Третья нормальная форма — third normal form
Содержание:
- Инфологическое проектирование
- Классический пример приведения таблиц базы данных к четвертой нормальной форме
- Третья нормальная форма
- Описание шестой нормальной формы (6NF)
- Что такое нормализация данных и чем она отличается от нормировки и нормирования
- Нормализация и стандартизация — методы шкалирования данных
- Первая нормальная форма[править]
- Нормализация данных: методы и формулы
- Сначала поймите разницу между дисперсией, стандартным отклонением и среднеквадратичной ошибкой.
- Цель нормализации
- Демормализация в базе данных: «звезда» и «снежинка»
- 1НФ — первая нормальная форма
- «Ничего, кроме ключа»
Инфологическое проектирование
- Инфологическое проектирование
- построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции.
Такие модели, как правило, строятся без ориентации на конкретную СУБД или даже модель данных. Смысл построения инфологической модели заключается в выделении основных сущностей предметной области и их свойств (атрибутов).
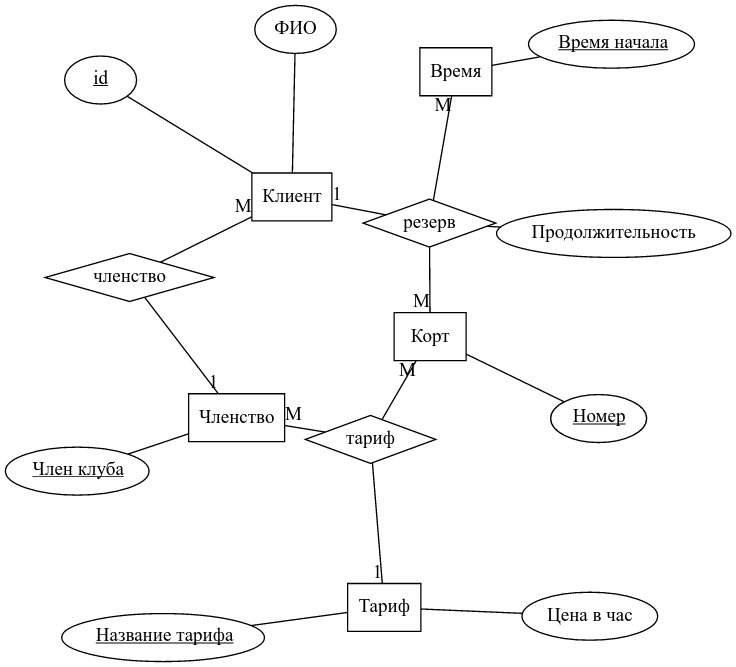
Один из популярных способов построения инфологической модели – построение ER-диаграмм.
ER-диаграммы
В отличие от диаграмм атрибутов, ER-диаграммы, кроме непосредственно атрибутов, включают так же в явном виде “сущности” и “связи” между ними, откуда, собственно, и происходит название: entity-relationship diagram, или диаграмма сущности-связи.
И сущности, и связи могут обладать набором атрибутов. Сущности без атрибутов – явление достаточно бессмысленное, как Кантовская “вещь в себе”. Связи без атрибутов – явление, напротив, весьмя распространенное.
Строго говоря, на диаграмме обозначаются классы сущностей. Во избежание путаницы, под словом “сущность” будем понимать набор атрибутов, а набор значений этих атрибутов будем называть экземпляром сущности.
В наиболее распространенной нотации, атрибуты обозначаются овалами, сущности – прямоугольниками, а связи – ромбами.
Сущности и связи соединяются между собой линиями. Существуют различные нотации, подразумевающие различную степень подробности описания. Мы будем использовать упрощенную схему, в которой для каждой линии надписывается, как раз сущность участвует в связи: 1 или много раз (М). В связи могут участвовать две или более сущностей. Хотя многозначные связи (связи, в которых участвуют более двух сущностей) – не слишком распространенное явление, иногда они бывают необходимы.
Для каждой сущности могут быть выделены один или несколько идентифицирующих атрибутов, так же, по аналогии с реляционной моделью, называемых ключом. Значения ключа сущности однозначно идентифицируют экземпляр сущности, так же как значение потенциального ключа отношения однозначно идентифицирует запись. Понятно, что ключей может быть несколько – по крайней мере один ключ, включающий все атрибуты сущности, должен существовать – назовем его тривиальным. Кроме того, возможно существуют ключи-подмножества тривиального. Условимся, что из всех ключей мы выбираем один минимальный, и используем его (назовем его первичным).
Атрибуты, входящие в первичный ключ на ER-диаграмме подчеркиваются.
Рассмотрим ER-диаграмму для примера с теннисными кортами.
Классический пример приведения таблиц базы данных к четвертой нормальной форме
Чтобы стало еще понятней, давайте закрепим знания и рассмотрим классический пример, который обычно используется в литературе для пояснения четвертой нормальной формы.
Таблица связей студентов, курсов и хобби.
| Студент | Курс | Хобби |
| Иванов И.И. | SQL | Футбол |
| Иванов И.И. | Java | Хоккей |
| Сергеев С.С. | SQL | Волейбол |
| Сергеев С.С. | SQL | Теннис |
| John Smith | Python | Футбол |
| John Smith | Java | Теннис |
Данная таблица хранит информацию о студентах, в частности здесь хранятся курсы, которые посещает студент, и увлечения этого студента, т.е. хобби.
Отсюда следует, что каждый студент может посещать несколько курсов и иметь несколько увлечений.
Первичный ключ здесь также составной и состоит он из всех трех столбцов.
При этом мы можем заметить, что курс и хобби никак не связаны и не зависят друг от друга, но по отдельности зависят от студента.
Таким образом, мы можем наблюдать в этой таблице нетривиальную многозначную зависимость
Студент ->-> Курс
Студент ->-> Хобби
Поэтому эта таблица не находится в четвертой нормальной форме.
Кроме всех тех аномалий, связанных с редактированием данных, которые мы уже рассмотрели на предыдущем примере, в данном случае еще продемонстрирована проблема неоднозначной выборки данных.
Допустим, нам необходимо получить информацию о хобби студентов, которые посещают курс по SQL. Очевидным действием станет выборка с условием Курс = SQL, в результате мы получим 3 хобби: футбол, волейбол и теннис.
Результат выборки. Хобби студентов, которые посещают курс по SQL.
| Студент | Курс | Хобби |
| Иванов И.И. | SQL | Футбол |
| Сергеев С.С. | SQL | Волейбол |
| Сергеев С.С. | SQL | Теннис |
Однако, если мы заглянем в исходную таблицу, то мы четко увидим, что «Иванов И.И.» посещает курс по SQL и имеет хобби «Хоккей», но в нашей выборке этого хобби нет.
Чтобы нормализовать эту таблицу, мы должны точно так же, как и в предыдущем примере, разбить ее на две.
Связь студентов и курсов.
| Студент | Курс |
| Иванов И.И. | SQL |
| Иванов И.И. | Java |
| Сергеев С.С. | SQL |
| John Smith | Python |
| John Smith | Java |
Связь студентов и хобби.
| Студент | Хобби |
| Иванов И.И. | Футбол |
| Иванов И.И. | Хоккей |
| Сергеев С.С. | Волейбол |
| Сергеев С.С. | Теннис |
| John Smith | Футбол |
| John Smith | Теннис |
Однако в реальности такую ситуацию и такую таблицу вряд ли можно встретить, так как следуя здравому смыслу такие абсолютно не связанные друг с другом данные никто не будет хранить в одной таблице. Поэтому этот пример чисто теоретический и приводится для демонстрации принципов четвертой нормальной формы.
И если говорить о реальных данных, то нормализация до четвертой нормальной формы, как и до всех последующих, в современном мире практически не встречается. Если четвертую нормальную форму еще как-то можно представить и даже встретить данные, нормализованные до этой формы, то встретить данные, нормализованные до 5 или 6 нормальной формы, практически невозможно.
Вы можете спросить, а почему не нормализуют данные до 5 или 6 нормальной формы? Ведь каждая нормальная форма устраняет определенные аномалии, и если сделать полностью нормализованную базу данных, то по сути она будет идеальная, не содержащая ни одной аномалии, это же хорошо.
Да, совершенно верно, база данных не будет содержать аномалий, но давайте вспомним, какие преимущества нам дает нормализация.
Обычно во всех источниках приводится два основных глобальных преимущества:
- Устранение аномалий
- Повышение производительности
Если с устранением аномалий все ясно, т.е. в полностью нормализованной базе данных их не будет и это хорошо, то с повышением производительности не все так однозначно.
Да, нормализация повышает производительность, но только где-то до 3 нормальной формы. Начиная с 4 нормальной формы, производительность увеличиваться не будет, более того, с каждой новой формой производительность будет значительно снижаться, не говоря уже о том, что с нормализованной базой данных до 5 или 6 нормальной формы будет крайне сложно и неудобно работать и сопровождать ее, ведь с каждой новой формой мы значительно увеличиваем количество таблиц в базе данных.
Поэтому процесс нормализации не является строго обязательным, т.е. не нужно нормализовать базу данных, только для того чтобы она была нормализована.
В процессе проектирования базы данных необходимо следовать здравому смыслу и найти баланс между отсутствием аномалий и приемлемой производительностью.
Полностью нормализованная база данных – это плохая база данных.
После того как мы привели таблицы базы данных к четвертой нормальной форме, мы можем переходить к приведению таблиц до пятой нормальной формы (5NF). Описание, требования и пример приведения таблиц до пятой нормальной формы мы рассмотрим в следующем материале.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Нравится54Не нравится
Третья нормальная форма
Значения в записи, которая не входит в ключ этой записи, не относятся к таблице. В общем, в любое время содержимое группы полей может применяться к более чем одной записи в таблице, рассмотрите возможность размещения этих полей в отдельной таблице.
Например, в таблице набора сотрудников может быть включено имя и адрес университета кандидата. Но для групповой рассылки необходим полный список университетов. Если сведения о университетах хранятся в таблице Candidates, нет возможности перечислять университеты без текущих кандидатов. Создайте отдельную таблицу университетов и привяжете ее к таблице Кандидаты с ключом кода университета.
ИСКЛЮЧЕНИЕ: применение третьей обычной формы, хотя теоретически желательно, не всегда является практическим. Если у вас есть таблица Клиентов и вы хотите устранить все возможные зависимости между полями, необходимо создать отдельные таблицы для городов, почтовых индексов, представителей продаж, классов клиентов и любого другого фактора, который может быть дублирован в нескольких записях. В теории, нормализация стоит очистки. Однако многие небольшие таблицы могут ухудшать производительность или превышать возможности открытого файла и памяти.
Возможно, более целесообразно применять третью нормальную форму только к данным, которые часто меняются. Если остаются некоторые зависимые поля, спроектировать приложение, чтобы потребовать от пользователя проверить все связанные поля при их смене.
Описание шестой нормальной формы (6NF)
Шестая нормальная форма (6NF) была введена при работе с хронологическими базами данных.
Хронологическая база данных – это база, которая может хранить не только текущие данные, но и исторические данные, т.е. данные, относящиеся к прошлым периодам времени. Однако такая база может хранить и данные, относящиеся к будущим периодам времени.
В процессе проектирования хронологических баз данных возникают некоторые особые проблемы, решить которые можно с помощью: горизонтальной декомпозиции и вертикальной декомпозиции.
В данном случае нас интересует вертикальная декомпозиция, процесс которой очень сильно напоминает нашу классическую нормализацию, которую мы рассматривали до пятой нормальной формы включительно.
Иными словами, декомпозиция таблиц, которую мы использовали для приведения этих таблиц к той или иной нормальной форме, по факту и является вертикальной декомпозицией.
В процессе изучения хронологических баз данных исследователи выдвигали доводы в пользу максимально возможной вертикальной декомпозиции таблиц, а не просто их декомпозиции до какой-то определённой степени, которую требует классическая теория нормализации. Общая идея состояла в том, что таблицы должны быть приведены к неприводимым компонентам, под этим подразумеваются такие компоненты, для которых дальнейшая декомпозиция без потерь становится невозможной.
Теперь стоит напомнить, что пятая нормальная форма основана на так называемых зависимостях соединения.
А поскольку вертикальная декомпозиция, которая используется в хронологических базах данных, представляет собой классическое разделение таблиц на проекции, была сформулирована новая нормальная форма, основанная на обобщенном понятии зависимости соединения, поэтому новую форму назвали «Шестая нормальная форма».
Из этого определения следует, что таблица находится в 6NF, когда она неприводима, то есть не может быть подвергнута дальнейшей декомпозиции без потерь. Стоит отметить, что таблица, которая находится в 6NF, также находится и в 5NF, и во всех предыдущих.
Шестая нормальная форма вводит такое понятие как «Декомпозиция до конца», т.е. максимально возможная декомпозиция таблиц.
Однако, если в хронологических базах данных такая нормализация может быть полезна, так как она позволяет бороться с избыточностью, то в нехронологических базах данных нормализация таблиц до шестой нормальной формы приведёт к значительному снижению производительности. Кроме этого такая нормализация сделает работу с базой данных очень сложной за счет многократного увеличения количества таблиц.
Поэтому шестую нормальную форму в реальном мире не используют, более того, трудно даже представить себе ситуацию, при которой возникала бы необходимость нормализовать базу данных до шестой нормальной формы. Практического применения шестой нормальной формы, наверное, просто нет.
Здесь снова давайте вспомним, что нет никакой необходимости приводить базу данных до какой-то определенной нормальной формы.
Поэтому в процессе нормализации базы данных необходимо руководствоваться в первую очередь требованиями к разрабатываемой системе и требованиями предметной области. Вы должны подумать о том, какие именно операции (действия) будут выполняться над данными. Так все ошибки нормализации станут очевидными и Вы сможете увидеть, какие аномалии могут возникнуть в тех или иных случаях, и принимать решения о нормализации, иными словами, Вы должны руководствоваться здравым смыслом.
Что такое нормализация данных и чем она отличается от нормировки и нормирования
В случае машинного обучения (Machine Learning), нормализация – это процедура предобработки входной информации (обучающих, тестовых и валидационных выборок, а также реальных данных), при которой значения признаков во входном векторе приводятся к некоторому заданному диапазону, например, или .
Следует отличать понятия нормализации, нормировки и нормирования.
Нормировка – это корректировка значений в соответствии с некоторыми функциями преобразования, с целью сделать их более удобными для сравнения. Например, разделив набор измерений о росте людей в дюймах на 2.54, мы получим значение роста в метрической системе.
Нормировка данных требуется, когда несовместимость единиц измерений переменных может отразиться на результатах и рекомендуется, когда итоговые отчеты могут быть улучшены, если выразить результаты в определенных понятных/совместимых единицах. Например, время реакции, записанное в миллисекундах, легче интерпретировать, чем число тактов процессора, в которых были получены данные эксперимента .
Нормирование – это процесс установления предельно допустимых или оптимальных нормативных значений в прикладных сферах деятельности, например, нормирование труда. Как правило, нормы разрабатываются по результатам исследовательских, проектных или научных работ, а также на основе экспертных оценок .

Нормализация, нормировка и нормирование – это разные понятия
Нормализация и стандартизация — методы шкалирования данных
Нормализация (normalization) и стандартизация (standardization) являются методами изменения диапазонов значений – шкалирования. Шкалирование особенно полезно в машинном обучении (Machine Learning), поскольку разные атрибуты могут измеряться в разных диапазонах, или значения одного атрибута варьируются слишком сильно. Например, один атрибут имеет диапазон от 0 до 1, а второй — от 1 до 1000. Для задачи регрессии второй атрибут оказывал бы большое влияние на обучение, хотя не факт, что он является более важным, чем первый. Нормализация и стандартизация отличаются своими подходами:
-
Нормализация подразумевает изменение диапазонов в данных без изменения формы распределения,
-
Стандартизация изменяет форму распределения данных (приводится к нормальному распределению).
Обычно достаточно нормализовать данные. Например, в глубоком обучении (Deep Learning) требуется перевести цвета изображений RGB из диапазона 0-255 к диапазону 0-1. А вот стандартизацию стоит применять при использование алгоритмов, которые основываются на измерении расстояний, например, k ближайших соседей или метод опорных векторов (SVM).
Первая нормальная форма[править]
| Определение: |
Отношение находится в первой нормальной форме (1НФ) тогда и только тогда, когда
|
Первая нормальная форма эквивилентна отношению в строгом смысле этого слова. Каждый из данных критериев отвечает за запрет конструкций определенного вида.
Запрещенные конструкцииправить
Повторяющиеся группыправить
| CourseId | Lecturer | Phone (1) | Phone (2) |
|---|---|---|---|
| 1 | Корнеев Г. А. | 111-11-11 | |
| 2 | Киракозов А. Х. | 222-22-22 | 333-33-33 |
| 3 | Кудряшов Б. Д. | 444-44-44 | 555-55-55 |
| 4 | Сегаль А. С. | 666-66-66 |
В отношениях такого вида сложно обеспечивать консистентность данных. Рассмотрим пример выше. Первая возникающая проблема заключается в том, что при появлении преподавателя с более, чем двумя телефонами, придется изменять целиком структуру отношения. Вторая проблема – на выполнение запроса «проверить, что никакие два преподавателя не имеют одинаковый телефон» и других запросов, аналогичных данному, потребуется экспоненциальное от количества полей с данными о телефонах время.
Неатомарные атрибутыправить
| CourseId | Lecturer | Phones |
|---|---|---|
| 1 | Корнеев Г. А. | 111-11-11 |
| 2 | Киракозов А. Х. | 222-22-22 |
| 333-33-33 | ||
| 3 | Кудряшов Б. Д. | 444-44-44 |
| 555-55-55 | ||
| 4 | Сегаль А. С. | 666-66-66 |
Потенциальным решением проблемы повторяющихся групп является группировка атрибутов по смыслу. На примере показано, как несколько телефонов из прошлого отношения были сгруппированы в единый атрибут, что позволяет не изменять структуру отношения в зависимости от максимального количества телефонов у одного человека. Однако проблема большого времени работы проверки корректности данных все еще остается.
Отсутствие ключаправить
Отношение без ключа формально не является отношением. Отсутствие ключа говорит о повторяющихся записях, а отношения рассматриваются как подмножества декартового произведения других множеств, что в явном виде запрещает повторы.
Приведение в 1НФправить
Для того, чтобы привести произвольное отношение в 1НФ, достаточно:
- Рассмотреть все наборы атрибутов, имеющих одинаковый смысл
- Для каждого фиксированного значения оставшихся атрибутов сделать по записи на каждое значение выбранных:
- рассмотрим повторяющиеся атрибуты
- рассмотрим оставшиеся атрибуты
- построим такое отношение на атрибутах , что
- Аналогичную процедуру повторить для всех неатомарных атрибутов
Отношение, использованое в примерах выше, после приведения в 1НФ будет выглядеть как
| CourseId | Lecturer | Phone |
|---|---|---|
| 1 | Корнеев Г. А. | 111-11-11 |
| 2 | Киракозов А. Х. | 222-22-22 |
| 2 | Киракозов А. Х. | 333-33-33 |
| 3 | Кудряшов Б. Д. | 444-44-44 |
| 3 | Кудряшов Б. Д. | 555-55-55 |
| 4 | Сегаль А. С. | 666-66-66 |
Аномалииправить
| Определение: |
Аномалия – эффект, возникающий при недостаточной нормализации БД или сложных зависимостях между данными, влекущий за собой проблемы
|
Переход в 1НФ не уменьшает выразительную способность «разрешенных» отношений, но при этом исправляет только самые простые аномалии, поэтому в отношениях в 1НФ, не приведенных хотя бы во 2НФ, могут возникать аномалии более сложного вида.
| Определение: |
| Аномалия вставки – зависимость возможности записать обладающие собственным независимым смыслом данные от наличия другой связанной информации. |
В рассмотренном выше примере невозможно записать информацию о телефоне конкретного преподавателя, если он не читает ни один курс (таким образом, возможность записать для конкретного зависит от наличия соответствующего , хотя напрямую они не зависят друг от друга).
| Определение: |
| Аномалия удаления – невозможность удалить часть данных, не удалив никакую связанную с ней информацию. |
В рассмотренном выше, опять же, примере невозможно удалить информацию о том, что конкретный преподаватель читает конкретный курс, не потеряв его номер телефона (как и в случае с аномалией вставки, возможность хранить зависит от существования соответствующего ).
| Определение: |
| Аномалия изменения – ситуация, в которой частичное изменение данных нарушает целостность базы данных. |
В рассмотренном примере если один преподаватель ведет один курс и имеет два телефона, при изменении в одной из соответствующих ему записей будет невозможно восстановить какой курс на самом деле ведет преподаватель (записи с разными , но одинаковыми и , должны всегда поддерживаться в таком же состоянии).
Нормализация данных: методы и формулы
Существует множество способов нормализации значений признаков, чтобы масштабировать их к единому диапазону и использовать в различных моделях машинного обучения. В зависимости от используемой функции, их можно разделить на 2 большие группы: линейные и нелинейные. При нелинейной нормализации в расчетных соотношениях используются функции логистической сигмоиды или гиперболического тангенса. В линейной нормализации изменение переменных осуществляется пропорционально, по линейному закону.
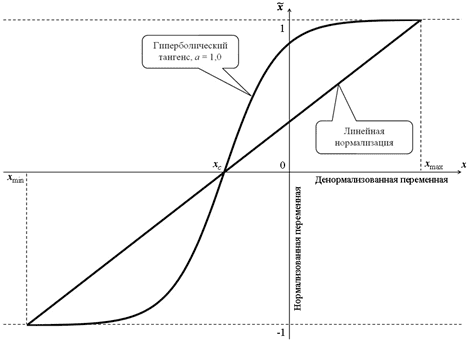
Графическая интерпретация линейной и нелинейной нормализации
На практике наиболее распространены следующие методы нормализации признаков :
- Минимакс – линейное преобразование данных в диапазоне , где минимальное и максимальное масштабируемые значения соответствуют 0 и 1 соответственно;
- Z-масштабирование данных на основе среднего значения и стандартного отклонения: деление разницы между переменной и средним значением на стандартное отклонение;
- десятичное масштабирование путем удаления десятичного разделителя значения переменной.
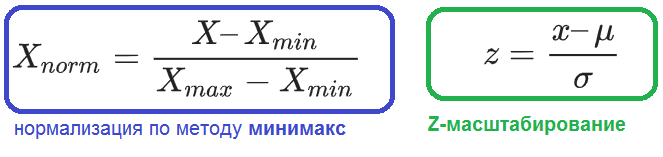
Формулы нормализации данных по методам минимакс и Z-масштабирование
На практике минимакс и Z-масштабирование имеют похожие области применимости и часто взаимозаменяемы. Однако, при вычислении расстояний между точками или векторами в большинстве случае используется Z-масштабирование. А минимакс полезен для визуализации, например, чтобы перенести признаки, кодирующие цвет пикселя, в диапазон .
Сначала поймите разницу между дисперсией, стандартным отклонением и среднеквадратичной ошибкой.
Дисперсия (дисперсия)
Измерьте степень дисперсии (отклонения) случайной величины или набора данных
Предположим, что используется математическое ожидание (среднее значение) набора случайных величин или статистических данных.
E
(
x
)
E(x)
E(x), Тогда его дисперсия выражается как данные и
E
(
x
)
E(x)
E(x)Сумма квадратов разностей
∑
x
−
E
(
x
)
2
\sum^2
∑x−E(x)2, А затем найти его ожидание (среднее), чтобы получить
D
(
x
)
=
∑
x
−
E
(
x
)
2
D(x)=\sum^2
D(x)=∑x−E(x)2
Зачем использовать стандартное отклонение
Согласно вышеизложенному, мы знаем, что дисперсия используется для измерения степени дисперсии (отклонения) случайной величины или набора данных. Формула для стандартного отклонения (также называемая среднеквадратической ошибкой):
σ
=
D
(
x
)
\sigma = \sqrt {D(x)}
σ=D(x), Дисперсия и стандартное отклонение имеют общее свойство: чем больше значение, тем более пологая кривая распределения, то есть более разбросанная. Поскольку данные являются случайными, предполагая, что такое же распределение основано на центральной предельной теореме, данные подчиняются распределению Гаусса (нормальному) (типичным примером является ошибка). Давайте посмотрим на область распределения. При использовании стандартного отклонения мы можем четко увидеть вероятность того, что данные принадлежат определенному значению. (Когда мы обрабатываем функции, мы можем отфильтровать выбросы на основе этого)
При использовании стандартного отклонения мы можем четко увидеть вероятность того, что данные принадлежат определенному значению. (Когда мы обрабатываем функции, мы можем отфильтровать выбросы на основе этого)
Цель нормализации
Нормализация — метод создания набора отношений с заданными свойствами на основе требований к данным, установленным в некоторой организации.
Нормализация часто выполняется в виде последовательности тестов для некоторого отношения с целью проверки его соответствия (или несоответствия) требованиям заданной нормальной формы.
Процесс нормализации является формальным методом, который позволяет идентифицировать отношения на основе их первичных ключей (или потенциальных ключей, как в случае НФБК) и функциональных зависимостей, существующих между их атрибутов. Проектировщики баз данных могут использовать нормализацию в виде наборов тестов, применяемых к отдельным отношениям с целью нормализации реляционной схемы до заданной конкретной формы, что позволит предотвратить возможное возникновение аномалий обновления.
Основная цель проектирования реляционной базы данных заключается в группировании атрибутов и отношения так, чтобы минимизировать избыточность данных и таким образом сократить объем памяти, необходимый для физического хранения отношений, представленных в виде таблиц.
Демормализация в базе данных: «звезда» и «снежинка»
Как можно понять из вышеприведённых примеров, основными целями нормализации являются:
- устранение избыточности при хранении данных, приводящей к увеличению размера БД;
- исключение необходимости модификации данных в связных таблицах для минимизации времени и операций, проводящихся в одной транзакции. Или, как выражаются специалисты, уменьшить толщину транзакции, потому что толстые транзакции мешают при многопользовательской работе взаимными блокировками и увеличением времени отклика системы. Речь об этом пойдёт в отдельной главе.
Но список заявленных целей касается приложений транзакционных.
В приложениях интерактивной аналитической обработки приоритет меняется: на первый план выходит время отклика системы, в ущерб которому данные могут быть избыточны.
1НФ — первая нормальная форма
Собственные типы данных СУБД считаются атомарными, исключение могут составлять массивы, в том числе символьные (текстовые) и байтовые. Следует также понимать, что атомарность может быть относительна выбранного взгляда со стороны предметной области и контекста. Например, телефонный номер в базе данных маркетинга содержится в одной колонке, тогда как у телефонных операторов он разделяется на номера АТС, шлейфов и т.п. Колонки для хранения комментариев, подлежащих последующей обработке приложением, также отчасти нарушают принцип атомарности.
По этой же причине не стоит рассматривать отдельно целую и дробные части действительного числа или даже пару «дата-время»: дальнейшая детализация не имеет смысла с точки зрения моделируемой области, где они атомарны.
Предположим, мы нарушили 1НФ и стали хранить фамилии, имена и отчества клиентов в одной колонке. Пока операторы вносили информацию, эта ошибка проектирования особенно не мешала, Однако, на следующем этапе понадобилась отчётность, в которой ФИО клиентов выводились бы в виде фамилии и инициалов. Оказалось, что некоторые записи вместо «Сидоров Петр Иванович» содержат «Петр Иванович Сидоров», в других отчества нет вовсе, в третьих фамилия двойная и не всегда записана через тире, в четвёртых после фамилий расставлены запятые… Эту проблему пришлось решать программированием совсем нетривиальной логики с элементами распознавания по словарю. Было потрачено много времени и средств, но в отчётности нет-нет да и проскакивали непонятные значения типа «Оглы П.Б.Б.».
Следует отметить, что при добавлении к этому учёту клиентов- иностранцев, проектировщиков логической схемы БД не спасла бы и более структурированная форма из трёх колонок для раздельного хранения фамилий, имён и отчеств. Потому что это проблема уровня концептуального проектирования и соответствующих моделей: необходим синтез не привязанной к модели данных структуры, способной вмещать в себя комбинации имён людей разных стран и культур.
«Ничего, кроме ключа»
Билл Кент дал приблизительное определение 3NF, данное Коддом, параллельно традиционному обязательству дать правдивые показания в суде: « неключевой должен содержать факт о ключе, о ключе в целом, и ничего, кроме ключа ». Распространенная вариация дополняет это определение клятвой «Помоги мне, Кодд ».
Требование наличия «ключа» гарантирует, что таблица находится в 1NF ; требование, чтобы неключевые атрибуты зависели от «всего ключа», обеспечивает 2NF ; дальнейшее требование, чтобы неключевые атрибуты зависели от «ничего, кроме ключа», обеспечивает 3NF. Хотя эта фраза является полезной мнемоникой, тот факт, что в ней упоминается только один ключ, означает, что она определяет некоторые необходимые, но не достаточные условия для удовлетворения 2-й и 3-й нормальных форм. И 2NF, и 3NF одинаково относятся ко всем ключам-кандидатам таблицы, а не только к одному ключу.
Крис Дэйт называет краткое изложение Кента «интуитивно привлекательной характеристикой» 3NF и отмечает, что с небольшой адаптацией оно может служить определением немного более сильной нормальной формы Бойса – Кодда : «Каждый атрибут должен представлять собой факт о ключе, в целом ключ, и ничего, кроме ключа «. Версия определения 3NF слабее, чем вариант BCNF Дейта, поскольку первая касается только обеспечения зависимости неключевых атрибутов от ключей. Основные атрибуты (которые являются ключами или их частями) вообще не должны быть функционально зависимыми; каждый из них представляет собой факт о ключе в смысле предоставления части или всего ключа. (Это правило применяется только к функционально зависимым атрибутам, так как его применение ко всем атрибутам неявно запрещает составные ключи-кандидаты, поскольку каждая часть любого такого ключа нарушает условие «весь ключ».)
Примером таблицы 2NF, которая не соответствует требованиям 3NF, является:
| Турнир | Год | Победитель | Дата рождения победителя |
|---|---|---|---|
| Индиана Invitational | 1998 г. | Аль Фредриксон | 21 июля 1975 г. |
| Кливленд Опен | 1999 г. | Боб Альбертсон | 28 сентября 1968 г. |
| Де-Мойн Мастерс | 1999 г. | Аль Фредриксон | 21 июля 1975 г. |
| Индиана Invitational | 1999 г. | Чип Мастерсон | 14 марта 1977 г. |
Поскольку каждая строка в таблице должна сообщать нам, кто выиграл конкретный турнир в конкретный год, составной ключ {Tournament, Year} представляет собой минимальный набор атрибутов, гарантирующих уникальную идентификацию строки. То есть {Tournament, Year} — это кандидатный ключ для таблицы.
Нарушение 3NF происходит из-за того, что непростой атрибут (дата рождения Победителя) транзитивно зависит от ключа кандидата {Турнир, Год} через непервичный атрибут Победитель. Тот факт, что дата рождения Winner функционально зависит от Winner, делает таблицу уязвимой для логических несоответствий, поскольку ничто не мешает одному и тому же человеку отображаться с разными датами рождения в разных записях.
Чтобы выразить одни и те же факты, не нарушая 3НФ, необходимо разделить таблицу на две части:
|
|
В этих таблицах не могут возникнуть аномалии обновления, потому что, в отличие от ранее, Победитель теперь является кандидатом ключа во второй таблице, что позволяет использовать только одно значение Даты рождения для каждого Победителя.