Как изменить кодировку текстового файла на utf-8 или windows 1251
Содержание:
- Перекодировка текста
- Изменить кодировку в Word Office 365 на Mac
- Собственный велосипед
- Как поменять кодировку в программе?
- Случаи некорректного отображения текста
- Способ 1: 2cyr
- Кодирование текстовой информации и компьютеры
- 1.1 Речь, мимика, жесты
- 2.2 Коды переменной длины
- Сайты для перекодировки онлайн
- Навигатор по конфигурации базы 1С 8.3 Промо
- Как определить кодировку на сайте
- Стандарт Юникод
- Как изменить кодировку символов в Microsoft Word?
- Сохранение файлов в другой кодировке
- Принудительная смена
- Установка кодировки в интерфейсе Блокнота
Перекодировка текста
К сожалению, в разных версиях Word необходимые действия для изменения кодировки различны, хотя и ведут к одинаковому результату. Рассмотрим подробнее необходимые шаги для разных версий в отдельности:
Word 2003
Для того, что бы сменить кодировку, зайдите в меню и выберите СЕРВИС, а затем ПАРАМЕТРЫ. После этого в разделе ЗАКЛАДКА –Общие подтверждаем преобразование при открытии. Теперь при каждом следующем открытии текстового файла, будет предоставлена возможность выбора системы кодирования;
Word 2010, 2007
Эти версии в плане изменения шрифтов ничем не отличаются. В главном меню через ФАЙЛ заходим в ПАРАМЕТРЫ. В новом, выпадающем, окне выбираем раздел ДОПОЛНИТЕЛЬНО и в самом низу окна у Вас будет возможность «разметить документ так, будто он создан … ». Вам будут представлена возможность и создавать, и читать документы в нужном формате.

Изменить кодировку в Word Office 365 на Mac
Как и в Windows, версия Office 365 для Mac также имеет параметры, позволяющие включить проверку формата файла и предложить преобразование.
- Откройте документ Microsoft Word и перейдите в раздел «Word> Настройки…».
- Нажмите «Общие» в разделе «Инструменты разработки и проверки».
- Включите «Подтверждать преобразование формата файла при открытии» в разделе «Настройки».
- Закройте все открытые документы, чтобы изменения вступили в силу.

Включить проверку формата файла в Mac Word
Каждый раз, когда вы открываете несовместимый файл, Word будет отображать преобразованный файл из диалогового окна параметров.
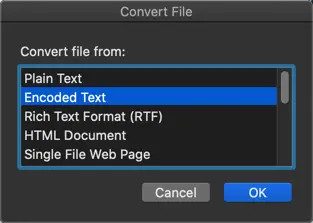
Вариант преобразования файла на Mac
Выберите «Закодированный текст» или формат файла, если вы знаете, и нажмите кнопку «ОК». В следующем диалоговом окне вы можете выбрать вариант «Другая кодировка» и выбрать кодировку «Юникод (UTF-8)».
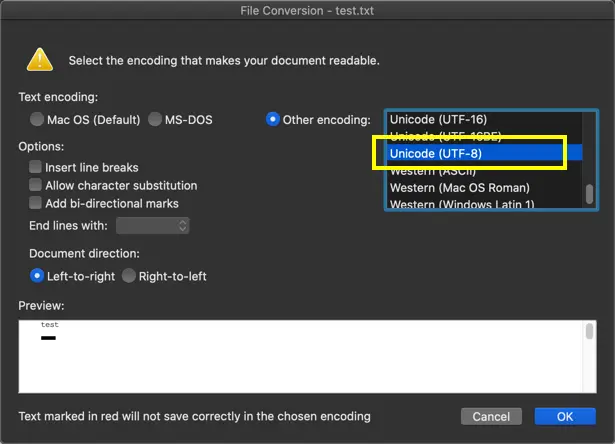
Изменить кодировку в Mac
В отличие от Windows, здесь вы можете четко увидеть предупреждающее сообщение, в котором указывается, какая кодировка делает ваш документ читаемым. Кроме того, вы можете обнаружить, что несовместимый текст отмечен красным цветом с сообщением о том, что этот текст не будет правильно сохранен с выбранной кодировкой.
Кроме того, вы также можете сохранить файл в текстовом формате, чтобы изменить кодировку в Mac так же, как в версии Windows Word.
Просмотры:
225
Собственный велосипед

Автоопределение кодировки возможно только эвристическими методами, не точно. Если мы не знаем на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы.
Второй критерий
К сожалению для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Как поменять кодировку в программе?
Для работы с таблицей, в которой используется стандарт, не заданный по умолчанию в программе, надо изменить кодировку. Существует несколько способов.
При помощи Notepad
Если в Экселе не получается превратить «кракозябры» в нормальный текст, откройте файл в программе «Notepad++». Она распространяется бесплатно. Настройте там отображение символов, а потом продолжайте работать в Excel.
Откройте файл в программе «Notepad++»
- Создайте резервную копию документа. Или сохраните информацию из него в какой-нибудь другой таблице.
- Запустите Notepad.
- Перейдите в Файл — Открыть (File — Open) и укажите путь к таблице. В поле «Тип файла» поставьте «Все типы» («All types»). Или укажите конкретный формат. Таблицы имеют расширения .cvs, .xls, .xltm, xlam, .xlm. В Нотпаде текст отобразится без сетки. В нём ничего не надо редактировать.
- Справа внизу в строке состояния будет изображён стандарт, используемый сейчас.
- Откройте меню Кодировка (Encoding). Оно находится вверху окна.
- Нажмите «Преобразовать в UTF-8» («Convert to UTF-8»). Документ будет конвертирован в нужный формат. Этот стандарт Excel воспринимает нормально и не станет превращать в бессвязный поток странных символов.
- Теперь выберите, какие знаки необходимо использовать. В том же меню Encoding наведите выпадающий список. Он там один.
- Для русского языка выберите Кириллица — Windows-1251. Если текст, скажем, на арабском или греческом — отметьте соответствующий набор символов. В разных странах используются разные стандарты.
- Программа попросит подтвердить действие.
- Если это не помогло, попробуйте другие кириллические шрифты.
- Сохранять текст надо тоже в экселевском формате.
Откройте файл в utf-8
Через интерфейс программы
Вот как сменить кодировку в Excel, используя встроенные возможности:
- Запустите программу. Не надо открывать заполненный документ. Нужен «чистый» лист.
- Перейдите во вкладку «Данные» в строке меню.
- На панели «Получать внешние данные» нажмите «Из текста».
- В списке «Тип файла» (он находится рядом с кнопкой «Отмена») выберите «Все» или «Любые». Так в окне будут отображаться форматы Excel, а не только .txt.
- Задайте путь к таблице.
- Откроется мастер импорта.
- В поле «Формат» можете выбрать желаемый стандарт.
- В области «Предварительный просмотр» показано, как будет выглядеть текст с отмеченным набором символов. Можете прокручивать список и искать, какая настройка подходит.
- Когда подберёте нужный вариант, нажмите «Готово».
Можно использовать встроенные возможности
Случаи некорректного отображения текста
Конечно, когда в программе наотрез отказываются открываться, казалось бы, родные форматы, это поправить очень сложно, а то и практически невозможно. Но, бывают случаи, когда они открываются, а их содержимое невозможно прочесть. Речь сейчас идет о тех случаях, когда вместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, «перевести» которые невозможно.
Эти случаи чаще всего связаны лишь с одним — с неверной кодировкой текста. Точнее, конечно, будет сказать, что кодировка не неверная, а просто другая. Не воспринимающаяся программой. Интересно еще то, что общего стандарта для кодировки нет. То есть, она может разниться в зависимости от региона. Так, создав файл, например, в Азии, скорее всего, открыв его в России, вы не сможете его прочитать.
В этой статье речь пойдет непосредственно о том, как поменять кодировку в Word. Кстати, это пригодится не только лишь для исправления вышеописанных «неисправностей», но и, наоборот, для намеренного неправильного кодирования документа.
Способ 1: 2cyr
Онлайн-сервис 2cyr поддерживает практически все популярные кодировки, а также позволяет исправить запись разными способами в зависимости от известной о кодировке информации. Для преобразования текста в читабельный вид при помощи данного сайта осуществите следующие действия:
- Воспользуйтесь ссылкой выше, чтобы открыть главную страницу сайта 2cyr. Кликните по соответствующему полю для его активации.
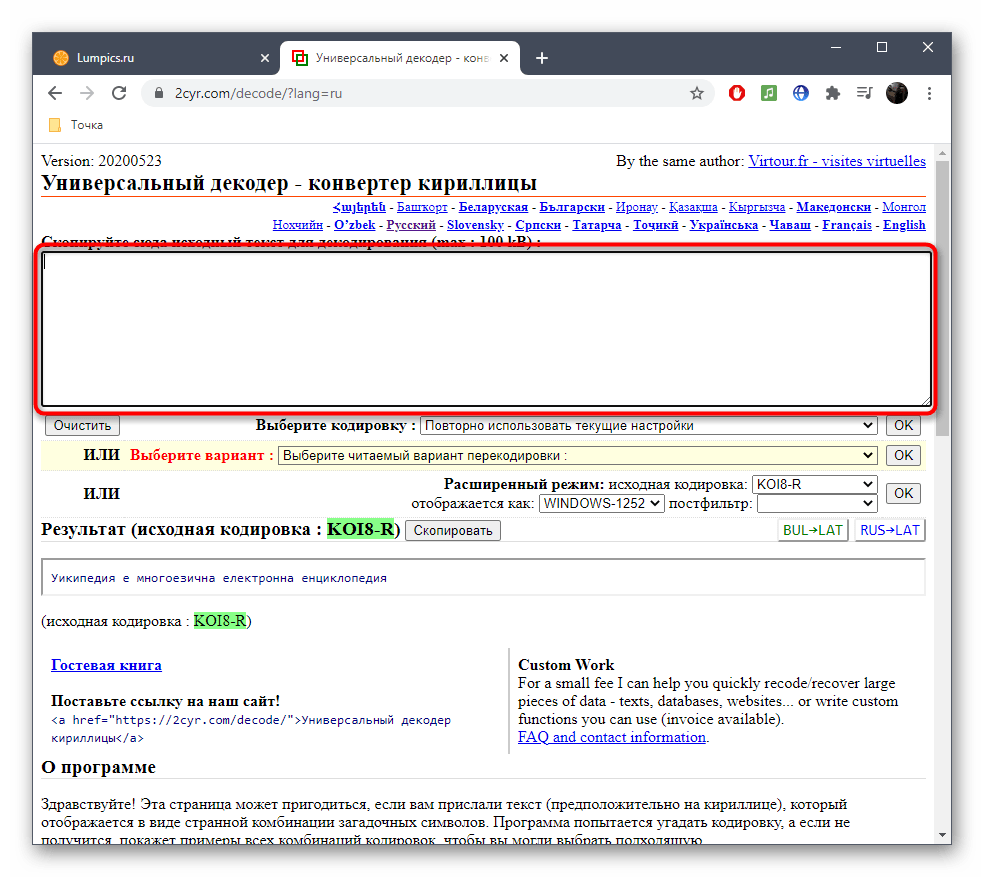
Скопируйте текст в неверной кодировке и вставьте его в данное поле. Для этого можно использовать стандартные сочетания клавиш Ctrl + C и Ctrl + V.
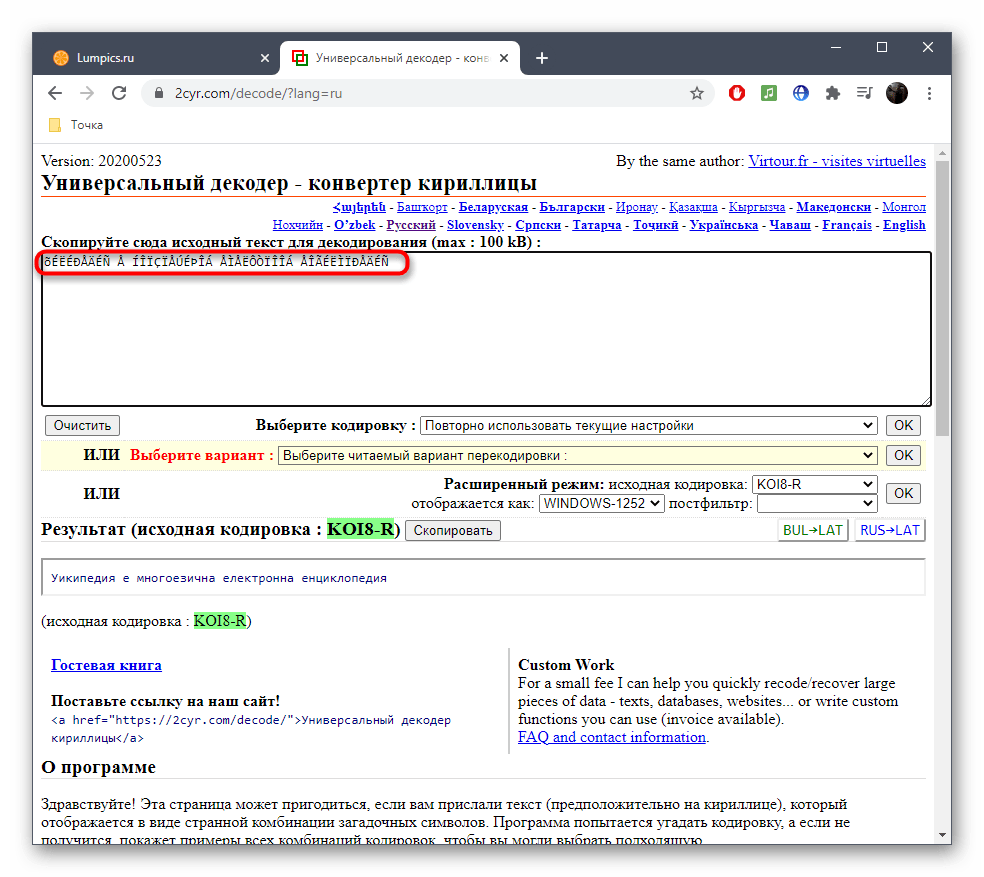
Если известен формат поврежденной кодировки, его можно сразу же выбрать в отдельном меню, чтобы получить правильное исправление.
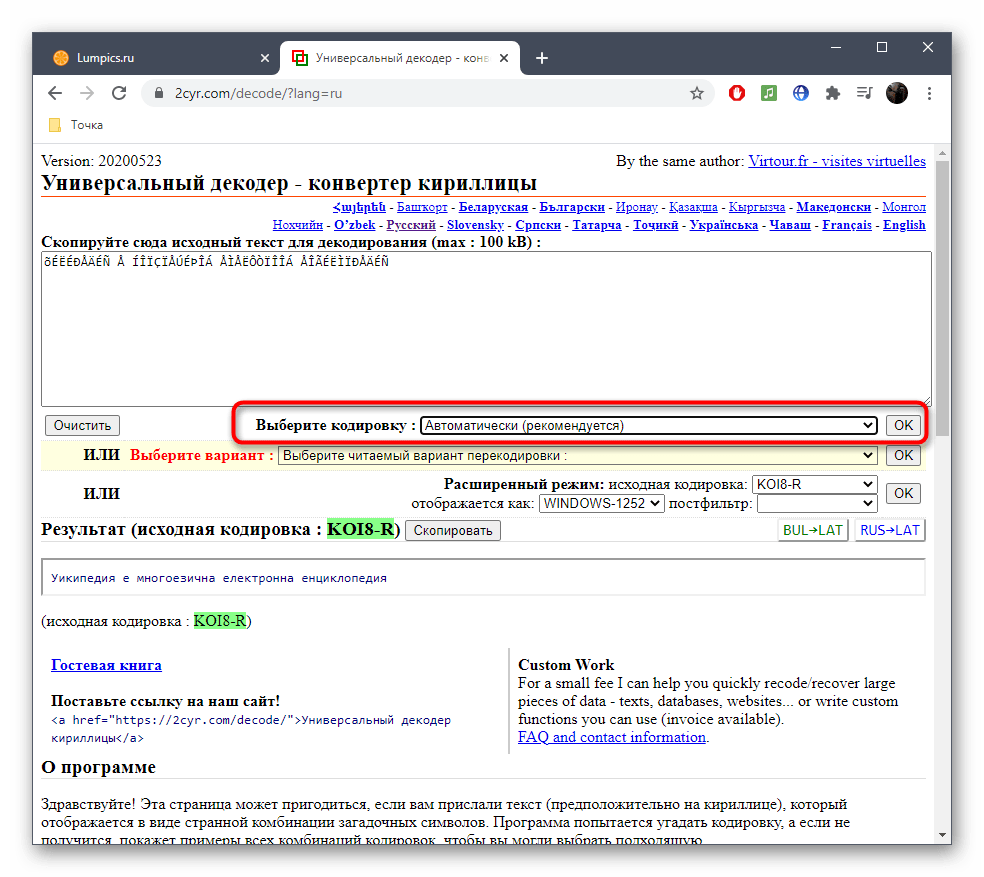
Второй вариант декодирования подразумевает просмотр результата на всех присутствующих в онлайн-сервисе кодировках. Для этого надо развернуть выпадающее меню и найти там читаемый вариант.
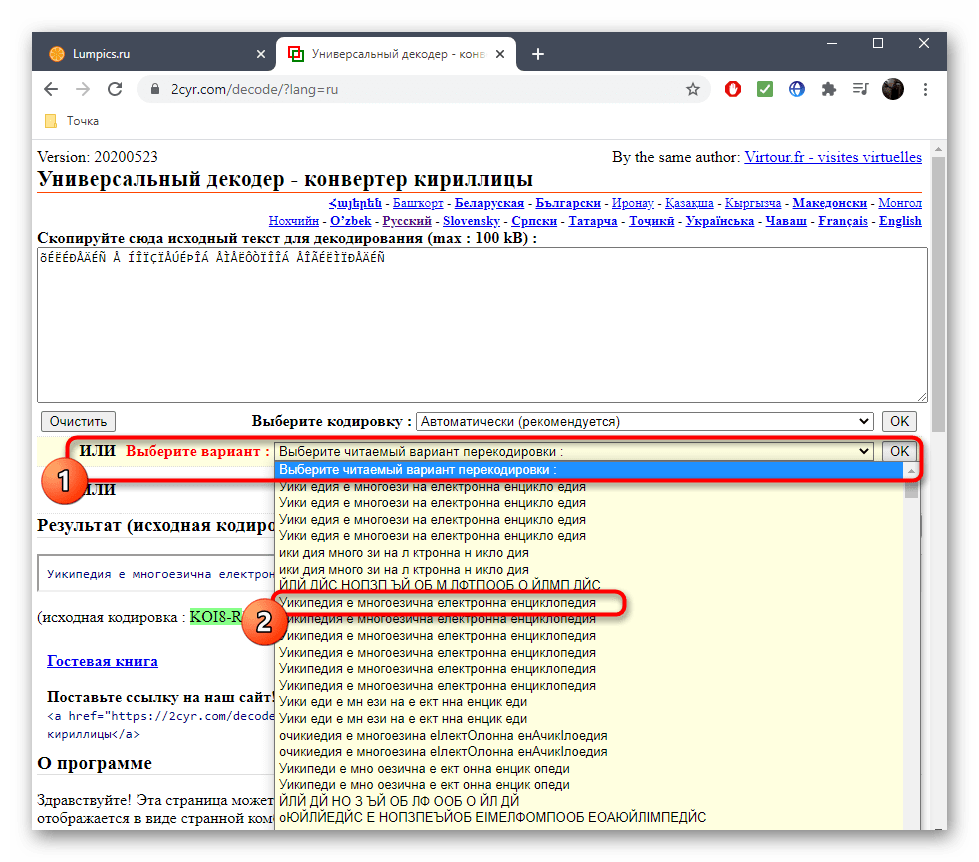
После этого подтвердите свой выбор, кликнув «ОК», ведь только так можно скопировать готовый текст.
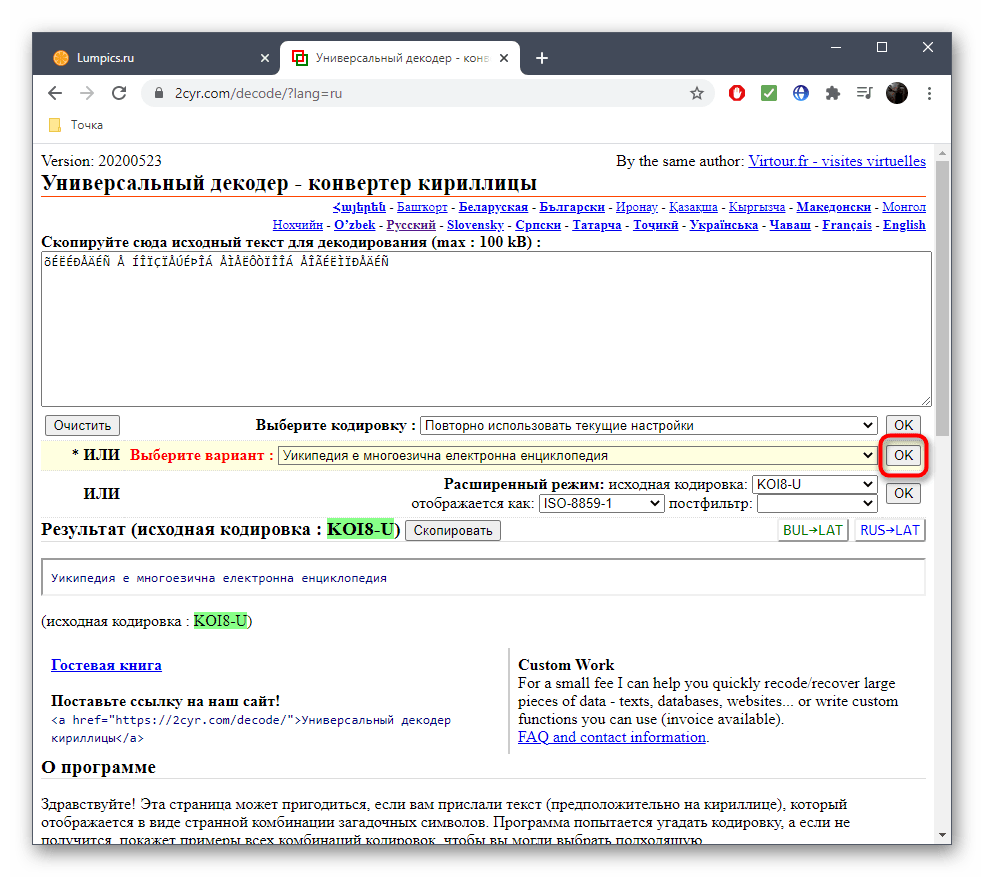
Он будет отображаться внизу и доступен для копирования. Выделите его зажатой левой кнопкой мыши и используйте упомянутые выше комбинации, чтобы скопировать и вставить в необходимый текстовый документ.
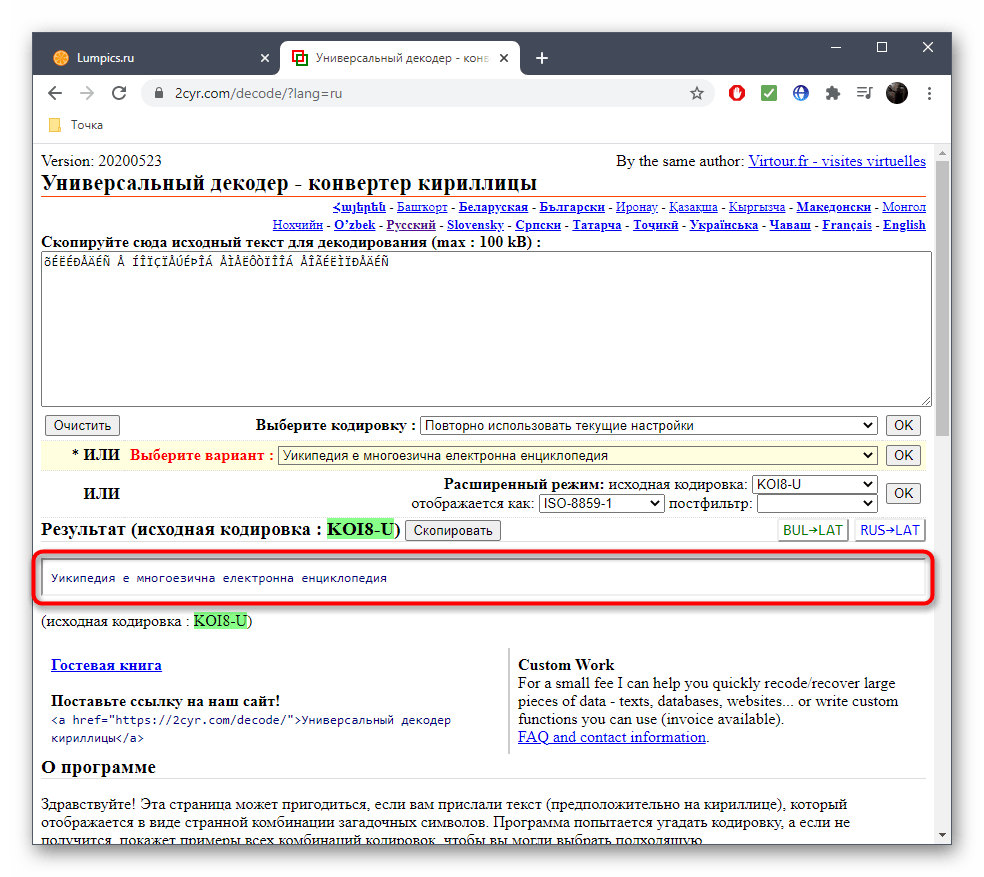
Исходную кодировку вы видите выше — она отмечена зеленым цветом. Иногда это нужно пользователям при ее декодировании.
Данный сайт корректно исправляет любую кодировку, которая есть в списке поддерживаемых, поэтому вы можете взять его на вооружение и использовать в любой момент по необходимости.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

1.1 Речь, мимика, жесты
Удивительно, но всё это — коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях
Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода — улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости
Следуя определению, что же происходит когда мы говорим? Мысль — как форма, удобная для непосредственного использования, преобразуется в речь — форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда — человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
2.2 Коды переменной длины
Воспользуемся той же строкой и таблицей и попробуем данные закодировать иначе. Уберём блоки фиксированного размера и представим данные исходя из их частоты использования — чем чаще данные используются, чем меньше бит мы будем использовать. У нас получится вторая таблица:
|
Символ |
Количество |
Переменный код, бит |
|---|---|---|
|
ПРОБЕЛ |
18 |
|
|
Р |
12 |
1 |
|
К |
11 |
00 |
|
Е |
11 |
01 |
|
У |
9 |
10 |
|
А |
8 |
11 |
|
Г |
4 |
000 |
|
В |
3 |
001 |
|
Ч |
2 |
010 |
|
Л |
2 |
011 |
|
И |
2 |
100 |
|
З |
2 |
101 |
|
Д |
1 |
110 |
|
Х |
1 |
111 |
|
С |
1 |
0000 |
|
Т |
1 |
0001 |
|
Ц |
1 |
0010 |
|
Н |
1 |
0011 |
|
П |
1 |
0100 |
Для подсчёта длины закодированного сообщения мы должны сложить все произведения количества символов на длины кодов в битах и тогда получим 179 бит.
Но такой способ, хоть и позволил прилично сэкономить память, но не будет работать, потому что невозможно его раскодировать. Мы не сможем в такой ситуации определить, что означает код «111», это может быть «РРР», «РА», «АР» или «Х».
Сайты для перекодировки онлайн
Сегодня мы расскажем о самых популярных и действенных сайтах, которые помогут угадать кодировку и изменить ее на более понятную для вашего ПК. Чаще всего на таких сайтах работает автоматический алгоритм распознавания, однако в случае необходимости пользователь всегда может выбрать подходящую кодировку в ручном режиме.
Способ 1: Универсальный декодер
Декодер предлагает пользователям просто скопировать непонятный отрывок текста на сайт и в автоматическом режиме переводит кодировку на более понятную. К преимуществам можно отнести простоту ресурса, а также наличие дополнительных ручных настроек, которые предлагают самостоятельно выбрать нужный формат.
Работать можно только с текстом, размер которого не превышает 100 килобайт, кроме того, создатели ресурса не гарантируют, что перекодировка будет в 100% случаев успешной. Если ресурс не помог – просто попробуйте распознать текст с помощью других способов.
- Копируем текст, который нужно декодировать, в верхнее поле. Желательно, чтобы в первых словах уже содержались непонятные символы, особенно в случаях, когда выбрано автоматическое распознавание.
- Указываем дополнительные параметры. Если необходимо, чтобы кодировка была распознана и преобразована без вмешательства пользователя, в поле «Выберите кодировку» щелкаем на «Автоматически». В расширенном режиме можно выбрать начальную кодировку и формат, в который нужно преобразовать текст. После завершения настройки щелкаем на кнопку «ОК».
- Преобразованный текст отобразится в поле «Результат», оттуда его можно скопировать и вставить в документ для последующего редактирования.
Способ 2: Студия Артемия Лебедева
Еще один сайт для работы с кодировкой, в отличие от предыдущего ресурса имеет более приятный дизайн. Предлагает пользователям два режима работы, простой и расширенный, в первом случае после декодировки пользователь видит результат, во втором случае видна начальная и конечная кодировка.
- Выбираем режим декодировки на верхней панели. Мы будем работать с режимом «Сложно», чтобы сделать процесс более наглядным.
- Вставляем нужный для расшифровки текст в левое поле. Выбираем предполагаемую кодировку, желательно оставить автоматические настройки — так вероятность успешной дешифровки возрастет.
- Щелкаем на кнопку «Расшифровать».
- Результат появится в правом поле. Пользователь может самостоятельно выбрать конечную кодировку из ниспадающего списка.
С сайтом любая непонятная каша из символов быстро превращается в понятный русский текст. На данный момент работает ресурс со всеми известными кодировками.
Способ 3: Fox Tools
Fox Tools предназначен для универсальной декодировки непонятных символов в обычный русский текст. Пользователь может самостоятельно выбрать начальную и конечную кодировку, есть на сайте и автоматический режим.
Дизайн простой, без лишних наворотов и рекламы, которая мешает нормальной работе с ресурсом.
- Вводим исходный текст в верхнее поле.
- Выбираем начальную и конечную кодировку. Если данные параметры неизвестны, оставляем настройки по умолчанию.
- После завершения настроек нажимаем на кнопку «Отправить».
- Из списка под начальным текстом выбираем читабельный вариант и щелкаем на него.
- Вновь нажимаем на кнопку «Отправить».
- Преобразованный текст будет отображаться в поле «Результат».
Несмотря на то, что сайт якобы распознает кодировку в автоматическом режиме, пользователю все равно приходится выбирать понятный результат в ручном режиме. Из-за данной особенности куда проще воспользоваться описанными выше способами.
Рассмотренный сайты позволяют всего в несколько кликов преобразовать непонятный набор символов в читаемый текст. Самым практичным оказался ресурс Универсальный декодер — он безошибочно перевел большинство зашифрованных текстов.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.83 от 24.06.2021
3 стартмани
Как определить кодировку на сайте
Определить кодировку страницы своего или чужого сайта можно через исходный код страницы. Откройте страницу сайта, выберите «Просмотр кода страницы» (сочетание горячих клавиш Ctrl+U» в Google Chrome) и найдите упоминание «charset» внутри тега head.
На странице сайта используется кодировка UTF-8:
 Указание кодировки в коде страницы
Указание кодировки в коде страницы
Узнать вид кодирования можно с помощью «Анализа сайта». Сервис проверяет в том числе и техническую сторону ресурса: анализирует серверную информацию, определяет кодировку, проверяет редиректы и другие пункты.
 Фрагмент анализа серверной информации сайта
Фрагмент анализа серверной информации сайта
С помощью этого же сервиса можно проверить корректность указанного кодирования. Аудит внутренних страниц «Анализа сайта» проверяет кодировку сервера и сравнивает ее с той, которая указана на внутренней странице. Найденные ошибки Анализ покажет в результатах проверки, и вы сразу узнаете, где нужно исправить.
 Отчет о технических данных
Отчет о технических данных
 Кодировка сервера и страницы
Кодировка сервера и страницы
Проверить кодировку еще можно через сервис Validator.w3, о котором писали в статье о проверке валидации кода. Нужная надпись находится внизу страницы.
 Кодировка сайта в валидаторе
Кодировка сайта в валидаторе
Если валидатор не обнаружит Charset, он покажет ошибку:
 Ошибка указания кодировки
Ошибка указания кодировки
Но валидатор работает не точно: он проверяет только синтаксис разметки, поэтому может не показать ошибку, даже если кодирование указано неправильно.
Стандарт Юникод
Консорциум Unicode (Юникод) – некоммерческая организация, главной задачей которой являлась разработка стандарта кодирования (стандарт Юникод) с поддержкой наибольшего числа языков и символов служебного характера. Принцип кодирования на основе таблицы сохранился, а таблица (таблица Юникод) была значительно расширена.
Стандарт Юникод предоставляет пользователям таблицу Юникод и способы кодирования символов.
Символы таблицы Юникод являются элементами «универсального набора символов» UCS (Universal Coded Character Set), определенного международным стандартом ISO/IEC 10646. Таблица Юникод каждому символу UCS сопоставляет кодовую точку, которая является номером ячейки таблицы, содержащей символ.
Способы кодирования символов таблицы Юникод, т.е. преобразования номеров ячеек таблицы Юникод в бинарные коды, составляют кодовое пространство, состоящее из трех кодов семейства UTF (Unicode Transformation Format): UTF-8, UTF-16 и UTF-32
UTF-8 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32.
UTF-16 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Коды UTF-8 и UTF-16 используют разные алгоритмы кодирования набора символов UCS.
Как изменить кодировку символов в Microsoft Word?
Каждый раз, когда вы открываете несовместимый документ, Word будет отображать диалог преобразования файла. Однако, если вы его не видите, эту опцию легко включить. Вы можете открыть любой документ Word, чтобы включить этот параметр, так как он будет применен ко всем документам.
Включение диалогового окна преобразования формата файла
- Откройте документ и перейдите в меню «Файл> Параметры».
- Щелкните раздел «Дополнительно» и прокрутите вниз до раздела «Общие» на правой панели.
- По умолчанию Word отключает параметр «Подтверждать преобразование формата файла при открытии».
- Установите флажок, чтобы включить эту опцию.
- Нажмите «ОК», чтобы применить изменения и закрыть все открытые документы.
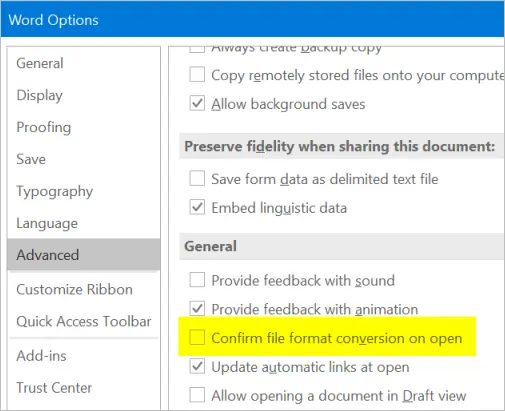
Подтвердить преобразование формата файла при открытии
Этот параметр поможет вам запускать диалоговое окно при открытии файлов в форматах, отличных от .doc или .docx. Например, если вы используете Word для открытия обычного текстового файла с расширением .txt, вы получите запрос на проверку формата файла.
Связанный: Как изменить имя встроенного файла в Word?
Изменить кодировку символов
Теперь откройте файл, в котором вы хотите изменить кодировку символов. Word покажет вам диалоговое окно «Преобразовать файл», как показано ниже.
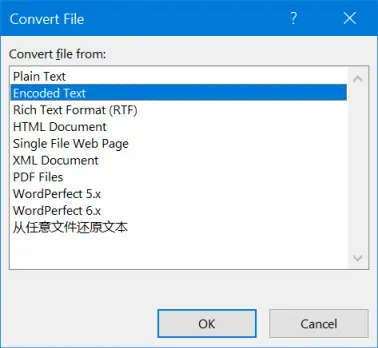
Конвертировать файл
Выберите формат файла, если вам нравится обычный текст или документ HTML. Если вам непонятно, выберите опцию «Закодированный текст» и нажмите кнопку «ОК». Затем вы увидите диалоговое окно «Преобразование файла». Как правило, «Windows (по умолчанию)» выбирает кодировку в зависимости от настроек локали. Это может создать проблемы при просмотре специальных символов и знаков.
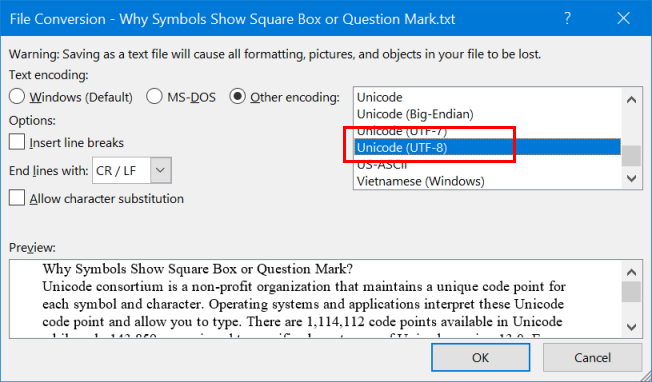
Преобразование файлов с изменением кодировки
Выберите «Другая кодировка», чтобы активировать список рядом. Вы увидите список доступных в списке вариантов кодировки и выберите формат «Unicode (UTF-8)». При необходимости выберите вставку разрывов строк и разрешите варианты замены символов. Нажмите «ОК», чтобы завершить процесс. Теперь вы успешно изменили кодировку символов файла на UTF-8.
Это поможет вам просматривать содержимое файла в удобочитаемом формате, так как UTF-8 должен поддерживать большинство символов.
Отключить преобразование файлов
После того, как вы закончите изменять кодировку символов файла, обязательно отключите опцию преобразования файла. Вернитесь в «Файл> Параметры» и измените настройки в разделе «Дополнительно». Это поможет вам в будущем отключить диалог преобразования файлов.
Сохранение файлов в другой кодировке
Вы не можете изменить кодировку файла, который вы сохраняете как файл .docx. Word назначит кодировку символов по умолчанию на основе вашей региональной языковой установки или UTF-8. Однако вы можете изменить кодировку, изменив файл в текстовом формате.
- Перейдите в меню «Файл» и выберите «Сохранить как».
- Щелкните раскрывающийся список «Сохранить как тип» и выберите вариант «Обычный текст».
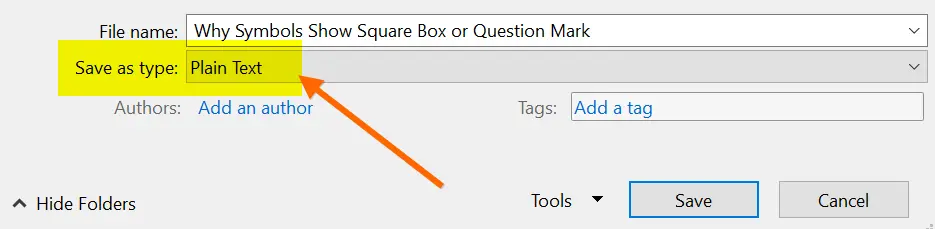
Сохранить документ Word в виде обычного текста
Нажмите кнопку «Сохранить», и Word откроет диалоговое окно «Преобразование файла», как описано выше. Оттуда вы можете изменить кодировку и сохранить документ.
Принудительная смена
Если вы получили из какого-то источника текстовый файл, но не можете прочитать его содержимое, то нужна операция ручной смены кодировки. Для этого зайдите в раздел «Сведения» во вкладке «Файл». Тут собраны глобальные настройки распознавания и отображения, и если вы будете изменять их в открытом документе, то для него они станут индивидуальными, а для остальных — не изменятся. Воспользуемся этим. В разделе «Дополнительно» появившегося окна находим заголовок «Общие» и ставим галочку «Подтверждать преобразование файлов при открытии». Подтвердите изменения и закройте Word. Теперь откройте документ снова, как бы применяя настройки, и перед вами появится окно преобразования файла. В нём будет список возможных форматов, среди которых находим «Кодированный текст», и получим следующий диалог.
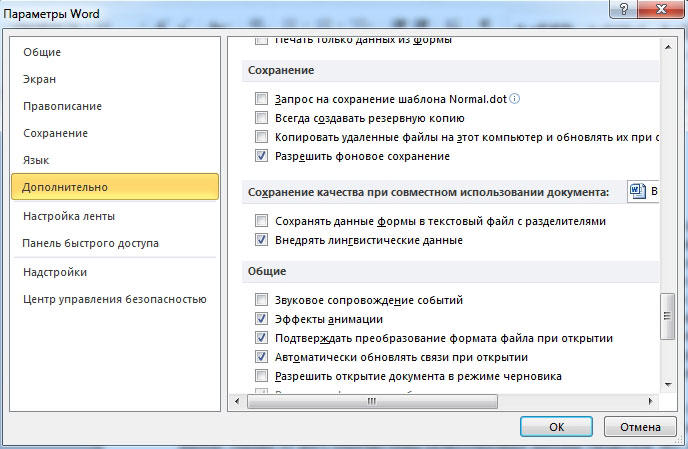
В этом новом окне будет три переключателя. Первый, по умолчанию, — это CP-1251, кодировка Windows. Второй — MS-DOS. Нам нужен третий пункт — ручной выбор, справа от него перечислены разнообразные наборы символов. Но, как правило, пользователь не знает, какими символами был набран текст предыдущим автором, поэтому в нижней части этого окна есть поле под названием «Образец», в котором фрагмент из текста будет в реальном времени отображаться при выборе того или иного комплекта символов. Это очень удобно, потому что не нужно каждый раз закрывать и отрывать документ снова, чтобы подобрать нужную.
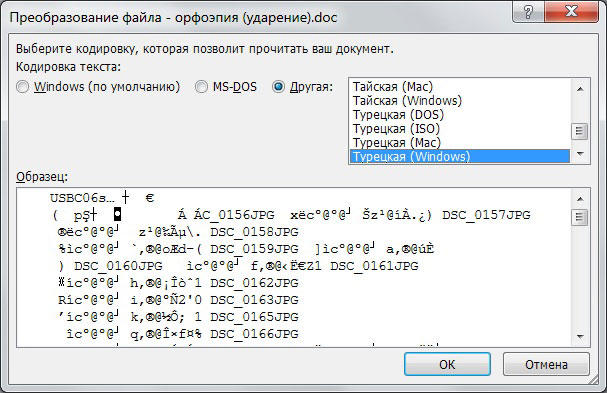
Перебирая варианты по одному и глядя на текст в поле образцов, выберите ту кодировку, при которой символы будут русскими
Но обратите внимание, что это ещё ничего не значит, — внимательно смотрите, чтобы они складывались в осмысленные слова. Дело в том, что для русского языка есть не одна кодировка, и текст в одной из них не будет отображаться корректно в другой
Так что будьте внимательны.
Нужно сказать, что с файлами, сделанными на современных текстовых процессорах, крайне редко возникают подобные проблемы. Однако есть ещё и такой бич современного информационного общества, как несовместимость форматов. Дело в том, что существует целый ряд текстовых редакторов, и каждым кто-то пользуется. Возможно, для кого-то не нужна функциональность Ворда, кто-то не считает нужным за него платить и т. п. Причин может быть множество.
Если при сохранении документа автор выбрал формат, совместимый в MS Word, то проблем возникнуть не должно. Но так бывает нечасто. Например, если текст сохранён с расширением .rtf, то диалог выбора кодировки отобразится перед вами сразу же при открытии текста. А вот форматы другого популярного текстового процессора OpenOffice Ворд даже не откроет, поэтому, если им пользуетесь, не забывайте выбирать пункт «Сохранить как», когда отправляете файл пользователю Office.
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» , будет полезно знать о том, что изменить кодировку можно следующим образом:
- Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как». Нажимаем по вкладке «Файл», затем по опции «Сохранить как»
- В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить». В параметре «Кодировка» выбираем подходящий формат, нажимаем «Сохранить»
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Видео — Как изменить кодировку в Word
Ввиду того, что текстовый редактор «Майкрософт Ворд» является самым популярным на рынке, именно форматы документов, которые присущи ему, можно чаще всего встретить в сети. Они могут отличаться лишь версиями (DOCX или DOC). Но даже с этими форматами программа может быть несовместима или же совместима не полностью.