационные запросы на некоммерческих сайтах составляют наибольшую долю в трафике, благодаря этим запросом можно хорошо монетезировать свой ресурс за счет контекста или тизеров.
7Search
Ранее 7search.com гордо называлась одной из наиболее крупных сетей PPC-рекламы. Некоторые специалисты пользуются ей до сих пор. Но это является скорее исключением, чем правилом. Система имеет простой и удобный функционал подбора ключей. Результаты основаны на своих данных рекламной сети, которые она имеет в достаточном количестве.
Даже людям, предпочитающим работать с «Планировщиком ключевых слов», советуют пользоваться сторонними инструментами. В некоторых случаях это позволяет существенно расширить или сузить семантику ресурса и занять более высокие позиции в выдаче.
Бесплатный парсинг запросов конкурентов
Чтобы парсить конкурентов, их надо знать. В анализе ниш я уже рассказывал, как определить своих конкурентов.
Выписываем всех ваших конкурентов, если вы еще этого не сделали. Надо брать только прям точных конкурентов. Например, у вас сайт по диабету, вам надо брать только сайты по диабету. Сайты, которые посвящены всей медицине с разделом диабета не подойдут, потому что у вас напарсятся другие разделы сайта, которые посвящены не диабету, и вы запаритесь их чистить.
Wizard.Sape
Заходите в KeyCollector во вкладку Wizard.Sape. Выбираем анализ доменов. Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор.
Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор. После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
Так же можно еще собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Megaindex
Заходим в KeyCollector во вкладку Megaindex. Вводим логин и пароль, указываем Москва, потому что Россию нельзя указать. Выбираем последнюю дату, раньше можно было парсить за весь период, но сейчас почему-то не работает, можно выбирать только определенную дату. Вбиваем домены конкурентов. И начинаем парсинг.
Rookee
Выбираем Rookee в Keycollector, составление семантического ядра. Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Можно отдельно собрать по Яндексу, потом по Гуглу. Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Top.Mail.ru
Здесь все сложнее. Необходимо перейти в рейтинг https://top.mail.ru/, и там найти ваших конкурентов с открытым счетчиком. Обычно что-то узконишевое там сложно найти, но все равно расскажу про этот способ для общего кругозора.
Вводим вашу тематику в поле поиска рейтинга. Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта.
Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта. Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id.
Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id. В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года.
В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года. Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Так же можно спарсить глобальный рейтинг top.mail по ключевым словам, в той же самой вкладке в KeyCollector.
На этом бесплатный сбор ключевых слов у конкурентов закончен. Теперь его надо очистить и оставить только нужное.
В итоге получаем готовый список ключевых слов конкурентов, которыми можем дополнить наше ядро.
Формируем черновую структуру сайта
Первым делом мы готовим черновую структуру сайта, которую в дальнейшем будем расширять на основании собранной семантики и анализа конкурентов.
Если сайт в разработке:
- просим описать в брифе особенности бизнеса;
- просим отправить выгрузку товаров в табличном формате (.xls или Google Таблицы).
После получения брифа и выгрузки товаров мы изучаем полученные данные и готовим черновую структуру сайта с учетом служебных страниц: «О нас», «Контакты», «Доставка и оплата», «Вопросы и ответы».
Если сайт готов:
- переносим текущую структуру сайта в рабочий документ (Google Таблицы);
- изучаем продукцию сайта, создаем дополнительные категории, подкатегории и фильтры на основе названий товаров.
Например, на одном из проектов в категории «Защита от бытовых вредителей» мы обнаружили разные типы товаров:
Поэтому для них создали дополнительные категории:
- cпирали от комаров:
- москитные сетки;
- липкие ленты;
- липкие листы;
- палочки от комаров;
- мухобойки;
- ловушки.
При работе со структурой существующего сайта мы выделяем новые категории зеленым цветом. Так лучше видны новые категории и масштабы расширения структуры.
При создании черновой структуры кроме категорий / подкатегорий мы также добавляем типы и значения фильтров. Хорошо проработанную черновую структуру легче и быстрее расширить, чем кластеризовать «сырые» данные.
1.1. Составляем список конкурентов
Если работаем с существующим сайтом, определяем его основных конкурентов с помощью сервиса Serpstat:
1.1.1. В строке поиска указываем сайт.
1.1.2. Выбираем поисковую систему и регион.
1.1.3. Переходим в раздел «SEO-анализ» — «Конкуренты».
1.1.4. Сортируем по количеству общих фраз.
В итоге получаем список основных конкурентов:
Если оптимизируем новый сайт или по сайту еще нет достаточного количества информации в Serpstat, переходим к анализу лидеров в отдельных категориях. Для этого вместо домена в Serpstat задаем поисковую фразу. Например, список конкурентов для категории «Удобрения»:
Эти данные пригодятся при работе с существующим сайтом, потому что мы будем знать лидеров в отдельных нишах.
Все полученные данные сохраняем для дальнейшей обработки. Для этого выгружаем данные через «Экспорт»:
После выгрузки конкурентов исключаем все информационные сайты и оставляем только коммерческие:
1.2. Анализируем структуру конкурентов
На этом этапе мы детально изучаем структуру конкурентов: их категории и фильтры. Если у них есть интересные элементы, добавляем в структуру для дальнейшего изучения.
Например, на сайте одного из конкурентов в категории «Инсектициды» были обнаружены фильтры:
- для защиты от;
- для защиты культуры.
Эти фильтры также добавили в черновую структуру:
Как группировать запросы
Чтобы понять, как распределять ключевые слова по отдельным страницам, нужно сгруппировать запросы. Для этого надо создать семантические кластеры.
Чаще всего, ключевые слова из кластеров первого и второго уровней определяются еще на этапе мозгового штурма. Для этого просто нужно хорошо разбираться в своем продукте или ориентироваться на структуру сайтов-конкурентов. Семантика остальных подуровней определяется на этапе детального составления семантического ядра и его кластеризации
Еще одно важное условие — каждая группа запросов последнего уровня должна соответствовать одной потребности пользователя. Например, покупка конкретного вида детского белья
Используем Словоёб с уже известной нам функцией быстрого фильтра. С его помощью можно легко отсортировать фразы по категориям для дальнейшего внедрения на посадочных страницах.
1. Введите в поле быстрого фильтра базовое ключевое слово, которое может станет названием для категории/подкатегории/посадочной страницы (например, бренд детского постельного белья «Непоседа») и нажмите Enter.
2. Выделите нужные фразы и скопируйте их.
3. Удалите отмеченные строки правой кнопкой мыши.
4. Создайте в правом меню новую группу (например, с названием «Непоседы»).
5. Для добавления только что выбранных фраз в эту группу, перейдите во вкладку «Данные» — «Добавить фразы».
6. Вернитесь к прежнему списку нажатием клавиши Enter в поле поиска быстрого фильтра.
7. Повторите эту процедуру с другими запросами. Ключевые фразы автоматически выстроятся в алфавитном порядке, благодаря чему можно легко удалить лишние слова или выделить похожие фразы в отдельную группу.
Группировка вручную требует много времени (особенно в том случае, если семантика достаточно широкая). Для автоматизации этого процесса можно использовать платные Key Collector, Rush-Analytics, Just-Magic, или бесплатный скрипт Devaka.ru. Часто приходится объединять некоторые группы запросов. Например, такие:
Согласитесь, создавать две отдельные категории под фразы «красивое белье» и «стильное белье» неразумно 🙂 Для понимания важности фраз для каждой категории/посадочной страницы, скопируйте их в Планировщик ключевых слов Google в раздел «Получение статистики запросов и трендов»:
Так вы проверяете популярность (частотность) поискового запроса. В целом все поисковые запросы делятся на:
- ВЧ-запросы (высокочастотные).
- СЧ-запросы (среднечастотные).
- НЧ-запросы (низкочастотные).
- Микро НЧ-запросы.
При этом нет точных цифр, по которым можно с уверенностью сказать, что запрос принадлежит к определенной группе. Все зависит от тематики сайта. В одних тематиках фраза с частотностью 1000 запросов в месяц может быть низкочастотной (фильмы, музыка), в других — 200 запросов уже может быть признаком высокочастотной фразы (финансовая тематика). Соотношение этих групп: Наиболее высокочастотные запросы впоследствии вписывайте в метатеги. А под низкочастотные оптимизируйте страницы сайта. Как правило, они очень низкоконкурентны, и достаточно провести качественную работу с текстами, чтобы вывести соответствующие страницы в ТОП.
Читайте, как привлечь целевой трафик на сайт с помощью формирования максимально широкого семантического ядра.
После всех этих манипуляций вы получите подробную структуру сайта, состоящую из ключевых фраз для:
Автоматический сбор и очистка СЯ
Вы собрали все маркерные запросы, теперь можно приступать к сбору семантического ядра, который состоит из нескольких этапов.
- Сбор ключевых фраз из левой и правой колонки Wordstat.
-
Сбор поисковых подсказок и запросов из нижней части выдачи Яндекс.
Чаще всего для этих двух пунктов используется программа Key Collector, правда, у некоторых крупных компаний есть свои внутренние разработки. -
Сбор подсказок из YouTube.
Это значительно расширит количество ключевых фраз. На данный момент можно воспользоваться бесплатным инструментом от Pixel Tools или платным от Rush Analytics. -
Сбор ключевых фраз с сайтов основных конкурентов.
Для этой цели существует масса условно-бесплатных и платных инструментов: Bukvarix, Spywords, Serpstat и другие.
Не пугайтесь огромного количества ключей после сбора ключевых фраз и подсказок — всё не так страшно. Очищать семантику сначала нужно в автоматическом режиме, при помощи стоп-слов и специальных правил фильтрации в программе Key Collector. В ней можно отделить от своего ядра запросы с «точной частотностью» = 0 или по другому условию, в зависимости от сезонности и необходимого количества ключевых фраз.
Ключевые фразы удаляются по критериям:
- опечатки и лишние символы в запросе;
- запросы с нулевой точной частотностью — необязательно удалять совсем, так как они бывают полезны при дальнейшем продвижении из-за фактора сезонности;
- запросы с названием товарных позиций/моделей, которых нет на сайте;
- одинаковые запросы, но с разным окончанием;
- навигационные запросы для других сайтов;
- запросы, включающие название страниц или услуг, которых нет на сайте — например: инструкция, отзывы, рассрочка, б/у, видео;
- запросы для другой тематики;
- запросы для других городов, регионов;
- неявные дубли.
Бо́льшая часть ненужных слов удаляется автоматически, а дальше потребуется кропотливая ручная работа. Многие специалисты пользуются инструментом «Анализ групп» в Key Collector, чтобы ускорить процесс.
На примере нашего кейса охранной тематики — после сбора семантики количество ключевых фраз было более 42 тысяч, после очистки осталось всего 924.
Наложение семантического ядра на структуру сайта
Чтобы из всего полученного списка вышел толк, нужно распределить запросы (в зависимости от частоты) по структуре сайта. Назвать конкретные цифры здесь сложно, так как масштабы и разница частотности может оказаться весьма значительной для разных проектов.
Если, к примеру, за основу вы берете запрос с миллионной частотностью, даже фраза с 10 000 запрос покажется уже средненькой.
С другой стороны, когда ваш основной запрос – 10 000 частоты, среднечастотник составит порядка 5 000 запросов в месяц. Т.е. учитывается некая относительность:
«ВЧ – СР – НЧ» или «Максимум – Середина – Минимум»
Но в любом случае (даже визуально) вам нужно разделить все ядро на 3 категории:
- высокочастотные запросы (ВЧ — короткие фразы с максимальной частотой);
- низкочастотные запросы (НЧ — редко запрашиваемые фразы и словосочетания с малой частотой);
- среднечастотные запросы (СЧ — все средние запросы, оказавшиеся по середине вашего списка.
На следующем этапе подпирается 1 или несколько (максимум 3) запроса для главной страницы. Эти фразы должны быть максимально высокой частоты. На главную помещаются высокочастотники!
Далее из общей логики семантического ядра стоит выделить несколько главных ключевых фраз, из которых будут созданы разделы (категории) сайта. Здесь вы могли бы также использовать высокочастотники с меньшей частотой, чем основной, или лучше – среднечастотные запросы.
Низкочастотные оставшиеся фразы сортируются на категории (под созданные разделы и категории), превращаются в темы для будущих публикаций сайта. Но это проще понять на примере.

ПРИМЕР
Наглядный пример использования семантического ядра на практике:
1. Главная страница (ВЧ) – высокочастотный запрос — «продвижение сайта».
2. Страницы разделов (СЧ) – «продвижение сайта на заказ», «самостоятельное продвижение», «продвижение сайта статьями», «раскрутка сайта ссылками». Или же просто (если адаптировать для меню):
Раздел №1 — «на заказ»
Раздел №2 – «самостоятельно»
Раздел №3 – «статейное продвижение»
Раздел №4 – «ссылочное продвижение»
Все это очень похоже на структуру данных в вашем компьюете: логический диск (главная) — папки (разделы) — файлы (статьи).
3. Страницы статей и публикаций (НЧ) – «быстрая раскрутка сайта бесплатно», «продвижение на заказ дешево», «как продвигать сайт статьями», «раскрутка проекта в Интернете на заказ», «недорогое продвижение сайта ссылками» и т.д.
В этом списке у вас окажется самое большое количество разнообразнейших фраз и словосочетаний, по которым вы должны будете создавать дальнейшие публикации сайта.

Сервисы для парсинга и кластеризации семантического ядра
Для сбора и кластеризации семантики есть много платных и бесплатных инструментов. Мы уже упоминали несколько сервисов и сейчас остановимся на них подробнее.
Key Collector
Автоматизированный сервис для подбора семантического ядра. Умеет собирать ключи через «Яндекс.Вордстат», парсить поисковые подсказки, выгружать данные с Google Ads и сервисов аналитики, чистить семантику от стоп-слов, дублей и сезонных запросов, делать фильтрацию по частотности. Частотность Key Collector собирает в Yandex Direct, Google Ads, LiveInternet, Rambler Adstat и APIShop.com.
Главные достоинства Key Collector — разнообразные источники парсинга, большая глубина сбора, возможность группировки собранной базы. Из минусов SEO специалисты отмечают медленную работу, особенно при увеличенной глубине сбора, и необходимость покупки антикапч.

Интерфейс Key Collector
Программа платная, работает по лицензии. Стоимость лицензии зависит от статуса покупателя: физическому лицу бессрочная лицензия обойдется в 2 200 рублей, организации придется заплатить 2 300 рублей.
MOAB.Tools Семантика
Это онлайн-сервис, который парсит до четырех миллионов фраз в час и собирает для семантического ядра запросы из Wordstat и подсказок, в том числе запросы с длинным полным хвостом спецификаторов. При поиске нет проблем с капчей, можно выбрать регионы, найти ультранизкочастотные запросы и интегрировать результат с Key Collector. Удобно, что сервис сразу проверяет частотность.

Работа парсера MOAB.Tools
Инструмент платный, но в тарифе Free первые 5 000 фраз можно собрать бесплатно. Тариф Mini стоит 1 299 рублей и рассчитан на ядро до 50 000 фраз. Для крупных проектов разработан тариф Pro, с которым за 6 099 рублей можно найти до 500 000 фраз.
«Словоеб»
Сервис позиционируется как бесплатная альтернатива Key Collector. У программы похожий интерфейс и принцип работы, но возможности парсинга ограничены результатами «Вордстат», Rambler.Adstat и поисковыми подсказками «Яндекс» и Google. Частотность фраз программа тоже проверяет только по «Вордстат».

Работа программы «Словоеб»
По сути, «Словоеб» выполняет базовую работу по сбору семантики в «Яндекс.Вордстат», но в автоматическом режиме. За 10-15 минут он собирает несколько тысяч запросов, что в разы быстрей ручного сбора.
Yandex Wordstat Assistant
Браузерное расширение для упрощения работы с «Вордстат». Бесплатный сервис, который копирует и сохраняет ключевые слова из «Яндекс.Вордстат» в таблицы Excel. Умеет сортировать запросы по частотности, алфавиту или порядку добавления. Автоматически ищет дубли и позволяет добавлять ключи вручную.

Составление семантического ядра с помощью браузерного расширения
Расширение бесплатное, устанавливается для Google Chrome, Opera, Mozilla Firefox и «Яндекс.Браузер».
Serpstat
Мультиинструментальный сервис для работы с семантическим ядром, кластеризации и SEO анализа.

Интерфейс сервиса Serpstat
При сборе семантики учитывает частотность и конкурентность запросов по шкале от 1 до 100, показывает сложность продвижения. Может работать с региональной выдачей и сравнивать результаты с сайтами конкурентов. Особенно удобно, что Serpstat группирует ключевые слова по страницам и рекламным кампаниям с учетом однородности.
У сервиса есть бесплатная версия с ограниченным функционалом. Подписки оформляются на месяц или год. Самая недорогая стоит 55$ в месяц.
Rush Analytics
Сервис автоматизации парсинга и кластеризации семантического ядра. Собирает запросы и показывает их частотность на основе данных «Яндекс.Вордстат» и Google Ads, ищет подсказки в «Яндекс», Google и YouTube. Умеет кластеризовать ключевые слова методом Soft и Hard, автоматически создает структуру сайта.

Интерфейс Rush Analytics
Бесплатная версия с ограниченным функционалом доступна семь дней. Минимальный тариф стоит 500 рублей в месяц.
Готовое ядро выглядит как электронная таблица, где по каждой ключевой фразе указана базовая (по всем вариантам использования ключевого слова) и точная (без словоформ) частотность, а для каждого кластера — продвигаемая страница.
Данные в таком формате можно сразу использовать для SEO и контекстной рекламы:
- Разрабатывать или оптимизировать структуру сайта.
- Отбирать перспективные запросы с низкой стоимостью клика и запускать контекстную рекламу с дешевым целевым трафиком.
- Составлять контент-план на несколько лет или месяцев.
- Делать технические задания для контентного наполнения или оптимизации текущего контента.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
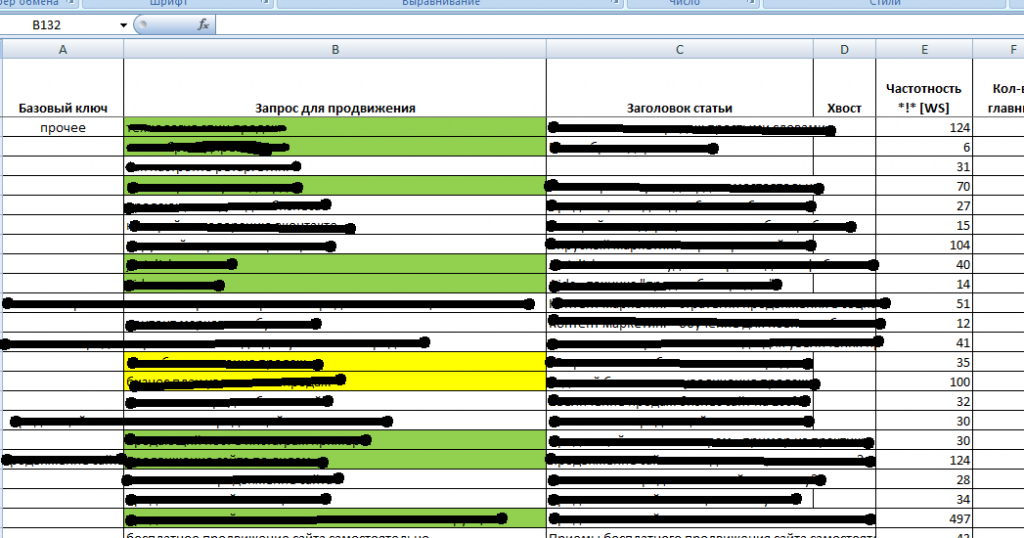
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.