Как посмотреть историю сайта в прошлом? инструкция и сервисы
Содержание:
- Library Leaders Forum
- Что делать, если удалённая страница не сохранена ни в одном из архивов?
- Где взять уникальный контент для сателлитов?
- Всемирный веб архив сайтов интернета
- Как сделать качественный сателлит?
- Качаем сайт с web.archive.org
- 1990 год
- Как посмотреть архивные копии страницы в web archive
- Conference Workshops
- Первые шаги в сайтостроении
- [править] Примеры
- История создания и разработки веб-сайтов
- Создание первого в мире сайта
- Что такое веб-архив?
- Основная терминология
- Как добавить копию страницы в web archive
- Зачем проверять историю?
Library Leaders Forum
Session I: Community DialogueOctober 13 @ 10am PT / 1pm ET – RegisterIn our first session, hear from library leaders as they navigate the challenges of the ebook marketplace, and their concerns about the future of library collections as content moves digital. We’ll also be joined by copyright experts and publishers for a panel discussion on digital ownership.
Session II: Community ImpactOctober 20 @ 10am PT / 1pm ET – RegisterIn our second session, we’ll explore the impacts that digital collections have had for libraries during the pandemic. Hear firsthand from educators & librarians about the value of digitized library collections for the patrons, students, and communities they serve. We’ll also feature new developments at the Internet Archive, and how these advances help connect digital learners with books, articles, and other resources. We’ll finish the session by awarding the Internet Archive Hero Award 2021.
Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:
cache:https://hackware.ru/?p=6045
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=1&vwsrc=0
Исходный код:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=0&vwsrc=1
Где взять уникальный контент для сателлитов?
Оригинальный контент, пожалуй, один из важнейших параметров для хорошего сателлита. Несколько способом его получить:
Копирайтинг:
Самый простой и самый дорогостоящий метод. Необходимо создать техническое задание и отдать его SEO-копирайтеру, который напишет для вас уникальный, оптимизированный текст. Остается только разместить его.
Рерайт :
Более практичный способ получить уникальный материал для сайта. Рерайт – это переписывание уже созданного кем-то текста. В интернете размещено огромное количество контента. Качественный рерайт также, как и копирайтинг, даст вам уникальный, читабельный материал. Такой контент будет хорошо восприниматься и посетителями, и роботами поисковых систем.
Генерация текстов по шаблонам:
Можно назвать этот способ автоматическим рерайтом текста. Позволяет получить из одного материала множество новых. В этом вам помогут сервисы онлайн-генерации текстов. Например, Seogenerator. Принцип работы строится на использовании конструкций, которые заменяют фрагменты текущего текста на заданные варианты. Вот простой пример.
Задаем шаблон:
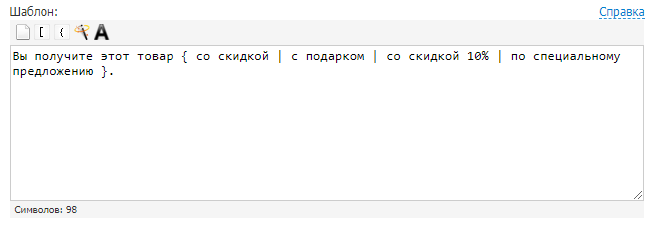
Получаем тексты:
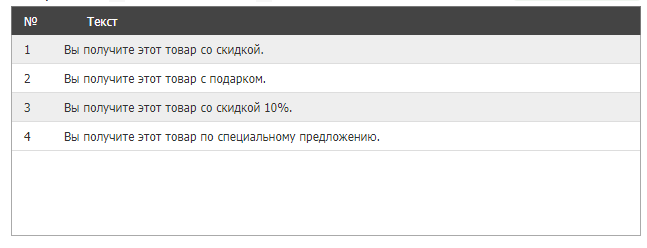
Важно следить за качеством, осмысленностью и уникальностью полученных материалов, объемные тексты проверять на возможный переспам. Вы формируете YML-выгрузку товаров
Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита
Вы формируете YML-выгрузку товаров. Почти все популярные CMS сегодня умеют экспортировать данные в YML-файлы. В полученную выгрузку вносите небольшие корректировки в ценах, размерах скидки, названиях товаров и используете ее для наполнения сателлита.
Восстановление контента из веб-архива:
Ищем «дропы» – домены, у которых закончился срок регистрации – схожей тематики. Найти такие домены можно, например, с помощью Reg.ru. Проверяем историю, обратные ссылки, анкоры, не менялась ли тематика и т.д. Восстанавливаем нужный контент из веб-архива и получаем уникальный сайт. Для скачивания файлов из архива есть готовые сервисы, например, Archivarix. Все сайты имеют свои особенности, поэтому при восстановлении могут быть ошибки. Наш совет – заниматься восстановлением старых сайтов вместе с разработчиком.
Всемирный веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.
Как сделать качественный сателлит?
Если вы все же решили попробовать этот метод поискового продвижения, вот несколько правил, которые помогут создать хороший сайт-сателлит и избежать санкций со стороны Яндекса и Google.
Желательно разместить сателлит на хостинге, отличном от продвигаемого сайта, и использовать другую CMS
Владелец домена нового сайта должен отличаться от продвигаемого
Использовать новые контактные данные
В панелях вебмастеров использовать другие аккаунты
Шаблон и структура на сателлитах должны отличаться от шаблона и структуры продвигаемого сайта
Обязательно использовать оригинальный и качественный контент (ниже несколько способов получить его)
Важно, чтобы тематика вспомогательного сайта была релевантна тематике ключевого проекта
Желательно, чтобы ссылочная масса не повторялась с ссылочной массой основного ресурса
Устранить основные технические ошибки на новом сайте, если они есть
Оптимизировать и развивать сайты
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:

Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:

Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:

Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.

Долистал я до 23 октября 2017-го и вижу уже другое содержимое:

Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:

А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
1990 год
Начать историю развития сайтов необходимо с истоков. Первый сайт был создан в мае 1990 г Тимоти Джоном Бернесом-Ли, сотрудником Европейского Центра по ядерным исследованиям (CERN). Он располагался по адресу info.cern.ch.
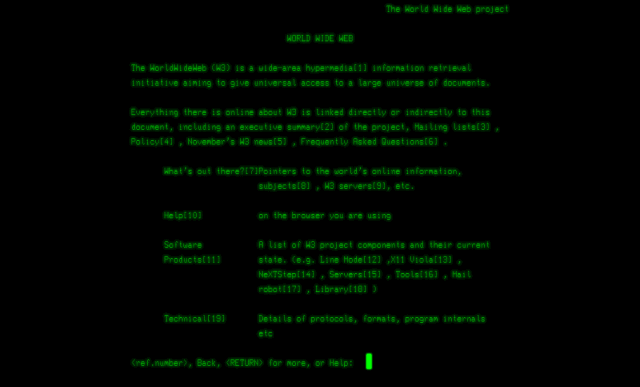
Первый браузер, созданный также Тимоти Дж. Бернесом-Ли, мог обрабатывать только текстовую информацию, соответственно его сайт был исключительно текстовый. Для перехода по ссылкам на другие страницы необходимо было вводить номер, указанный в квадратных скобках, в строку, расположенную внизу страницы.
Первые сайты представляли из себя текстовые документы со ссылками на другие страницы. Еще не существовало CSS (каскадных таблиц стилей) и поддерживать сайты тех времен было той еще задачей. Если вам нужно было сделать заголовки на вашем сайте синего цвета, то необходимо было прописывать цвет в теге:
<H1><FONT COLOR=blue>Ваш заголовок</FONT></H1>
И так для каждого заголовка.
Для упорядочивания информации на сайтах использовали таблицы.
Как посмотреть архивные копии страницы в web archive
Откройте сайт Web Archive или приложение сервиса. Если используете последнее, сразу после запуска создайте аккаунт.
Вставьте ссылку на нужную страницу и нажмите Enter (на сайте) или Overview of All Archives (в приложении).
Пролистайте календарь, чтобы найти подходящие копии. Дни, в которые бот создавал дубликаты страницы, отмечены кружками.
Нажмите на подходящую дату, чтобы просмотреть архивную копию.
Сайт также позволяет сравнивать две копии. Для этого на странице с календарём нажмите Changes, отметьте две даты и кликните Compare.
В результате Web Archive отобразит копии рядом и выделит несовпадения.
Conference Workshops
Controlled Digital Lending: Unlocking the Library’s Full PotentialOctober 7 @ 10am PT / 1pm ET – RegisterLast month, Library Futures Foundation released a new policy document, “Controlled Digital Lending: Unlocking the Library’s Full Potential.” Library Futures Foundation developed this document in consultation with the Intellectual Property and Information Policy (iPIP) Clinic at Georgetown Law. The document covers all the benefits, innovations, and goals that are the basis of any controlled digital lending system and makes the crucial connection between CDL and issues of equity. It expands beyond the legal rationale laid out in the Controlled Digital Lending (CDL) White Paper by clarifying the core principles that are the foundations of a library’s mission to provide access to materials to serve the public good.
This session will provide an opportunity to hear from the authors of the policy document, to engage in a virtual discussion, and to give your feedback on how this document may be useful to your community.
Empowering Libraries Through Controlled Digital LendingOctober 12 @ 10am PT / 1pm ET – RegisterThe Internet Archive’s Open Libraries program empowers libraries to lend digital books to patrons using Controlled Digital Lending. Attendees will learn how CDL works, the benefits of the Open Libraries program, and the impact that the program is having for partner libraries and the communities they serve.
Первые шаги в сайтостроении

Прежде чем появилась возможность создавать сайты, возник интернет и произошло это событие в 1990 году. Интернет без информации, представлял из себя совершенно бесполезное изобретение и его необходимо было наполнить. Именно этим вопросом и решил заняться британский ученый Тимоти Бернерс-Ли, который создавал свои разработки в Европейской лаборатории элементарных частиц. Прежде чем создать сайт, он успел подготовить и другие, не менее важные инструменты, которые лежат в основе многих программ на сегодняшний день. Именно он создал Интернет, успешно разработал URL, а также протокол HTTP и прописал язык программирования, который на сегодня нам известен как HTML.
Разрабатывая интернет, ученый полагал что создает его именно для того, чтобы упростить процесс хранения и сбора информации, чтобы на любой вопрос ответ можно было найти быстро и легко. Учитывая тенденцию повседневного использования интернета на сегодняшний день, то можно смело утверждать, что задумки ученого, полностью оправдали себя на практике.
Создавая сайт, Ти Бернерс-Ли задумывал его как некую «папку», в которой будут храниться самые основные сетевые документы, а объединять их будет личное доменное имя, оригинальное и единственное в своем роде. По-сути, именно такими сайты являются и на сегодняшний день, как старые, так и новые проекты, просто хранят в себе сгусток информации, различных страниц и документов, которые фактически принадлежат юридическому лицу, при этом находятся в свободном доступе для массы пользователей, а отыскать их можно под определенным доменным именем.
[править] Примеры
Роскомнаха банит архивы интернета (Блюстители)
- web.archive.org — старейший веб-архив, сохраняющий копии сайтов с 1996 года в автоматическом режиме в определённые промежутки времени. Имеет юридический статус библиотеки, является некоммерческой организацией. Сайт обладает несколькими зеркалами. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ за страницу «Одиночный Джихад» (а ещё ранее — за страницу с видеороликом «Звон мечей» террористической группировки ИГИЛ, запрещённой в РФ). В начале июля доступ к сайту был возозбновлён в связи с переносом материала в отдельный архив, доступный для закачки. Позже снова заблокирован, но по состоянию на 2020 год уже удалён из реестра.
- peeep.us — совмещенный с сокращателем ссылок сайт, позволяющий сохранять страницы самим пользователям. Создаёт зеркало страницы на фиксированный момент времени, который отображается вверху жёлтой полосой, с сокращённым URL-адресом. В отличие от веб-архива, щёлкая по ссылкам, открываются веб-страницы на текущий момент времени, а не в архиве. В отличие от archive.is, может сохранять страницы, для просмотра которые видны только сохраняющему, но не остальным людям. Не сохраняет картинки и фреймы. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ, позднее вообще перестал открываться. На июль 2015 года на месте сайта выдаётся ошибка 404. Был разблокирован в начале сентября 2015 года.
- archive.is — сайт, аналогичный peeep.us. Отличается тем, что сохраняет не только основной html-файл страницы, но также и все картинки, стили, фреймы и фонты. Также умеет сохранять страницы с Web2.0-сайтов, например с twitter.com.
Также в роли веб-архивов выступают кеши поисковых систем, но в отличие от первых, они ненадёжны, поскольку могут быстро удаляться. Наибольший срок хранения страниц замечен за Яндексом.
В викисреде
Роль веб-архивов могут выполнять отдельные разделы сайтов, которые сами по себе ими не являются:
Копипаста Луркоморья — сборник заинтересовавших пользователей Луркоморья текстов со страниц Интернета или взятые из книжных источников.
Архивы Викиреальности — сохраняет заслуживающие внимание страницы и творчество, связанное с викисредой. Для архивов выделено специальное пространство имён.
Авторские проекты в Традиции (например, творчество АПЭ, Погребного и т. п.) — сборник творчества различных авторов, которое (в большинстве своём) ранее где-то выкладывалось.
История создания и разработки веб-сайтов
Создателем первого в мире электронного ресурса является ученый Европейской лаборатории элементарных частиц Тим Бернерс-Ли. Именно им в декабре 1990 был разработан первый веб-браузер, который носил название World Wide Web. Сервер был основан на базе NeXTcube.
Правда, еще в сороковые годы ученый Ваннервар (Вэнивар) Буш развивал теорию о том, что с помощью специальных технических устройств можно расширить память человека, проиндексировав информацию, накопленную годами. По мнению ученого, путем проведения такой индексации можно было бы быстро найти необходимую информацию.
9 августа 1991 года появился первый онлайн-ресурс. При создании сайта была использована технология World Wide Web (WWW) и протокол передачи данных Hyper Text Transfer Protocol (HTTP), разработанный с помощью системы адресации Uniform Resource Identifier на языке программировании Hyper Text Markup Language (HTML).
На страницах первого интернет-ресурса были размещены настройки установки и работы браузеров и серверов. Ученый Тим Бернерс-Ли был уверен в том, что гипертекст может быть базой для сетей обмена данных. Свой первый проект Enquire (– гипертекстовое программное обеспечение) Тим Бернерс-Ли разработал в 1980 году.

Стандарт WWW был утвержден в мае 1991 года членами Европейского Центра ядерных исследований в Женеве (CERN). Спецификации HTTP, HTML, URI утверждены были в 1993 году. В 1993 году World Wide Web стала официально бесплатной и свободной для всего мира.
Создание первого в мире сайта

6 августа 1991 года в интернете появился самый первый во всех смыслах сайт, который располагался по электронному адресу info.cern.ch. Создал его, выше упомянутый Тим Бернерс-Ли, который по сути и стал настоящим отцом современных интернет-технологий.
Внешне первый сайт был невзрачен, что совершенно неудивительно. Он представлял собой сплошную стартовую страницу белого цвета, на которой для посетителей размещалась основная информация о инновационной технологии того времени «World Wide Web». Здесь же, на первом во всем мире сайте, были размещены и подробные инструкции по установке браузеров, а также серверов на свои персональные компьютеры, то есть технологию «WWW», можно смело назвать началом современного интернет-пространства, во всех его проявлениях.
По типу и своей простоте, самый первый сайт был интернет-каталогом, одностраничным, невзрачным, но информационно наполненным. Через некоторое время, разработчик позаботился о том, чтобы превратить этот сайт в широкомасштабный каталог, который предоставлял пользователям информацию о других, не менее важных сайтах и перенаправлял посетителей на их страницы, посредством размещенных в каталоге ссылок.
Как признается сам создатель интернета и сайта, не подозревая о том что за столько короткие сроки интернет наберет столь масштабную популярность среди пользователей во всем мире, он создавал свой сайт чтобы разместить на нем адреса всех интернет-порталов, которые будут создаваться в дальнейшем. Но спустя несколько лет, эта затея стала невозможной, да и ненужной, ведь новые сайты стали появляться все чаще, а некоторые старые сайты менять своих владельцев и уходить в прошлое.
Что такое веб-архив?
Для того, чтобы узнать, что такое веб-архив, стоит вспомнить события, произошедшие более 20 лет назад. В 1996 году по инициативе американского программиста, Брюстера Кайла, был создан сайт archiveorg. Благодаря этому ресурсу, любой пользователь может найти сохранённые копии сайтов разных лет.

Со временем библиотека Web archive расширилась и к 2016 году включала в себя 502 миллиарда копий веб-страниц. Это является одним из лучших примеров коллаборации с целью принести обществу пользу. Для того, чтобы посмотреть в реальном времени сайты, которые функционировали некоторое время назад, достаточно зайти в архив и найти его в системе.
Основной целью, которую преследовал Кайл, было сохранение исторические ценности интернет-пространства. Web archive может использовать каждый пользователь, при этом бесплатно. Для работы веб-архива по сохранению интернет-ресурсов может быть только одно препятствие. Если в настройках сайта нет запрета на сохранение информации с ресурса, такой сайт сможет войти в базу веб-архива.
Как происходит пополнение веб-архива? Для этого было создано программное обеспечение, посещающее и сохраняющее сайта с определённой частотой. Так же есть возможность делать сохранения ресурсов вручную. Например, при посещении сайта можно сохранить страницу о курсах СЕО для начинающих или любую другую часть ресурса. Это поможет сохранить информацию с течением времени.
Основная терминология
Сайт представляется пользователю как единое целое. Веб-сайты – это массивы данных во всемирной сети, имеющие уникальные адреса. Интернет-страницы обслуживаются веб-сервером, представляющим собой специальное программное обеспечение, которое доставляет контент клиентам по веб-протоколам. Существуют следующие виды веб-протоколов:
- http – наиболее известный протокол;
- https, использующийся для обеспечения безопасности передачи данных;
- spdy – новый протокол, разработанный компанией Google;
- websocket – еще один более современный протокол, который на сегодняшний день поддерживается только несколькими браузерами.

Существуют коммерческие и некоммерческие ресурсы. Коммерческие веб-сайты – это отличная возможность ведения бизнеса в интернете. Использовать такие интернет-площадки можно для рекламы компаний и продажи товаров. Некоммерческие веб-страницы – это проекты исключительно информационного характера.
Как добавить копию страницы в web archive
Чтобы не дожидаться, пока бот найдёт и сохранит нужную вам страницу, можете добавить её вручную.
Если используете сайт, перейдите в специальный подраздел. Вставьте ссылку на сохраняемую страницу и нажмите Save Page. Отметьте пункт Save error pages, если хотите, чтобы система архивировала в том числе страницы, которые не открываются из-за ошибок.
Если используете приложение, вставьте ссылку на нужную страницу и нажмите Archive Page Now.
Для быстрого добавления страниц можно также использовать расширения для десктопных браузеров. После установки достаточно открыть в браузере нужную ссылку, нажать на кнопку плагина и выбрать Save Page Now.
Зачем проверять историю?
Если вы новичок и не знакомы с тем, что такое фильтры поисковых систем, репутация домена, индексация и ранжирование сайта, то давайте вкратце объясню простыми словами.
В интернете и в любой поисковой системе существует масса алгоритмов, анализирующих каждый ресурс по многим показателям. За время работы сайта он проходит тысячи проверок. Так как на сами данные ресурса не наложить никакие показатели, из-за того, что они постоянно меняются, все параметры проверок закрепляются за его адресом, то есть доменом.
В случае если на сайте долгое время находился неуникальный контент, вирусы, запрещающие материалы (для взрослых, экстремизм, пропаганда наркотиков и другое), покупались или продавались некачественные ссылки, публиковались переоптимизированные статьи, спам и т. д., то скорее всего доменное имя такого сайта находится под фильтрами и заблокировано.
Поэтому, когда вы покупаете подобный домен с плохой историей, будьте готовы, что возникнут проблемы с индексацией и продвижением. Такую ситуацию в онлайне можно сравнить с тюремным заключением, статус “ранее судимый” на имени останется надолго, возможно даже, навсегда, и будет мешать в развитии.
Узнать про все фильтры и блокировки нереально, можно лишь догадываться, анализируя данные, сохранившиеся в истории на некоторых специальных сервисах. Разберём подробно как ими пользоваться.