Windows 10 проблемы с кодировкой русского текста
Содержание:
- KOI8
- Решения проблемы с кодировкой в CMD. 1 Способ.
- Ошибки, связанные с кодировками
- Задания¶
- за что отвечает и как работает
- Проблемы консолей Visual Studio
- Кодировки¶
- Пометка порядка байтов
- Почему до сих пор используется 1251
- Библиотека преобразований Unicode-кодировок
- Сравнение найденных решений на автоопределение кодировки
- Что такое кодировка и почему она важна?
- Кодовая страница ANSI
- Кодировка символов в PowerShell Core
- Конфликт кодировок
- Как исправить иероглифы Windows 10 путем изменения кодовых страниц
- Кодировка символов в Windows PowerShell
- Решения проблемы с кодировкой в CMD. 1 Способ.
- История
- Электронная таблица средствами 1С (Версия 2.0)
KOI8
Стандартом для русской кириллицы в юникс-подобных операционных системах является кодировка (код обмена информацией, 8 битов), или KOI8. Существует несколько вариантов кодировки КОИ-8 для различных кириллических алфавитов. Русский алфавит описывается в кодировке KOI8-R, украинский — в KOI8-U, существуют также кодировки KOI8-RU (русско-белорусско-украинская), KOI8-T (таджикская) и т.д.
Разработчики КОИ-8 разместили символы русского алфавита таким образом, что если в тексте, написанном в КОИ-8, убирать восьмой бит каждого символа, то получается «читабельный» текст, хотя он и написан латинскими символами.
Вторая часть кодировки KOI8-R (русская), под символами указаны шестнадцатеричные коды Unicode:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | ─ 2500 | │ 2502 | ┌ 250C | ┐ 2510 | └ 2514 | ┘ 2518 | ├ 251C | ┤ 2524 | ┬ 252C | ┴ 2534 | ┼ 253C | ▀ 2580 | ▄ 2584 | █ 2588 | ▌ 258C | ▐ 2590 |
| 9 | ░ 2591 | ▒ 2592 | ▓ 2593 | ⌠23 20 | ■ 25A0 | ∙ 2219 | √ 221A | ≈ 2248 | ≤ 2264 | ≥ 2265 | 00A0 | ⌡ 2321 | ° 00B0 | ² 00B2 | · 00B7 | ÷ 00F7 |
| A | ═ 2550 | ║ 2551 | ╒ 2552 | ё 0451 | ╓ 2553 | ╔ 2554 | ╕ 2555 | ╖ 2556 | ╗ 2557 | ╘ 2558 | ╙ 2559 | ╚ 255A | ╛ 255B | ╜ 255C | ╝ 255D | ╞ 255E |
| B | ╟ 255F | ╠ 2560 | ╡ 2561 | Ё 0401 | ╢ 2562 | ╣ 2563 | ╤ 2564 | ╥ 2565 | ╦ 2566 | ╧ 2567 | ╨ 2568 | ╩ 2569 | ╪ 256A | ╫ 256B | ╬ 256C | 00A9 |
| C | ю 044E | а 0430 | б 0431 | ц 0446 | д 0434 | е 0435 | ф 0444 | г 0433 | х 0445 | и 0438 | й 0439 | к 043A | л 043B | м 043C | н 043D | о 043E |
| D | п 043F | я 044F | р 0440 | с 0441 | т 0442 | у 0443 | ж 0436 | в 0432 | ь 044C | ы 044B | з 0437 | ш 0448 | э 044D | щ 0449 | ч 0447 | ъ 044A |
| C | Ю 042E | А 0410 | Б 0411 | Ц 0426 | Д 0414 | Е 0415 | Ф 0424 | Г 0413 | Х 0425 | И 0418 | Й 0419 | К 041A | Л 041B | М 041C | Н 041D | О 041E |
| D | П 041F | Я 042F | Р 0420 | С 0421 | Т 0422 | У 0423 | Ж 0416 | В 0412 | Ь 042C | Ы 042B | З 0417 | Ш 0428 | Э 042D | Щ 0429 | Ч 0427 | Ъ 042A |
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++
» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++
После запуска «Notepad++
» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки
>Кодировки >Кириллица >OEM-866 »

и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.

Как видим, текст на Русском в CMD отобразился, как положено.
Ошибки, связанные с кодировками
При возникновении ошибки, связанной с кодировками, интерпретатор выдаст одно из следующих исключений:
-
. Это общее исключение для ошибок кодировки.
-
. Данное исключение возбуждается, если встречается кодовая позиция, которая отсутствует в кодировке.
-
. А это исключение возбуждается, когда символ, который необходимо закодировать, незнаком для кодировки.
Попытка выполнения вот такого кода (в файле всё ещё содержится испанский питон):
даст нам следующий результат:
Кодировка ASCII не поддерживает никакой алфавит, кроме английского. Поэтому декодирование символа «ó» вызывает у ASCII сложности. Однако Python всемогущ и есть механизм, который позволяет обработать ошибки кодировок. Это дополнительный параметр методов и — параметр . Он может принимать следующие значения:
Для обеих функций:
|
Обозначение |
Суть |
|
Значение по умолчанию. Несоотвествующие кодировке символы возбуждают исключения и наследуемые от него. |
|
|
Несоответсвующие символы пропускаются без возбуждения исключений. |
Только для метода :
|
Обозначение |
Суть |
|---|---|
|
Несоотвествующие символы заменяются на символ |
|
|
Несоответствующие символы заменяются на соответсвующие значения XML. |
|
|
Несоответствующие символы заменяются на определённые последовательности с обратным слэшем. |
|
|
Несоответствующие символы заменяются на имена этих символов, которые берутся из базы данных Unicode. |
Также отдельно выделены значения и .
Приведём пример использования таких обработчиков:
Важный поинт: если в текстах могут встретиться неожиданные для кодировки символы, во избежание возбуждения исключений можно использовать обработчики.
Задания¶
-
Доработайте прототип чата из прошлого урока таким образом, чтобы он корректно работал с русским языком (используйте методы кодирования и декодирования байтовых строк).
2. Напишите функцию для шифрования файла шифром Цезаря.
Расшифруйте:
key = 2 s = 'Oquv uvctu ctg qdugtxgf vq dg ogodgtu qh dkpctb uvct ubuvgou'
3. Напишите функцию для шифрования файла шифром пар.
Расшифруйте:
d_1 = 109, 122, 106, 115, 100, 99, 105, 120, 110, 98, 121, 118, 107 d_2 = 112, 103, 108, 104, 111, 102, 119, 117, 97, 101, 116, 113, 114 s = 'A hynk wh na nhykdadpwfnj delbfy fdahwhywaz dc n jxpwadxh hmsbkdwo dc mjnhpn sbjo ydzbysbk et wyh dia zknqwyt.'
за что отвечает и как работает
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)

Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.

Что делать, если слетела кодировка командной строки?
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.
- Перейдите по ветке HKEY_CURRENT_USER\Console и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).
- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.
Проблемы консолей Visual Studio
В Visual Studio имеется возможность подключения консолей, по умолчанию подключены командная строка для разработчика и Windows PowerShell для разработчика. К достоинствам можно отнести возможности определения собственных параметров консоли, отдельных от общесистемных, а также запуск консоли непосредственно в директории разработки. В остальном — это обычные стандартные консоли Windows, включая, как показано ранее, установленную кодовую страницу по умолчанию.
Отдельной опцией Visual Studio является встроенная односеансная консоль отладки, которая перехватывает команду Visual Studio на запуск приложения, запускается сама, ожидает компиляцию приложения, запускает его и отдает ему управление. Таким образом, отладочная консоль в течение всего рабочего сеанса находится под управлением приложения и возможность использования команд Windows или самой консоли, включая команду CHCP, не предусмотрена. Более того, отладочная консоль не воспринимает кодовую страницу по умолчанию, определенную в реестре, и всегда запускается в кодировке 437 или 866.
Анализ проблем консолей был бы не полон без ответа на вопрос — можно ли запустить консольное приложение без консоли? Можно — любой файл «.exe» запустится двойным кликом, и даже откроется окно приложения. Однако консольное приложение, по крайней мере однопоточное, по двойному клику запустится, но консольный режим не поддержит — все консольные вводы-выводы будут проигнорированы, и приложение завершится
Кодировки¶
Кодировка — это правила перевода одного набора символов в другой. В отношении компьютерных программ речь идёт о правилах кодирования последовательности из нулей и единиц в текст, число или что-либо другое.
Наиболее распространённые кодировки
|
Обозначение в python |
Название кодировки |
Описание |
|---|---|---|
|
ASCII |
Латинские буквы, цифры и простые символы |
|
|
windows-1251 |
Кириллическая кодировка (русский и другие языки) |
|
|
KOI-8 |
Кодировка для русского языка |
|
|
UTF-8 |
Юникод-кодировка, все языки (длина символа — 8 бит) |
|
|
UTF-16 |
Юникод-кодировка, все языки (длина символа — 16 бит) |
Unicode — стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. В настоящее время стандарт является преобладающим в Интернете.
Примеры кодов, имен и соответствующих символов:
Пометка порядка байтов
Символ-пометка (BOM) — это сигнатура в Юникоде в первых нескольких байтах файла или текстового потока, указывающих, какая кодировка Юникода используется для данных. Дополнительные сведения см. в документации по метке порядка байтов .
в Windows PowerShell любая кодировка юникода, за исключением , всегда создает спецификацию. По умолчанию PowerShell Core имеет значение для всех текстовых выходных данных.
Для обеспечения оптимальной совместимости Избегайте использования спецификаций в файлах UTF-8. платформы unix и служебные программы unix-heritage, также используемые на платформах Windows, не поддерживают спецификации.
Аналогичным образом следует избегать кодирования. UTF-7 не является стандартной кодировкой Юникода и записывается без спецификации во всех версиях PowerShell.
создание сценариев PowerShell на платформе, похожем на Unix, или использовании кросс-платформенного редактора на Windows, например Visual Studio Code, приводит к созданию файла, закодированного с помощью . эти файлы прекрасно работают в PowerShell Core, но могут нарушить работу Windows PowerShell если файл содержит символы, отличные от Ascii.
Если в скриптах необходимо использовать символы, отличные от ASCII, сохраните их как UTF-8 с помощью BOM. без спецификации Windows PowerShell правильно интерпретирует скрипт как закодированный в устаревшей кодовой странице ANSI. И наоборот, файлы, имеющие СПЕЦИФИКАЦИю UTF-8, могут быть проблематичными для платформ, подобных Unix. Многие средства UNIX, такие как ,, и некоторые редакторы, например, не узнают, как обрабатывать спецификацию.
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251. И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
,
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием
Библиотека преобразований Unicode-кодировок
В сопутствующий этой статье пакет исходного кода включен пример компилируемого C++-кода. Это повторно используемый код, без ошибок компилируемый в Visual C++ при уровне предупреждений 4 (/W4) в 32- и 64-разрядных сборках. Он реализован как библиотека C++ в виде только заголовочных файлов. По сути, этот модуль преобразования Unicode-кодировок состоит из двух заголовочных файлов: utf8except.h и utf8conv.h. Первый содержит определение C++-класса исключения, используемого для уведомления об ошибке при преобразованиях Unicode-кодировок. Второй реализует собственно функции преобразования Unicode-кодировок.
Заметьте, что utf8except.h содержит только кросс-платформенный C++-код; это делает возможным захват исключения при преобразовании кодировки UTF-8 в любых местах ваших проектов на C++, включая те части кода, которые не специфичны для Windows. Напротив, utf8conv.h содержит C++-код, специфичный для Windows, поскольку он напрямую взаимодействует с границей Win32 API.
Для повторного использования этого кода в ваших проектах просто включайте директивой #include эти заголовочные файлы. Сопутствующий пакет исходного кода содержит дополнительный файл, реализующий некоторые наборы тестов.
Сравнение найденных решений на автоопределение кодировки
Мне кажется, получилось забавно.
| # | Кодировка | html/charset | saintfish/chardet | softlandia/cpd | enca |
|---|---|---|---|---|---|
| 1 | CP1251 | windows-1252 | CP1251 | CP1251 | CP1251 |
| 2 | CP866 | windows-1252 | windows-1252 | CP866 | CP866 |
| 3 | KOI8-R | windows-1252 | KOI8-R | KOI8-R | KOI8-R |
| 4 | ISO-8859-5 | windows-1252 | ISO-8859-5 | ISO-8859-5 | ISO-8859-5 |
| 5 | UTF-8 with BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 6 | UTF-8 without BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 7 | UTF-16LE with BOM | utf-16le | utf-16le | utf-16le | ISO-10646-UCS-2 |
| 8 | UTF-16LE without BOM | windows-1252 | ISO-8859-1 | utf-16le | unknown |
| 9 | UTF-16BE with BOM | utf-16le | utf-16be | utf-16be | ISO-10646-UCS-2 |
| 10 | UTF-16BE without BOM | windows-1252 | ISO-8859-1 | utf-16be | ISO-10646-UCS-2 |
| 11 | UTF-32LE with BOM | utf-16le | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 12 | UTF-32LE without BOM | windows-1252 | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 13 | UTF-32BE with BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 14 | UTF-32BE without BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 15 | KOI8-R (UPPER) | windows-1252 | KOI8-R | KOI8-R | CP1251 |
| 16 | CP1251 (UPPER) | windows-1252 | CP1251 | CP1251 | KOI8-R |
| 17 | CP866 & CP1251 | windows-1252 | CP1251 | CP1251 | unknown |
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица KOI8-r

В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true
Что такое кодировка и почему она важна?
VS Code управляет интерфейсом ввода строки символов в буфер пользователем и чтения-записи блоков байтов в файловой системе. При сохранении файла в VS Code используется кодирование текста для определения того, какие байты получит каждый символ. Подробные сведения см. в статье О шифровании символов.
Аналогичным образом, когда оболочка PowerShell запускает скрипт, ей необходимо преобразовать байты из файла в символы для преобразования файла в программу PowerShell. Так как VS Code записывает файл, а PowerShell считывает файл, этим средствам необходимо использовать одну и ту же систему кодировки. Этот процесс синтаксического анализа скрипта PowerShell идет так: байты -> символы -> лексемы -> дерево абстрактного синтаксиса -> выполнение.
И VS Code, и PowerShell устанавливаются с подходящей конфигурацией кодировки по умолчанию. Тем не менее кодировка по умолчанию, используемая PowerShell, была изменена с выпуском PowerShell Core (версии 6.x). Чтобы избежать проблем с PowerShell и расширениями PowerShell в VS Code, необходимо настроить параметры VS Code и PowerShell должным образом.
Кодовая страница ANSI
| Псевдоним (а) | ANSI (неверное название) |
|---|---|
| Стандарт | Стандарт кодирования WHATWG |
| Расширяется | US-ASCII |
| Предшествует | ISO 8859 |
| Преемник | Юникод UTF-16 (в Win32 API) |
Кодовые страницы ANSI (официально называемые «кодовыми страницами Windows» после того, как Microsoft приняла неправильное употребление первого термина) используются для приложений, не поддерживающих Unicode (скажем, ориентированных на байты ), использующих графический пользовательский интерфейс в системах Windows. Термин «ANSI» является неправильным, потому что эти кодовые страницы Windows не соответствуют ни одному стандарту ANSI; Кодовая страница 1252 была основана на раннем проекте ANSI, который стал международным стандартом ISO 8859-1 , который добавляет еще 32 управляющих кода и пространство для 96 печатаемых символов. Среди других отличий кодовые страницы Windows выделяют печатаемые символы в дополнительное пространство управляющего кода, что делает их в лучшем случае неразборчивыми для совместимых со стандартами операционных систем.)
Большинство устаревших кодовых страниц «ANSI» имеют номера кодовых страниц в шаблоне 125x. Тем не менее, (тайский) и восточноазиатские многобайтовые кодовые страницы ANSI ( , , , ), все из которых также используются в качестве кодовых страниц OEM, пронумерованы для соответствия аналогичным (но не идентичным) кодовым страницам IBM. кодировки. Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера вариантам Microsoft, они приведены для справки в приведенных ниже списках, где это применимо.
Все кодовые страницы Windows 125x, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как « номер Windows», хотя «Windows-936» рассматривается как синоним « GBK ». Кодовая страница Windows 932 вместо этого помечена как «Windows-31J».
Кодовые страницы ANSI Windows, и особенно кодовая страница , были так названы, поскольку они якобы были основаны на черновиках, представленных или предназначенных для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо:
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 и ISO-8859-1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 и ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows-1257 против ISO-8859-4 ; ISO-8859-13 был введен намного позже). Кроме того, Windows-1251 не следует ни ISO-стандартизированному ISO-8859-5, ни преобладающему в то время KOI-8 .
Microsoft присвоила около двенадцати типографских и деловых символов (включая, в частности, знак евро , €) в CP1252 кодовые точки 0x80–0x9F, которые в ISO 8859 присвоены управляющим кодам C1 . Эти назначения также присутствуют во многих других кодовых страницах ANSI / Windows в тех же кодовых точках. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Однако при включении в файл, передаваемый на совместимую со стандартами платформу, такую как Unix или MacOS, информация была невидимой и потенциально опасной.
Кодировка символов в PowerShell Core
В PowerShell Core (V6 и более поздних версий) параметр Encoding поддерживает следующие значения:
- : Использует кодировку для набора символов ASCII (7-разрядных).
- : Кодируется в формате UTF-16 с обратным порядком байтов.
- : Использует кодировку по умолчанию для программ MS-DOS и консолей.
- : Кодируется в формате UTF-16 с прямым порядком байтов.
- : Кодируется в формате UTF-7.
- : Кодирует в формате UTF-8 (без спецификации).
- : Кодирует в формате UTF-8 с меткой порядка байтов (BOM)
- : Кодирует в формате UTF-8 без метки порядка байтов (BOM)
- : Кодируется в формате UTF-32.
По умолчанию PowerShell Core имеет значение для всех выходных данных.
Начиная с PowerShell 6,2, параметр кодировки также разрешает числовые идентификаторы зарегистрированных кодовых страниц (например ,) или строковых имен зарегистрированных кодовых страниц (например ,). Дополнительные сведения см. в документации .NET по кодированию. codepage.
Конфликт кодировок
Полностью локализованная консоль в идеале должна поддерживать все мыслимые и немыслимые кодировки приложений, включая свои собственные команды и команды Windows, меняя «на лету» кодовые страницы потоков ввода и вывода. Задача нетривиальная, а иногда и невозможная — кодовые страницы DOS (CP437, CP866) плохо совмещаются с кодовыми страницами Windows и Unicode.
История кодировок здесь: О кодировках и кодовых страницах / Хабр (habr.com)
Исторически кодовой страницей Windows является CP1251 (Windows-1251, ANSI, Windows-Cyr), уверенно вытесняемая 8-битной кодировкой Юникода CP65001 (UTF-8, Unicode Transformation Format), в которой выполняется большинство современных приложений, особенно кроссплатформенных. Между тем, в целях совместимости с устаревшими файловыми системами, именно в консоли Windows сохраняет базовые кодировки DOS — CP437 (DOSLatinUS, OEM) и русифицированную CP866 (AltDOS, OEM).
Поскольку в консоли постоянно происходит передача управления от приложений к собственно командному процессору и обратно, регулярно возникает «конфликт кодировок», наглядно иллюстрируемый таблица 1 и 2, сформированных следующим образом:
Были запущены три консоли — CMD, PS и WPS. В каждой консоли менялась кодовая страница с помощью команды CHCP, выполнялась команда Echo c двуязычной строкой в качестве параметра (табл. 1), а затем в консоли запускалось тестовое приложение, исходные файлы которого были созданы в кодировке UTF-8 (CP65001): первая строка формируется и направляется в поток главным модулем, вторая вызывается им же, формируется в подключаемой библиотеке классов и направляется в поток опять главным модулем, третья строка полностью формируется и направляется в поток подключаемой библиотекой.
Командную часть задания все консоли локализовали практически без сбоев во всех кодировках, за исключением: в WPS неверно отображена русскоязычная часть команды во всех кодировках.
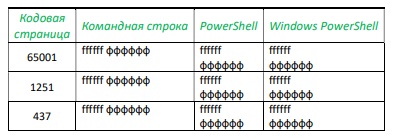 Табл. 1. Результат выполнения команды консоли Echo ffffff фффффф
Табл. 1. Результат выполнения команды консоли Echo ffffff фффффф
Вывод тестового приложения локализован лишь в 50% испытаний, как показано в табл.2.
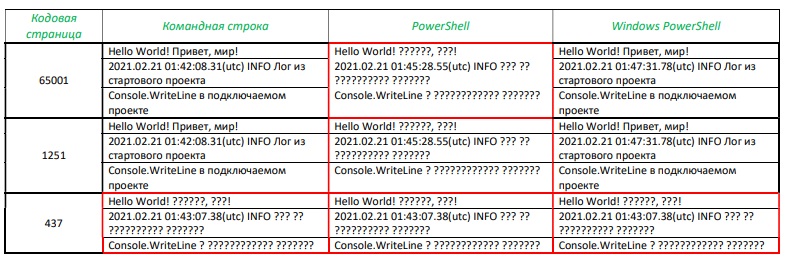 Табл. 2. Результат запуска приложения LoggingConsole.Test
Табл. 2. Результат запуска приложения LoggingConsole.Test
По умолчанию Windows устанавливает для консоли кодовые страницы DOS. Чаще всего CP437, иногда CP866. Актуальные версии командной строки cmd.exe способны локализовать приложения на основе русифицированной кодовой страницы 866, но не 437, отсюда и изначальный конфликт кодировок консоли и приложения. Поэтому
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.

Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Источник
Кодировка символов в Windows PowerShell
В PowerShell 5,1 параметр Encoding поддерживает следующие значения:
- Использует кодировку ASCII (7-разрядных).
- Использует UTF-16 с обратным порядком байтов.
- Использует UTF-32 с обратным порядком байтов.
- Кодирует набор символов в последовательность байтов.
- Использует кодировку, соответствующую активной кодовой странице системы (обычно ANSI).
- Использует кодировку, соответствующую текущей кодовой странице OEM системы.
- аналогичен .
- Использует UTF-16 с прямым порядком байтов.
- аналогичен .
- Использует UTF-32 с прямым порядком байтов.
- Использует UTF-7.
- Использует UTF-8 (с BOM).
в общем случае Windows PowerShell по умолчанию использует кодировку юникод UTF-16le . однако кодировка по умолчанию, используемая командлетами в Windows PowerShell, не согласуется.
Примечание
При использовании любой кодировки Юникода, за исключением , всегда создает спецификацию.
Для командлетов, записывающих выходные данные в файлы:
-
и операторы перенаправления и создают UTF-16LE, который, в свою очередь, отличается от и .
-
а также создавать файлы UTF-16LE.
-
Если целевой файл пуст или не существует, и Используйте кодировку. — это кодировка, определяемая кодовой страницей устаревшей версии ANSI на языке активного системы.
-
создает файлы, но использует другую кодировку при использовании параметра append (см. ниже).
-
по умолчанию создает файлы UTF-8 с BOM.
-
создает файл UTF-8 с кодировкой BOM.
-
по умолчанию использует кодировку.
-
создает файлы с помощью спецификации. При использовании параметра append кодировка может отличаться (см. ниже).
Для команд, которые добавляют к существующему файлу:
-
и оператор перенаправления не пытается сопоставить кодировку содержимого существующего целевого файла. Вместо этого они используют кодировку по умолчанию, если не используется параметр Encoding . При добавлении содержимого необходимо использовать исходную кодировку файлов.
-
При отсутствии явного параметра кодировки обнаруживает существующую кодировку и автоматически применяет ее к новому содержимому. Если имеющееся содержимое не имеет BOM, используется кодировка ANSI. Поведение аналогично в PowerShell Core (V6 и более поздних версиях), кроме кодировки по умолчанию — .
-
соответствует существующей кодировке, если целевой файл содержит СПЕЦИФИКАЦИю. В отсутствие спецификации используется Кодировка.
-
соответствует существующей кодировке файлов, включающих СПЕЦИФИКАЦИю. При отсутствии спецификации по умолчанию используется Кодировка. Такая кодировка может привести к утере данных или повреждению символов, если данные в записи содержат многобайтовые символы.
Для командлетов, считывающих строковые данные в отсутствие спецификации:
-
и использует кодировку ANSI. ANSI также используется механизмом PowerShell при чтении исходного кода из файлов.
-
, и предполагают отсутствие спецификации.
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++
» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++
После запуска «Notepad++
» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки
>Кодировки >Кириллица >OEM-866 »

и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.

Как видим, текст на Русском в CMD отобразился, как положено.
История
Первоначально компьютерные системы и языки системного программирования не делали различия между символами и байтами : для используемых в большей части Африки, Америки, Южной и Юго-Восточной Азии, Ближнего Востока и Европы, для символа требуется всего один байт. , но два или более байта необходимы для идеографических наборов, используемых в остальном мире. Впоследствии это привело к большой путанице. Программное обеспечение и системы Microsoft, предшествующие линейке Windows NT, являются примерами этого, поскольку они используют кодовые страницы OEM и ANSI, которые не делают различий.
С конца 1990-х годов программное обеспечение и системы приняли Unicode в качестве предпочтительного формата хранения; эта тенденция была улучшена благодаря широкому распространению XML , который обеспечивает более адекватный механизм для маркировки используемой кодировки. Последние продукты Microsoft и интерфейсы прикладных программ используют Unicode внутри, но многие приложения и API продолжают использовать кодировку по умолчанию «локали» компьютера при чтении и записи текстовых данных в файлы или стандартный вывод. Таким образом, файлы могут быть разборчивыми и разборчивыми в одной части мира, а моджибаке — в другой — неразборчивыми .
UTF-8, UTF-16
Microsoft решила принять 16-битную (двухбайтовую) систему UTF-16 для всех своих операционных систем, начиная с Windows NT. Этот метод однозначно кодирует все символы Unicode в базовой многоязычной плоскости и 32-битный (четырехбайтовый) код для других, но остальная часть отрасли ( Unix-подобные системы и Интернет) выбрали UTF-8 (который использует один байт для 7-битный набор символов ASCII , два или три байта для других символов в BMP и четыре байта для остатка). Начиная с , компьютеры с Windows можно настроить так, чтобы разрешить UTF-8 в качестве кодовой страницы «ANSI» и OEM.
Электронная таблица средствами 1С (Версия 2.0)
Функционал электронной таблицы для программ на платформе 1С реализован на основе табличных документов. Функционал реализован в виде обработки. Большую часть формы обработки занимают листы (закладки) с табличными документами, которые выполняет роль электронной таблицы. Листы могут быть добавлены, удалены или переименованы. Ограничение по количеству листов определяется возможностью платформы. В формулах электронной таблицы можно использовать любые языковые конструкции, процедуры и функции 1С, ссылки на другие ячейки электронной таблицы расположенные в том числе и на других листах. Допустимо обращаться к ячейкам электронной таблицы по имени именованной области. В случае использования в формулах электронной таблицы данных из самой таблицы пересчет зависимых ячеек с формулами производится автоматически. Электронную таблицу можно сохранить в файл.
1 стартмани