Алгоритмы сортировки
Содержание:
- Встроенный язык 1С 8.*
- Пример:
- Программа упорядочения строк в алфавитном порядке[править]
- Программа упорядочения строк в алфавитном порядке
- Пузырьковая сортировка и сортировка JavaScript
- Пузырьковая сортировка
- Выбрать сортировку
- Сортировка пузырьком
- Пузырьковая сортировка и её улучшения
- Turbo Basic 1.1
- Простые сортировки
- C# с использованием лямбда-выражений
- Common Lisp
- Споры по поводу имени
- Пример работы алгоритма[править]
- Модификации[править]
- Анализ
- D
Встроенный язык 1С 8.*
Здесь приведен алгоритм сортировки на примере объекта типа «СписокЗначений», но его можно модифицировать для работы с любым объектом, для этого нужно изменить соответствующим образом код функций «СравнитьЗначения», «ПолучитьЗначение», «УстановитьЗначение».
Функция СравнитьЗначения(Знач1, Знач2)
Если Знач1>Знач2 Тогда
Возврат 1;
КонецЕсли;
Если Знач1<Знач2 Тогда
Возврат -1;
КонецЕсли;
Возврат 0;
КонецФункции
Функция ПолучитьЗначение(Список, Номер)
Возврат Список.Получить(Номер-1).Значение;
КонецФункции
Процедура УстановитьЗначение(Список, Номер, Значение)
Список.Значение = Значение;
КонецПроцедуры
Процедура qs_0(s_arr, first, last)
i = first;
j = last;
x = ПолучитьЗначение(s_arr, Окр((first + last) / 2, 0));
Пока i <= j Цикл
Пока СравнитьЗначения(ПолучитьЗначение(s_arr, i), x)=-1 Цикл
i=i+1;
КонецЦикла;
Пока СравнитьЗначения(ПолучитьЗначение(s_arr, j), x)=1 Цикл
j=j-1;
КонецЦикла;
Если i <= j Тогда
Если i < j Тогда
к=ПолучитьЗначение(s_arr, i);
УстановитьЗначение(s_arr, i, ПолучитьЗначение(s_arr, j));
УстановитьЗначение(s_arr, j, к);
КонецЕсли;
i=i+1;
j=j-1;
КонецЕсли;
КонецЦикла;
Если i < last Тогда
qs_0(s_arr, i, last);
КонецЕсли;
Если first < j Тогда
qs_0(s_arr, first,j);
КонецЕсли;
КонецПроцедуры
Процедура Сортировать(Список, Размер="", Первый="", Последний="")
Если Не ЗначениеЗаполнено(Первый) Тогда
Первый=1;
КонецЕсли;
Если НЕ ЗначениеЗаполнено(Последний) Тогда
Последний=Размер;
КонецЕсли;
qs_0(Список, Первый, Последний);
КонецПроцедуры
Пример:
Пусть исходный массив будет .
Первая итерация:
сравните элементы в индексах 1 и 2: 5, 4. Они не отсортированы. Поменяйте их местами. Array = .
Сравните элементы в индексе 2 и 3: 5, 9. Они отсортированы. Не меняйте местами. Array = .
Сравните элементы в индексе 3 и 4: 9, 3. Они не отсортированы. Поменяйте их местами. Array = .
Сравните элементы в индексе 4 и 5: 9, 7. Они не отсортированы. Поменяйте их местами. Array = .
Сравните элементы в индексе 5 и 6: 9, 6. Они не отсортированы. Поменяйте их местами. Array =
Массив после первой итерации равен .
В таблице ниже описан полный процесс сортировки, включая другие итерации. Для краткости показаны только шаги, на которых происходит замена.
Первая итерация:
Вторая итерация:
Третья итерация:
Исходный код: пузырьковая сортировка
def bubble_sort(arr, n): for i in range(0, n): for j in range(0, n-1): # Если пара не находится в отсортированном порядке if arr > arr: # Поменяйте местами пары, чтобы сделать их в отсортированном порядке arr, arr = arr, arr return arr if __name__ == "__main__": arr = n = len(arr) arr = bubble_sort(arr, n) print (arr)
Пояснение: Алгоритм состоит из двух циклов. Первый цикл повторяется по массиву n раз, а второй цикл n-1 раз. На каждой итерации первого цикла второй цикл сравнивает все пары соседних элементов. Если они не отсортированы, соседние элементы меняются местами, чтобы упорядочить их. Максимальное количество сравнений, необходимых для присвоения элементу его правой позиции в отсортированном порядке, равно n-1, потому что есть n-1 других элементов. Так как имеется n элементов, и каждый элемент требует максимум n-1 сравнений; массив сортируется за время O (n ^ 2). Следовательно, временная сложность наихудшего случая равна O (n ^ 2). Лучшая временная сложность в этой версии пузырьковой сортировки также составляет O (n ^ 2), потому что алгоритм не знает, что он полностью отсортирован. Следовательно, даже если он отсортирован.
Программа упорядочения строк в алфавитном порядке[править]
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define N 100
#define M 30
int main(int argc, char* argv[]) {
char aN];
int n, i;
scanf("%d", &n);
for (i=; i<n; i++)
scanf("%s", &ai]);
qsort(a, n, sizeof(charM]), (int (*)(const void *,const void *)) strcmp);
for (i=; i<n; i++)
printf("%s\n", ai]);
return ;
}
Обратите внимание на сложное приведение типов.
Функция strcmp, объявленная в файле string.h имеет следующий прототип:
int strcmp(const char*, const char*);
То есть функция получает два аргумента — указатели на кусочки памяти, где хранятся элементы типа char,
то есть два массива символов, которые не могут быть изменены внутри функции strcmp (запрет на изменение задается с помощью модификатора const).
В то же время в качестве четвертого элемента функция qsort хотела бы иметь функцию типа
int cmp(const void*, const void*);
В языке Си можно осуществлять приведение типов являющихся типами функции. В данном примере тип
int (*)(const char*, const char*); // функция, получающая два элемента типа 'const char *' и возвращающая элемент типа 'int'
приводится к типу
int (*)(const void*, const void*); // функция, получающая два элемента типа 'const void *' и возвращающая элемент типа 'int'
Программа упорядочения строк в алфавитном порядке
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define N 100
#define M 30
int main(int argc, char* argv[]) {
char a;
int n, i;
scanf("%d", &n);
for (i=0; i<n; i++)
scanf("%s", &a);
qsort(a, n, sizeof(char), (int (*)(const void *,const void *)) strcmp);
for (i=0; i<n; i++)
printf("%s\n", a);
return 0;
}
Обратите внимание на сложное приведение типов. Функция strcmp, объявленная в файле string.h имеет следующий прототип:
Функция strcmp, объявленная в файле string.h имеет следующий прототип:
int strcmp(const char*, const char*);
То есть функция получает два аргумента — указатели на кусочки памяти, где хранятся элементы типа char, то есть два массива символов, которые не могут быть изменены внутри функции strcmp (запрет на изменение задается с помощью модификатора const).
В то же время в качестве четвертого элемента функция qsort хотела бы иметь функцию типа
int cmp(const void*, const void*);
В языке Си можно осуществлять приведение типов являющихся типами функции. В данном примере тип
int (*)(const char*, const char*); // функция, получающая два элемента типа 'const char *' и возвращающая элемент типа 'int'
приводится к типу
int (*)(const void*, const void*); // функция, получающая два элемента типа 'const void *' и возвращающая элемент типа 'int'
Пузырьковая сортировка и сортировка JavaScript
y http-equiv=»Content-Type» content=»text/html;charset=UTF-8″>le=»margin-bottom:5px;»>Теги: JavaScript
Пузырьковая сортировка
Правило: сравните два числа до и после и поменяйте местами два числа, если условия обмена выполнены. Закон: в каждом раунде пузырьковой сортировки можно найти большее число и поместить его в правильное положение. Анализ: Количество раундов сравнения = длина массива -1; Количество сравнений в каждом раунде = длина массива — текущее количество раундов.
Я использовал функцию, чтобы инкапсулировать этот кусок для будущего использованияtool.js
index.html

Выбрать сортировку
Порядок отбора (метод вызова)правило: Выберите позицию и сравните число в этой позиции со всеми последующими числами. Если размер сравнивается, два числа поменяются местами. Количество раундов сравнения = длина массива-1; Количество сравнений в каждом раунде = длина массива — текущее количество раундов
Я использовал функцию, чтобы инкапсулировать этот кусок для будущего использованияtool.js
index.html
Интеллектуальная рекомендация
Пряжа генерирует фон и архитектуру Рамка планирования ресурсов пряжа Hadoop2.x В 1.x в Maprectuce существует определенный риск в Maprectuce, и Jobtracker слишком много, а использование ресурсов низкая…
Я готов написать свои заметки о многопоточности в трех частях, чтобы поделиться с вами: основы, боевые действия, тестирование и оптимизация. Эти три части связаны между собой. 1. Основы: Многопоточные…
HQL гибернации HQL: Hibernate Query Language — это объектно-ориентированный язык запросов, который несколько похож на язык запросов SQL. Среди различных методов поиска, предоставляемых Hibernate, HQL …
…
Раньше было доменное имя, которое использовалось бесплатно в Интернете.ssl сертификат, А затем вы хотите заменить бесплатный сертификат Let’s encrypt после истечения срока действия сертификата, а зате…
Вам также может понравиться
В настоящее время я пишу небольшую настольную программу для операций с базами данных. Я хочу напрямую вызвать в программе сценарий * .sql для последовательного создания нескольких баз данных, который …
При вставке изображения в документ Word формат изображения внедряется, почему изображение скрыто под текстом? Ничего особенного, давайте сразу перейдем к теме: мы столкнулись с проблемой при написании…
1. Резервное копирование /etc/apt/sources.list 2. Найти более быстрый источник данных онлайн Сервер обновлений Шанхайского университета Цзяотун в Шанхае идеально подходит для меня Примеч…
Я только что закончил среднюю школу, и когда я поступил в университет, я всегда думал, что смогу избавиться от кандалов и играть без ограничений. В то время это было действительно со многими студентам…
Некоторое время назад организационная структура была откорректирована, а затем распределение проекта было скорректировано. Когда помощник отдела нашел меня, он сказал, что было6.0Мой проект был таким:…
Сортировка пузырьком
Идея алгоритма очень простая. Идём по массиву чисел и проверяем порядок (следующее число должно быть больше и равно предыдущему), как только наткнулись на нарушение порядка, тут же обмениваем местами элементы, доходим до конца массива, после чего начинаем сначала.
Отсортируем массив {1, 5, 2, 7, 6, 3}
Идём по массиву, проверяем первое число и второе, они идут в порядке возрастания. Далее идёт нарушение порядка, меняем местами эти элементы
Продолжаем идти по массиву, 7 больше 5, а вот 6 меньше, так что обмениваем из местами
3 нарушает порядок, меняем местами с 7
Возвращаемся к началу массива и проделываем то же самое
void bubbleSort(int *a, size_t size) {
size_t i, j;
int tmp;
for (i = 1; i < size; i++) {
for (j = 1; j < size; j++) {
if (a > a) {
tmp = a;
a = a;
a = tmp;
}
}
}
}
Этот алгоритм всегда будет делать (n-1)2 шагов, независимо от входных данных. Даже если массив отсортирован, всё равно он будет пройден (n-1)2 раз. Более того, будут в очередной раз проверены уже отсортированные данные.
Пусть нужно отсортировать массив 1, 2, 4, 3
После того, как были поменяны местами элемента a и a нет больше необходимости проходить этот участок массива
Примем это во внимание и переделаем алгоритм
void bubbleSort2(int *a, size_t size) {
size_t i, j;
int tmp;
for (i = 1; i < size; i++) {
for (j = i; j > 0; j--) {
if (a < a) {
tmp = a;
a = a;
a = tmp;
}
}
}
}
Ещё одна реализация
void bubbleSort2b(int *a, size_t size) {
size_t i, j;
int tmp;
for (i = 1; i < size; i++) {
for (j = 1; j <= size-i; j++) {
if (a < a) {
tmp = a;
a = a;
a = tmp;
}
}
}
}
В данном случае будет уже вполовину меньше шагов, но всё равно остаётся проблема сортировки уже отсортированного массива: нужно сделать так, чтобы отсортированный массив функция просматривала один раз. Для этого введём переменную-флаг: он будет опущен (flag = 0), если массив отсортирован. Как только мы наткнёмся на нарушение порядка, то флаг будет поднят (flag = 1) и мы начнём сортировать массив как обычно.
void bubbleSort3(int *a, size_t size) {
size_t i;
int tmp;
char flag;
do {
flag = 0;
for (i = 1; i < size; i++) {
if (a < a) {
tmp = a;
a = a;
a = tmp;
flag = 1;
}
}
} while (flag);
}
В этом случае сложность также порядка n2, но в случае отсортированного массива будет всего один проход.
Теперь усовершенствуем алгоритм. Напишем функцию общего вида, чтобы она сортировала массив типа void. Так как тип переменной не известен, то нужно будет дополнительно передавать размер одного элемента массива и функцию сравнения.
int intSort(const void *a, const void *b) {
return *((int*)a) > *((int*)b);
}
void bubbleSort3g(void *a, size_t item, size_t size, int (*cmp)(const void*, const void*)) {
size_t i;
void *tmp = NULL;
char flag;
tmp = malloc(item);
do {
flag = 0;
for (i = 1; i < size; i++) {
if (cmp(((char*)a + i*item), ((char*)a + (i-1)*item))) {
memcpy(tmp, ((char*)a + i*item), item);
memcpy(((char*)a + i*item), ((char*)a + (i-1)*item), item);
memcpy(((char*)a + (i-1)*item), tmp, item);
flag = 1;
}
}
} while (flag);
free(tmp);
}
Функция выглядит некрасиво – часто вычисляется адрес текущего и предыдущего элемента. Выделим отдельные переменные для этого.
void bubbleSort3gi(void *a, size_t item, size_t size, int (*cmp)(const void*, const void*)) {
size_t i;
void *tmp = NULL;
void *prev, *cur;
char flag;
tmp = malloc(item);
do {
flag = 0;
i = 1;
prev = (char*)a;
cur = (char*)prev + item;
while (i < size) {
if (cmp(cur, prev)) {
memcpy(tmp, prev, item);
memcpy(prev, cur, item);
memcpy(cur, tmp, item);
flag = 1;
}
i++;
prev = (char*)prev + item;
cur = (char*)cur + item;
}
} while (flag);
free(tmp);
}
Теперь с помощью этих функций можно сортировать массивы любого типа, например
void main() {
int a = {1, 0, 9, 8, 7, 6, 2, 3, 4, 5};
int i;
bubbleSort3gi(a, sizeof(int), 10, intSort);
for (i = 0; i < 10; i++) {
printf("%d ", a);
}
_getch();
}
Пузырьковая сортировка и её улучшения
Сортировка пузырьком

Сортировка пузырьком — один из самых известных алгоритмов сортировки. Здесь нужно последовательно сравнивать значения соседних элементов и менять числа местами, если предыдущее оказывается больше последующего. Таким образом элементы с большими значениями оказываются в конце списка, а с меньшими остаются в начале.
Этот алгоритм считается учебным и почти не применяется на практике из-за низкой эффективности: он медленно работает на тестах, в которых маленькие элементы (их называют «черепахами») стоят в конце массива. Однако на нём основаны многие другие методы, например, шейкерная сортировка и сортировка расчёской.
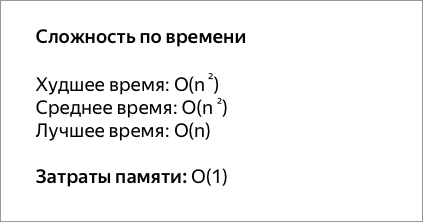
void BubbleSort(vector<int>& values) {
for (size_t idx_i = 0; idx_i + 1 < values.size(); ++idx_i) {
for (size_t idx_j = 0; idx_j + 1 < values.size() - idx_i; ++idx_j) {
if (values < values) {
swap(values, values);
}
}
}
}
Сортировка перемешиванием (шейкерная сортировка)
Шейкерная сортировка отличается от пузырьковой тем, что она двунаправленная: алгоритм перемещается не строго слева направо, а сначала слева направо, затем справа налево.
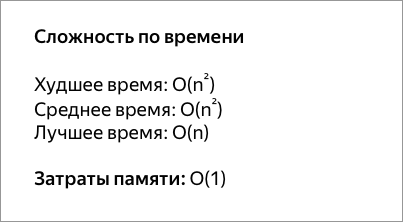
void ShakerSort(vector<int>& values) {
if (values.empty()) {
return;
}
int left = 0;
int right = values.size() - 1;
while (left <= right) {
for (int i = right; i > left; --i) {
if (values > values) {
swap(values, values);
}
}
++left;
for (int i = left; i < right; ++i) {
if (values > values) {
swap(values, values);
}
}
--right;
}
}
Сортировка расчёской
Сортировка расчёской — улучшение сортировки пузырьком. Её идея состоит в том, чтобы «устранить» элементы с небольшими значения в конце массива, которые замедляют работу алгоритма. Если при пузырьковой и шейкерной сортировках при переборе массива сравниваются соседние элементы, то при «расчёсывании» сначала берётся достаточно большое расстояние между сравниваемыми значениями, а потом оно сужается вплоть до минимального.
Первоначальный разрыв нужно выбирать не случайным образом, а с учётом специальной величины — фактора уменьшения, оптимальное значение которого равно 1,247. Сначала расстояние между элементами будет равняться размеру массива, поделённому на 1,247; на каждом последующем шаге расстояние будет снова делиться на фактор уменьшения — и так до окончания работы алгоритма.

void CombSort(vector<int>& values) {
const double factor = 1.247; // Фактор уменьшения
double step = values.size() - 1;
while (step >= 1) {
for (int i = 0; i + step < values.size(); ++i) {
if (values > values) {
swap(values, values);
}
}
step /= factor;
}
// сортировка пузырьком
for (size_t idx_i = 0; idx_i + 1 < values.size(); ++idx_i) {
for (size_t idx_j = 0; idx_j + 1 < values.size() - idx_i; ++idx_j) {
if (values < values) {
swap(values, values);
}
}
}
}
Turbo Basic 1.1
DEF FN QSORT(LOW,HIGH)
LOCAL I,J,X,TEMP
J=HIGH
X=Y[(LOW+HIGH)/2]
DO
WHILE Y<X:I=I+1:WEND
WHILE Y>X:J=J-1:WEND
IF I<=J THEN
TEMP=Y
Y=Y
Y=TEMP
I=I+1
J=J-1
END IF
LOOP WHILE I<=J
IF LOW<J THEN F=FN QSORT(LOW,J)
IF I<HIGH THEN F=FN QSORT(I,HIGH)
FN QSORT=TRUE
END DEF
Пример вызова функции FN QSORT(LOW,HIGH), входные и выходные данные в массиве DIM Y
LOW=N1 HIGH=N2 F=FN QSORT(LOW,HIGH)
Стоит отметить, что быстрая сортировка может оказаться малоэффективной на массивах, состоящих из небольшого числа элементов, поэтому при работе с ними разумнее отказаться от данного метода. В целом алгоритм неустойчив, а также использование рекурсии в неверно составленном коде может привести к переполнению стека. Но, несмотря на эти и некоторые другие минусы, быстрая сортировка все же является одним из самых эффективных и часто используемых методов.
При написании статьи были использованы открытые источники сети интернет :
Youtube
Простые сортировки
Сортировка вставками

При сортировке вставками массив постепенно перебирается слева направо. При этом каждый последующий элемент размещается так, чтобы он оказался между ближайшими элементами с минимальным и максимальным значением.

void InsertionSort(vector<int>& values) {
for (size_t i = 1; i < values.size(); ++i) {
int x = values;
size_t j = i;
while (j > 0 && values > x) {
values = values;
--j;
}
values = x;
}
}
Сортировка выбором
Сначала нужно рассмотреть подмножество массива и найти в нём максимум (или минимум). Затем выбранное значение меняют местами со значением первого неотсортированного элемента. Этот шаг нужно повторять до тех пор, пока в массиве не закончатся неотсортированные подмассивы.
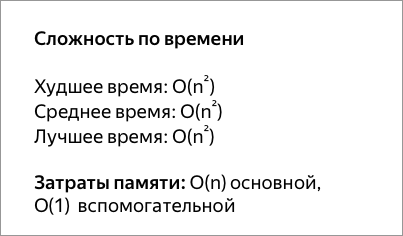
void SelectionSort(vector<int>& values) {
for (auto i = values.begin(); i != values.end(); ++i) {
auto j = std::min_element(i, values.end());
swap(*i, *j);
}
}
Эффективные сортировки
Быстрая сортировка
Этот алгоритм состоит из трёх шагов. Сначала из массива нужно выбрать один элемент — его обычно называют опорным. Затем другие элементы в массиве перераспределяют так, чтобы элементы меньше опорного оказались до него, а большие или равные — после. А дальше рекурсивно применяют первые два шага к подмассивам справа и слева от опорного значения.
Быструю сортировку изобрели в 1960 году для машинного перевода: тогда словари хранились на магнитных лентах, а сортировка слов обрабатываемого текста позволяла получить переводы за один прогон ленты, без перемотки назад.

int Partition(vector<int>& values, int l, int r) {
int x = values;
int less = l;
for (int i = l; i < r; ++i) {
if (values <= x) {
swap(values, values);
++less;
}
}
swap(values, values);
return less;
}
void QuickSortImpl(vector<int>& values, int l, int r) {
if (l < r) {
int q = Partition(values, l, r);
QuickSortImpl(values, l, q - 1);
QuickSortImpl(values, q + 1, r);
}
}
void QuickSort(vector<int>& values) {
if (!values.empty()) {
QuickSortImpl(values, 0, values.size() - 1);
}
}
Сортировка слиянием

Сортировка слиянием пригодится для таких структур данных, в которых доступ к элементам осуществляется последовательно (например, для потоков). Здесь массив разбивается на две примерно равные части и каждая из них сортируется по отдельности. Затем два отсортированных подмассива сливаются в один.

void MergeSortImpl(vector<int>& values, vector<int>& buffer, int l, int r) {
if (l < r) {
int m = (l + r) / 2;
MergeSortImpl(values, buffer, l, m);
MergeSortImpl(values, buffer, m + 1, r);
int k = l;
for (int i = l, j = m + 1; i <= m || j <= r; ) {
if (j > r || (i <= m && values < values)) {
buffer = values;
++i;
} else {
buffer = values;
++j;
}
++k;
}
for (int i = l; i <= r; ++i) {
values = buffer;
}
}
}
void MergeSort(vector<int>& values) {
if (!values.empty()) {
vector<int> buffer(values.size());
MergeSortImpl(values, buffer, 0, values.size() - 1);
}
}
Пирамидальная сортировка
При этой сортировке сначала строится пирамида из элементов исходного массива. Пирамида (или двоичная куча) — это способ представления элементов, при котором от каждого узла может отходить не больше двух ответвлений. А значение в родительском узле должно быть больше значений в его двух дочерних узлах.

Пирамидальная сортировка похожа на сортировку выбором, где мы сначала ищем максимальный элемент, а затем помещаем его в конец. Дальше нужно рекурсивно повторять ту же операцию для оставшихся элементов.

void HeapSort(vector<int>& values) {
std::make_heap(values.begin(), values.end());
for (auto i = values.end(); i != values.begin(); --i) {
std::pop_heap(values.begin(), i);
}
}
Ещё больше интересного — в соцсетях Академии
C# с использованием лямбда-выражений
using System;
using System.Collections.Generic;
using System.Linq;
static public class Qsort
{
public static IEnumerable<T> QuickSort<T>(this IEnumerable<T> list) where T : IComparable<T>
{
if (!list.Any())
{
return Enumerable.Empty<T>();
}
var pivot = list.First();
var smaller = list.Skip(1).Where(item => item.CompareTo(pivot) <= 0).QuickSort();
var larger = list.Skip(1).Where(item => item.CompareTo(pivot) > 0).QuickSort();
return smaller.Concat(new[] { pivot }).Concat(larger);
}
//(тоже самое, но записанное в одну строку, без объявления переменных)
public static IEnumerable<T> shortQuickSort<T>(this IEnumerable<T> list) where T : IComparable<T>
{
return !list.Any() ? Enumerable.Empty<T>() : list.Skip(1).Where(
item => item.CompareTo(list.First()) <= 0).shortQuickSort().Concat(new[] { list.First() })
.Concat(list.Skip(1).Where(item => item.CompareTo(list.First()) > 0).shortQuickSort());
}
}
Common Lisp
В отличие от других вариантов реализации на функциональных языках, представленных здесь, приводимая реализация алгоритма на Лиспе является «честной» — она не порождает новый отсортированный массив, а сортирует тот, который поступил ей на вход, «на том же месте». При первом вызове функции в параметры l и r необходимо передать нижний и верхний индексы массива (или той его части, которую требуется отсортировать). Код использует «императивные» макросы Common Lisp’а.
(defun quickSort (array l r)
(let ((i l)
(j r)
(p (svref array (round (+ l r) 2))))
(while (<= i j)
(while (< (svref array i) p) (incf i))
(while (> (svref array j) p) (decf j))
(when (<= i j)
(rotatef (svref array i) (svref array j))
(incf i)
(decf j)))
(if (>= (- j l) 1) (quickSort array l j))
(if (>= (- r i) 1) (quickSort array i r)))
array)
Споры по поводу имени
Сортировку пузырьков иногда называют «тонущей сортировкой».
Например, в книге Дональда Кнута « Искусство компьютерного программирования» , том 3: Сортировка и поиск, он заявляет в разделе 5.2.1 «Сортировка вставкой», что «устанавливается на свой надлежащий уровень» и что этот метод сортировки имеет иногда называют техникой просеивания или погружения .
Эта дискуссия увековечивается из-за легкости, с которой можно рассматривать этот алгоритм с двух разных, но одинаково обоснованных точек зрения:
- Эти большие значения могут рассматриваться как более тяжелый , и поэтому видно постепенно раковине в нижней части списка
- Эти меньшие значения можно рассматривать как легче и , следовательно , можно видеть , прогрессивно пузыриться к вершине списка.
Пример работы алгоритма[править]
Возьмём массив и отсортируем значения по возрастанию, используя сортировку пузырьком. Выделены те элементы, которые сравниваются на данном этапе.
Первый проход:
| До | После | Описание шага |
|---|---|---|
| 5 1 4 2 8 | 1 5 4 2 8 | Здесь алгоритм сравнивает два первых элемента и меняет их местами. |
| 1 5 4 2 8 | 1 4 5 2 8 | Меняет местами, так как 5 > 4 |
| 1 4 5 2 8 | 1 4 2 5 8 | Меняет местами, так как 5 > 2 |
| 1 4 2 5 8 | 1 4 2 5 8 | Теперь, ввиду того, что элементы стоят на своих местах (8 > 5), алгоритм не меняет их местами. |
Второй проход:
| До | После | Описание шага |
|---|---|---|
| 1 4 2 5 8 | 1 4 2 5 8 | |
| 1 4 2 5 8 | 1 2 4 5 8 | Меняет местами, так как 4 > 2 |
| 1 2 4 5 8 | 1 2 4 5 8 | |
| 1 2 4 5 8 | 1 2 4 5 8 |
Теперь массив полностью отсортирован, но неоптимизированный алгоритм проведет еще два прохода, на которых ничего не изменится, в отличие от алгоритма, использующего вторую оптимизацию, который сделает один проход и прекратит свою работу, так как не сделает за этот проход ни одного обмена.
Модификации[править]
Сортировка чет-нечетправить
Сортировка чет-нечет (англ. odd-even sort) — модификация пузырьковой сортировки, основанная на сравнении элементов стоящих на четных и нечетных позициях независимо друг от друга. Сложность — .
Псевдокод указан ниже:
function oddEvenSort(a):
for i = 0 to n - 1
if i mod 2 == 0
for j = 2 to n - 1 step 2
if a < a
swap(a, a)
else
for j = 1 to n - 1 step 2
if a < a
swap(a, a)
Преимущество этой сортировки — на нескольких процессорах она выполняется быстрее, так как четные и нечетные индексы сортируются параллельно.
Сортировка расческойправить
Сортировка расческой (англ. comb sort) — модификация пузырьковой сортировки, основанной на сравнении элементов на расстоянии. Сложность — , но стремится к . Является самой быстрой квадратичной сортировкой. Недостаток — она неустойчива. Псевдокод указан ниже:
function combSort(a):
k = 1.3
jump = n
bool swapped = true
while jump > 1 and swapped
if jump > 1
jump /= k
swapped = false
for i = 0 to size - jump - 1
if a < a
swap(a, a)
swapped = true
Пояснения: Изначально расстояние между сравниваемыми элементами равно , где — оптимальное число для этого алгоритма. Сортируем массив по этому расстоянию, потом уменьшаем его по этому же правилу. Когда расстояние между сравниваемыми элементами достигает единицы, массив досортировывается обычным пузырьком.
Сортировка перемешиваниемправить
Сортировка перемешиванием (англ. cocktail sort), также известная как Шейкерная сортировка — разновидность пузырьковой сортировки, сортирующая массив в двух направлениях на каждой итерации. В среднем, сортировка перемешиванием работает в два раза быстрее пузырька. Сложность — , но стремится она к , где — максимальное расстояние элемента в неотсортированном массиве от его позиции в отсортированном массиве. Псевдокод указан ниже:
function shakerSort(a):
begin = -1
end = n - 2
while swapped
swapped = false
begin++
for i = begin to end
if a > a
swap(a, a)
swapped = true
if !swapped
break
swapped = false
end--
for i = end downto begin
if a > a
swap(a, a)
swapped = true
Анализ
Пример пузырьковой сортировки. Начиная с начала списка, сравните каждую соседнюю пару, поменяйте их местами, если они не в правильном порядке (последняя меньше первой). После каждой итерации необходимо сравнивать на один элемент меньше (последний), пока не останется больше элементов для сравнения.
Представление
Пузырьковая сортировка имеет наихудший случай и среднюю сложность О ( n 2 ), где n — количество сортируемых элементов. Большинство практических алгоритмов сортировки имеют существенно лучшую сложность в худшем случае или в среднем, часто O ( n log n ). Даже другое О ( п 2 ) алгоритмы сортировки, такие как вставки рода , как правило , не работать быстрее , чем пузырьковой сортировки, а не более сложным. Следовательно, пузырьковая сортировка не является практическим алгоритмом сортировки.
Единственное существенное преимущество пузырьковой сортировки перед большинством других алгоритмов, даже быстрой сортировкой , но не сортировкой вставкой , заключается в том, что в алгоритм встроена способность определять, что список сортируется эффективно. Когда список уже отсортирован (в лучшем случае), сложность пузырьковой сортировки составляет всего O ( n ). Напротив, большинство других алгоритмов, даже с лучшей средней сложностью , выполняют весь процесс сортировки на множестве и, следовательно, являются более сложными. Однако сортировка вставкой не только разделяет это преимущество, но также лучше работает со списком, который существенно отсортирован (имеет небольшое количество инверсий ). Кроме того, если такое поведение желательно, его можно тривиально добавить к любому другому алгоритму, проверив список перед запуском алгоритма.
Кролики и черепахи
Расстояние и направление, в котором элементы должны перемещаться во время сортировки, определяют производительность пузырьковой сортировки, поскольку элементы перемещаются в разных направлениях с разной скоростью. Элемент, который должен двигаться к концу списка, может перемещаться быстро, потому что он может принимать участие в последовательных заменах. Например, самый большой элемент в списке будет выигрывать при каждом обмене, поэтому он перемещается в свою отсортированную позицию на первом проходе, даже если он начинается рядом с началом. С другой стороны, элемент, который должен двигаться к началу списка, не может двигаться быстрее, чем один шаг за проход, поэтому элементы перемещаются к началу очень медленно. Если наименьший элемент находится в конце списка, потребуется n −1 проход, чтобы переместить его в начало. Это привело к тому, что эти типы элементов были названы кроликами и черепахами соответственно в честь персонажей басни Эзопа о Черепахе и Зайце .
Были предприняты различные попытки уничтожить черепах, чтобы повысить скорость сортировки пузырей. Сортировка коктейлей — это двунаправленная сортировка пузырьков, которая идет от начала до конца, а затем меняет свое направление, идя от конца к началу. Он может довольно хорошо перемещать черепах, но сохраняет сложность наихудшего случая O (n 2 ) . Сортировка гребенкой сравнивает элементы, разделенные большими промежутками, и может очень быстро перемещать черепах, прежде чем переходить к все меньшим и меньшим промежуткам, чтобы сгладить список. Его средняя скорость сопоставима с более быстрыми алгоритмами вроде быстрой сортировки .
Пошаговый пример
Возьмите массив чисел «5 1 4 2 8» и отсортируйте его от наименьшего числа к наибольшему числу, используя пузырьковую сортировку. На каждом этапе сравниваются элементы, выделенные жирным шрифтом . Потребуется три прохода;
- Первый проход
- ( 5 1 4 2 8) → ( 1 5 4 2 8). Здесь алгоритм сравнивает первые два элемента и меняет местами, поскольку 5> 1.
- (1 5 4 2 8) → (1 4 5 2 8), поменять местами, поскольку 5> 4
- (1 4 5 2 8) → (1 4 2 5 8), поменять местами, поскольку 5> 2
- (1 4 2 5 8 ) → (1 4 2 5 8 ). Теперь, поскольку эти элементы уже упорядочены (8> 5), алгоритм не меняет их местами.
- Второй проход
- ( 1 4 2 5 8) → ( 1 4 2 5 8)
- (1 4 2 5 8) → (1 2 4 5 8), поменять местами, поскольку 4> 2
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Теперь массив уже отсортирован, но алгоритм не знает, завершился ли он. Алгоритму требуется один дополнительный полный проход без какой-либо подкачки, чтобы знать, что он отсортирован.
- Третий проход
- ( 1 2 4 5 8) → ( 1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
D
array qsort(array)(array _a)
{
alias typeof(array.init) _type;
array filter(bool delegate(_type) dg, array a){
array buffer = null;
foreach(value; a) {
if(dg(value)){
buffer ~= value;
}
}
return buffer;
}
if(_a.length <= 1) {
return _a;
}
else {
return qsort( filter((_type e){ return _a >= e; }, _a ) ) ~ _a ~
qsort( filter((_type e){ return _a < e; }, _a ) );
}
}
Более короткий вариант с использованием стандартной библиотеки Phobos:
import std.algorithm;
T _qsort3(T)(T a) {
if( a.length <= 1 )
return a;
else
return _qsort3( a.filter!( e => a >= e ).array ) ~ a ~
_qsort3( a.filter!( e => a < e ).array );
}