Создание первичных ключей
Содержание:
- Ключи
- Тестирование
- Первичный и уникальный ключи
- Хорошая практика для первичных ключей в таблицах
- SQL PRIMARY KEY в ALTER TABLE
- Колоночные
- Достоинства реляционных баз
- Что такое первичный ключ
- Проектирование базы данных
- Внешний ключ
- Ключ-значение
- Достоинства документных баз
- ОСНОВНОЙ КЛЮЧ
- SQL FOREIGN KEY в CREATE TABLE
- Составной ключ (composite key)
Ключи
Последнее обновление: 02.07.2017
Ключи представляют способ идентификации строк в таблице. С помощью ключей мы также можем связывать строки между различными таблицами в отношения.
Суперключ
Superkey (суперключ) — комбинация атрибутов (столбцов), которые уникально идентифицируют каждую строку таблицы. Это могут быть и все столбцы, и
несколько и и один. При этом строки, которые содержат значения этих атрибутов, не должны повторяться.
Например, у нас есть сущность Student, которая представляет данные о пользователях и которая имеет следующие атрибуты:
-
FirstName (имя)
-
LastName (фамилия)
-
Year (год рождения)
-
Phone (номер телефона)
Какие атрибуты в данном случае могут составлять суперключ:
-
{FirstName, LastName, Year, Phone}
-
{FirstName, Year, Phone}
-
{LastName, Year, Phone}
-
{FirstName, Phone}
-
{LastName, Phone}
-
{Year, Phone}
-
{Phone}
Каждого студента уникально может идентифицировать телефонный номер, поэтому любые наборы, в которых встречается атрибут Phone, представляют суперключ.
А вот, к примеру, набор не является суперключом, так как у нас теоретически могут быть как минимум
два студента с одинаковыми именем, фамилией и годом рождения.
Потенциальный ключ
Candidate key (потенциальный ключ) — представляет собой минимальный суперключ отношения (таблицы), то есть набор атрибутов, который удовлетворяет ряду условий:
-
Неприводимость: он не может быть сокращен, он содержит минимально возможный набор атрибутов
-
Уникальность: он должен иметь уникальные значения вне зависимости от изменения строки
-
Наличие значения: он не должен иметь значения NULL, то есть он обязательно должен иметь значение.
Возьмем ранее выделенные суперключи и найдем среди них candidate key. Первый пять суперключей не соответствуют первому условию, так как все их можно сократить до суперключа {Phone}:
-
{FirstName, LastName, Year, Phone}
-
{FirstName, Year, Phone}
-
{LastName, Year, Phone}
-
{FirstName, Phone}
-
{LastName, Phone}
-
{Year, Phone}
Суперключ {Phone} соответствует первому и второму условию, так как он имеет уникальное значение (в данном случае все пользователи могут иметь только уникальные телефонные номера). Но соответствует ли он третьему условию?
В целом нет, так как теоретически студент может и не иметь телефона. В этом случае атрибут Phone будет иметь значение NULL, то есть значение
будет отсутствовать.
В то же время это может зависеть от ситуации. Если в какой-то систему номер телефона является неотъемлемым атрибутом, например, используется для регистрации и входа в систему, то его можно считать потенциальным ключом. Но
в данном случае мы рассматриваем общую ситуацию. И для понимания потенциального ключа необходимо отталкиваться от конкретной системы, которую описывает база данных.
И в таком случае суперключи таблицы не содержат потенциального ключа.
Первичный ключ
Первичный ключ (primary key) непосредственно применяется для идентификации строк в таблице. Он должен соответствовать следующим ограничениям:
-
Первичный ключ должен быть уникальным все время
-
Он должен постоянно присутствовать в таблице и иметь значение
-
Он не должен часто менять свое значение. В идеале он вообще не должен изменять значение.
Как правило, первичный ключ представляет один столбец таблицы, но также может быть составным и состоять из нескольких столбцов.
Если для таблицы можно выделить потенциальный ключ, то его можно использовать в качестве первичного ключа.
Если же потенциальные ключи отсутствуют, то для первичного ключа можно добавить к сущности специальный атрибут, который, как правило, называется, Id или
имеет форму Id (например, StudentId), либо может иметь другое название. И обычно данный атрибут принимает целочисленное значение, начиная с 1.
Если же у нас есть несколько потенциальных ключей, то те потенциальные ключи, которые не составляют первичный ключ, являются альтернативными ключами
(alternative key).
Например, возьмем представление пользователей на сайтах с двухфакторной авторизацией, где нам обязательно иметь электронный адрес, который нередко выступает в качестве
логина, и какой-нибудь номер телефона. В этом случае таблицу пользователей мы можем задать с помощью следующих атрибутов:
-
Name (имя пользователя)
-
Password (пароль)
-
Phone (телефонный номер)
НазадВперед
Тестирование
этой ссылке
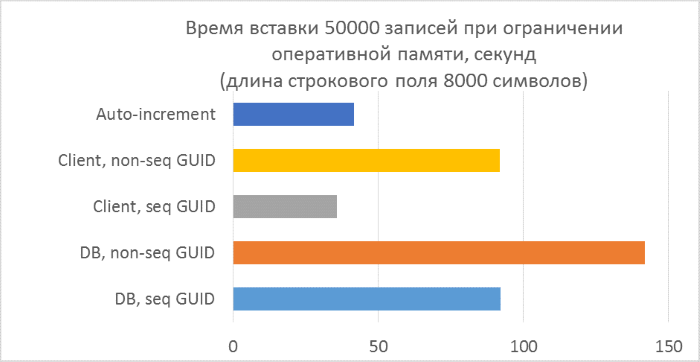
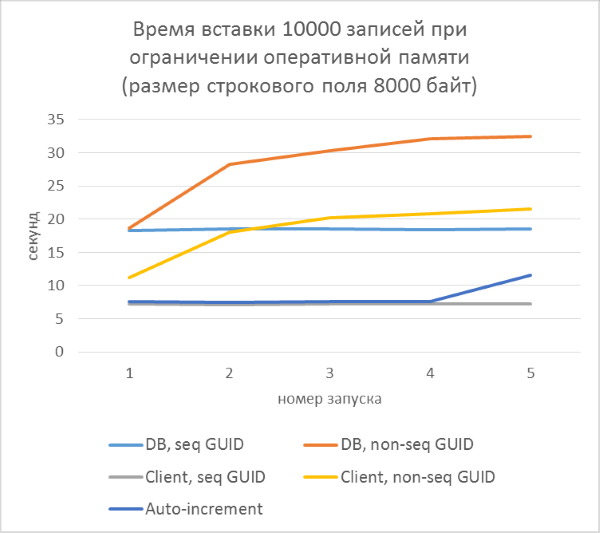
- Всего три серии тестов с длиной текстового поля в записи 80, 800 и 8000 байт соответственно (количество символов в тестовой программе будет в два раза меньше в каждом из случаев, так как один символ в NVARCHAR занимает два байта).
- В каждой из серий — по 5 запусков, каждый из которых добавляет по 10000 записей в каждую из таблиц. По результатам каждого из запусков можно будет проследить зависимость времени вставки от количества строк, уже находящихся в таблице.
- Перед началом каждой из серий таблицы полностью очищаются.
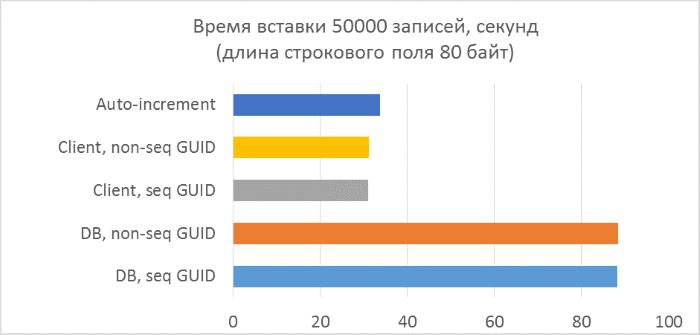
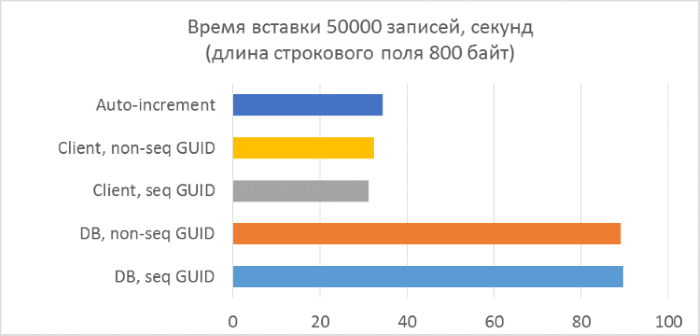
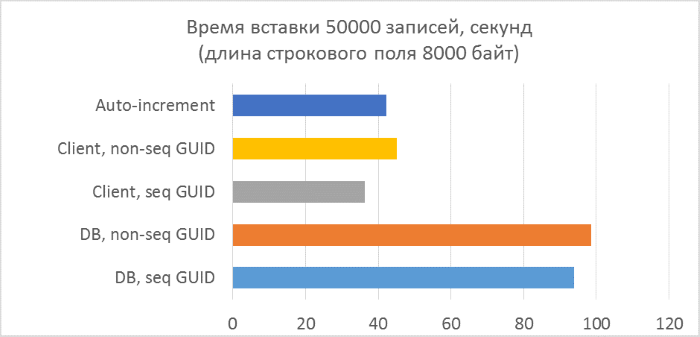
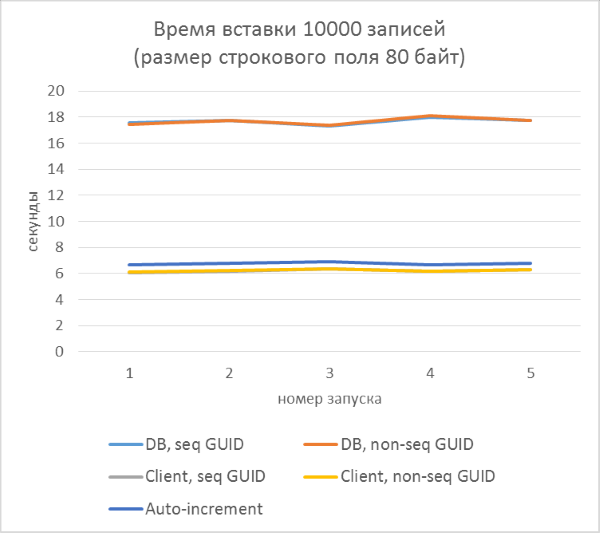
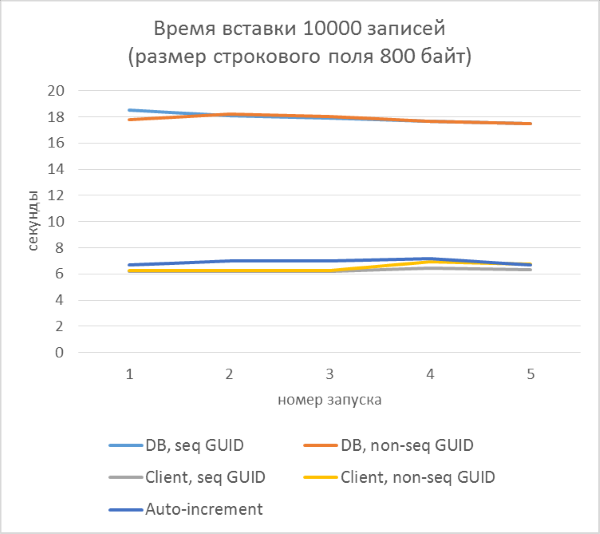
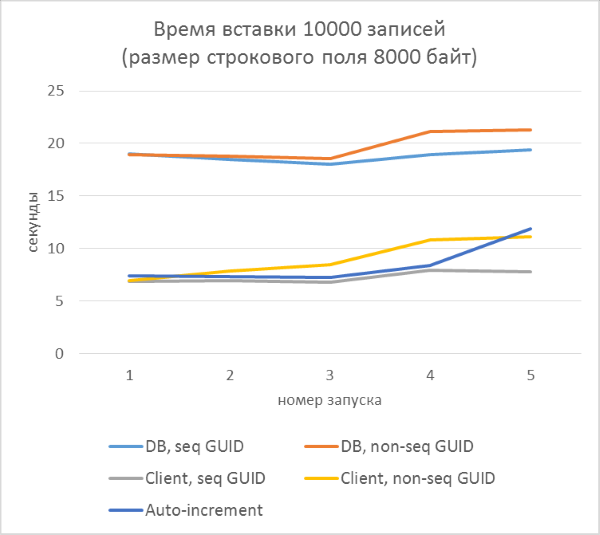
- Использование генерации GUID на стороне базы данных в разы медленнее, чем генерации на стороне клиента. Это связано с затратами на чтение только что добавленного идентификатора. Детали этой проблемы рассмотрены в конце статьи.
- Вставка записей с автоинкрементным ключом даже немного медленнее, чем с GUID-ом, присвоенным на клиенте.
- Разницы между последовательным и непоследовательным GUID практически не видно на небольших записях. На больших записях разница появляется с ростом количества строк в таблице, но она не выглядит существенной.
Первичный и уникальный ключи
Скрыть рекламу в статье
Первичный и уникальный ключи
Первичные ключи являются одним из основных видов ограничений в базе данных. Они применяются для однозначной идентификации записей в таблице. Допустим, мы храним в базе данных список людей. Вполне вероятно, что могут появиться два (или больше) человека с одинаковыми фамилией, именем и отчеством Как же гарантированно отличить одного человека от другого (конечно. речь идет о том, чтобы отличить одного человека от другого на основании информации, хранящейся в базе данных)?
В данном случае «человек» представлен одной записью в таблице, поэтому можно задаться более общим вопросом — как отличить одну запись в (любой) таблице от другой записи в этой же таблице. Для этого используются ограничения — первичные кпочи. Первичный ключ представляет собой одно или несколько полей в таблице, сочетание которых уникально для каждой записи. Для одной таблицы не существует повторяющихся значений первичного ключа.
Уникальные кчочи несут аналогичную нагрузку — они также служат для однозначной идентификации записей в таблице. Отличие первичных ключей от уникальных состоит в том, что первичный ключ может быть в таблице только один, а уникатьных ключей — несколько. Надо отметить, что и первичный и уникальный ключ могут быть использованы в качестве ссылочной основы для внешних ключей (см. далее).
Синтаксис создания первичного и уникального ключа на основе единственного поля следующий:
<pkukconstraint> = {PRIMARY KEY |
UNIQUE}
Примеры первичных и уникальных ключей:
CREATE TABLE pkuk(
pk NUMERIC(15,0) NOT NULL PRIMARY KEY, /*первичный ключ*/
ukl VARCHAR(SO) NOT NULL UNIQUE,/*уникальный ключ */
uk2 INTEGER NOT NULL UNIQUE /* еще уникальный ключ */);
Синтаксис создания первичного и уникального ключей на основе нескольких полей:
<pkuktconstraint> = {PRIMARY KEY |
UNIQUE) ( col )
Такой синтаксис позволяет создавать ключи на основе комбинации полей. Вот примеры создания первичных и уникальных ключей из нескольких полей:
CREATE TABLE pkuk2(
Number1 INTEGER NOT NULL,
Namel VARCHAR(SO) NOT NULL,
Kol INTEGER NOT NULL,
Stoim NUMERIC(15,4) NOT NULL,
CONSTRAINT pkt PRIMARY KEY (Numberl, Namel), /*первичный ключ pkt на
основе двух полей*/
CONSTRAINT uktl UNIQUE (kol, Stoim) ); /*уникальный ключ uktl на основе
двух полей*/
Обратите внимание, что все поля, входящие в состав первичного и уникального ключей, должны быть объявлены как NOT NULL, так как эти ключи не могутиметь неопределенного значения. Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу
Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу. Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
ALTER TABLE tablename
ADD {PRIMARY KEY | UNIQUE) ( col )
Давайте рассмотрим пример создания первичного и уникального ключа с помощью ALTER TABLE. Сначала создаем таблицу:
CREATE TABLE pkalter(
ID1 INTEGER NOT NULL,
ID2 INTEGER NOT NULL,
UID VARCHAR(24));
Затем добавляем ключи. Сначала первичный:
ALTER TABLE pkalter
ADD CONSTRAINT pkall PRIMARY KEY (idl, id2);
Затем уникальный ключ:
ALTER TABLE pkalter
ADD CONSTRAINT ukal UNIQUE (uid) ;
Важно отметить, что добавление (а также удаление) ограничений первичных и уникальных ключей к таблице может производить только владелец этой таблицы или системный администратор SYSDBA (подробнее о владельцах и пользователе SYSDBA см. главу «Безопасность в InterBase: пользователи, роли и права») (ч
4).
Оглавление книги
Хорошая практика для первичных ключей в таблицах
- Первичные ключи должны быть настолько маленькими, насколько это необходимо. Предпочитайте числовой тип, потому что числовые типы хранятся в гораздо более компактном формате, чем символьные форматы.
- Первичные ключи никогда не должны меняться.
- Не используйте номер паспорта, номер социального страхования или номер контракта сотрудника в качестве «первичного ключа», так как эти «первичные ключи» могут меняться в реальных ситуациях.
Пример:
Предположим, мы собираемся создать таблицу с именем ‘agent1’. Он содержит столбцы и типы данных, которые показаны ниже. Для каждой строки таблицы ‘agent1’ требуется идентифицировать каждого агента с помощью уникального кода, поскольку имена двух или более агентов в городе страны могут совпадать.
Так что не стоит создавать PRIMARY KEY для ‘agent_name’. ‘Agent_code’ может быть единственным и исключительным выбором для PRIMARY KEY для этой таблицы.
| Имя поля | Тип данных | Размер | Десятичные знаки | НОЛЬ | скованность |
|---|---|---|---|---|---|
| agent_code | голец | 6 | нет | ОСНОВНОЙ КЛЮЧ | |
| имя агента | голец | 40 | нет | ||
| рабочая область | голец | 35 | да | ||
| комиссия | десятичный | 10 | 2 | да | |
| номер телефона | голец | 17 | да |
При создании таблицы вы можете включить первичный ключ, используя ограничение первичного ключа на уровне столбца или ограничение на уровне таблицы. Вот два примера на упомянутой таблице:
Ограничение первичного ключа на уровне столбца:
Код SQL:
Ограничение первичного ключа на уровне таблицы:
Код SQL:
SQL PRIMARY KEY в ALTER TABLE
Чтобы создать ограничение первичного ключа для столбца «ID», когда таблица уже создана, используйте следующий SQL:
MySQL / SQL Server / Oracle / MS Access:
ALTER TABLE Persons
ADD PRIMARY KEY (ID);
Чтобы разрешить именование ограничения первичного ключа и определить ограничение первичного ключа для нескольких столбцов,
используйте следующий синтаксис SQL:
MySQL / SQL Server / Oracle / MS Access:
ALTER TABLE Persons
ADD CONSTRAINT PK_Person PRIMARY KEY (ID,LastName);
Примечание: Если вы используете инструкцию ALTER TABLE для добавления первичного ключа,
то столбец(ы) первичного ключа уже должен быть объявлен не содержащим нулевых значений (при первом создании таблицы).
Колоночные
Атомарная единица таких БД — колонка таблицы. Данные сохраняются столбец за столбцом, что делает колоночные запросы очень эффективными, и, поскольку данные в каждой колонке однородны, это позволяет лучше сжимать данные.
Использование
В тех случаях, когда удобно делать запросы к подмножеству столбцов (оно не обязательно должно быть одинаковым каждый раз!). Колоночные БД обрабатывают такие запросы очень быстро, так как читают только конкретные колонки (в то время как строчные БД должны читать строки полностью).
В науке о данных часто бывает, что каждая колонка представляет определенную характеристику. Как специалист по данным я часто тренирую свои модели на подмножествах характеристик и проверяю отношения между ними и оценками (корреляция, дисперсия, значимость). То же подходит и для логов— в них зачастую множество полей, но при каждом запросе используются только некоторые. Например:
Cassandra.
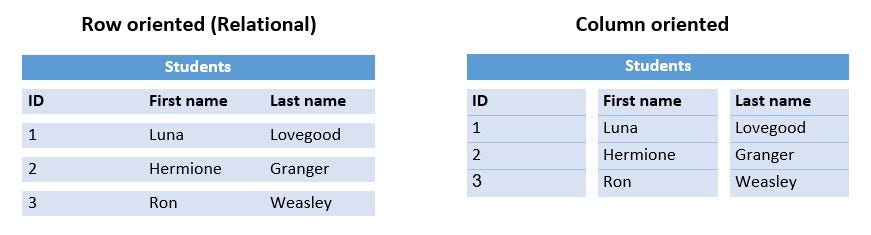
Строчная и колоночная базы данных
Достоинства реляционных баз
- Имеют простую структуру, которая подходит к большинству типов данных.
- Используют SQL, который широко распространен и по умолчанию поддерживает операции объединения.
- Позволяют быстро обновлять данные. Вся БД хранится на одном компьютере, а отношения между записями используются как указатели, то есть вы можете обновить одну запись — и все связанные с ней записи немедленно обновятся.
- Реляционные БД также поддерживают атомарные транзакции. Что это? Предположим, я хочу перевести X долларов от Алисы к Бобу. Я хочу осуществить 3 действия: уменьшить баланс Алисы на X, увеличить баланс Боба на X и задокументировать транзакцию. Я могу назначить эти действия атомарной единицей БД — или произойдут все действия, или ни одно. Это защищает от ошибок при сбоях.
Что такое первичный ключ
Столбец первичного ключа в таблице помогает идентифицировать каждую строку или запись в таблице. Содержит уникальные значения. Столбец первичного ключа не может иметь значения Null. Таблица может иметь один первичный ключ. В таблице Student, student_id является первичным ключом. В таблице Patient_Details, Patient_id является первичным ключом. Для первичного ключа необязательно иметь одно поле. Это также может быть комбинация нескольких полей. Когда первичный ключ состоит из нескольких полей, он называется составным ключом. Например, первичный ключ таблицы Student может быть комбинацией student_id и name.
Проектирование базы данных
Основой любой реляционной БД являются таблицы. Разработка таблиц является одним из наиболее сложных этапов в проектировании БД. Грамотно спроектированные таблицы являются основой для создания работоспособной и эффективной БД.
Понятие таблицы в Access полностью соответствует аналогичному понятию реляционной модели данных. Любая таблица реляционной БД состоит из строк (называемых также записями) и столбцов (называемых также полями).
Строки таблицы содержат сведения об однотипных объектах — документах, людях, предметах. На пересечении столбца и строки находится конкретное значение, характеризующее объект.
Можно сформулировать ряд основных требований, которым должны удовлетворять таблицы.
1. Информация в таблице не должна дублироваться, т.е. в таблице не должно существовать двух записей с полностью совпадающим набором значений ее полей.
2. На пересечении любого столбца и любой строки должно находиться одно
3. Не рекомендуется включать в таблицу данные, которые являются результатом вычислений.
4. Значения данных в одном и том же столбце должны принадлежать к одному и тому же типу, доступному для использования в данной СУБД.
5. Каждое поле должно иметь уникальное имя.
6. Каждая таблица должна иметь первичный ключ.
7. Таблицы БД должны быть связаны через внешние ключи.
Каждая таблица должна содержать поле (или набор из нескольких полей), значения в котором однозначно идентифицируют каждую запись в таблице. Такое поле (или набор полей) называется ключевым полем таблицы или первичным ключом. Первичный ключ любой таблицы обязан содержать уникальные непустые значения для каждой записи. Если для таблицы обозначены ключевые поля, то Access предотвращает дублирование или ввод пустых значений в ключевое поле.
В Access можно выделить три типа ключевых полей: простой ключ, составной ключ и поле счетчика.
Если поле содержит уникальные значения, такие как коды или инвентарные номера, то это поле можно определить как простой первичный ключ. Если в этом поле появятся повторяющиеся или пустые значения, Access выведет сообщение об ошибке.
В случаях, когда невозможно гарантировать уникальность значений ни одного из полей, можно создать ключ, состоящий из нескольких полей — составной первичный ключ. Для составного ключа существенным может оказаться порядок образующих ключ полей. Не рекомендуется определять ключ по полям Имена и Фамилии, поскольку нельзя исключить повторения этой пары значений для разных людей.
Составной ключ необходим для таблицы, используемой для связывания двух таблиц в отношении «многие — ко — многим» Обычно такой ключ состоит из ключевых полей связываемых таблиц.
Если для какой-либо таблицы не удалось определить простой первичный ключ или найти подходящий набор полей для составного ключа, можно добавить в таблицу поле счетчика и сделать его ключевым. При создании каждой новой записи Access генерирует уникальный номер записи, называемый счетчиком. Указание такого поля в качестве ключевого является наиболее простым способом создания ключевых полей.
Если до сохранения созданной таблицы ключевые поля не были определены, то при сохранении будет выдано предложение о создании системой ключевого поля. При ответе Да будет создано ключевое поле счетчика.
Сила реляционных баз данных, таких как БД Microsoft Access, заключается в том, что они могут быстро найти и связать данные из разных таблиц при помощи запросов, форм и отчетов. Таблицы реляционных БД связываются через одинаковые значения одноименных полей, содержащихся в связываемых таблицах. Такие поля называются внешним ключом для этих таблиц. Все таблицы БД Access должны быть связаны с помощью внешних ключей.
Внешний ключ
Внешние ключи — это основной механизм для организации связей между таблицами и поддержания целостности и непротиворечивости информации в базе данных.
Внешний ключ — это столбец или группа столбцов, ссылающиеся на столбец или группу столбцов другой (или этой же) таблицы. Таблица, на которую ссылается внешний ключ, называется родительской таблицей, а столбцы, на которые ссылается внешний ключ — родительским ключом. Родительский ключ должен быть первичным или уникальным ключом, значения же внешнего ключа могут повторяться хоть сколько раз. То есть с помощью внешних ключей поддерживаются связи «один ко многим«. Типы данных (а в некоторых СУБД и размерности) соответствующих столбцов внешнего и родительского ключа должны совпадать.
И самое главное. Все значения внешнего ключа должны совпадать с каким-либо из значений родительского ключа. (Заметим в скобках насчет совпадения / несовпадения: нюансы возникают, когда в значениях столбцов вторичного ключа встречается NULL. Давайте пока в эти нюансы вдаваться не будем). Появление значений внешнего ключа, для которых нет соответствующих значений родительского ключа, недопустимо. Вот тут-то мы плавно переходим к понятию ссылочной целостности.
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached
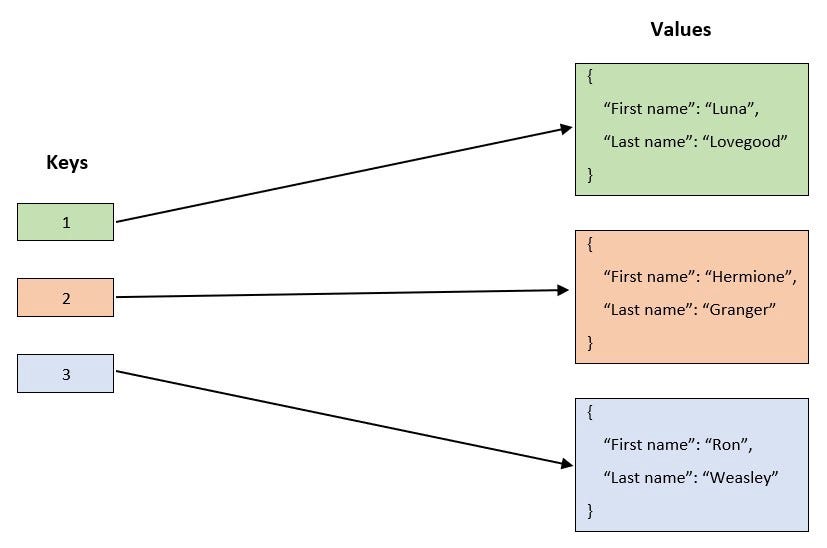
Достоинства документных баз
- Позволяют хранить объекты с разной структурой.
- Могут отображать почти все структуры данных, включая объекты на основе ООП, списки и словари, используя старый добрый JSON.
- Несмотря на то, что NoSQL не схематичны по своей природе, они часто поддерживают проверку схемы. Это значит, что вы можете сделать коллекцию со схемой. Эта схема не будет простой, как таблица: это будет JSON схема со специфическими полями.
- Запросы к NoSQL очень быстрые — каждая запись независима и, следовательно, время запроса не зависит от размера базы. По той же причине эта БД поддерживает параллельность.
- В NoSQL масштабирование БД осуществляется добавлением компьютеров и распределением данных между ними, этот метод называется горизонтальное масштабирование. Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
ОСНОВНОЙ КЛЮЧ
SQL PRIMARY KEY — это столбец в таблице, который должен содержать уникальное значение, которое можно использовать для уникальной идентификации каждой строки таблицы.
Тем не менее, SQL поддерживает первичные ключи напрямую с ограничением PRIMARY KEY.
Функционально это то же самое, что и ограничение UNIQUE, за исключением того, что для данной таблицы можно определить только один PRIMARY KEY. PRIMARY KEY не допускает значения NULL.
Первичный ключ используется для идентификации каждой строки идентично в таблице. Это может быть частью самой записи.
SQL PRIMARY KEY может состоять из одного или нескольких полей в таблице, и когда это происходит, они называются составным ключом.
Первичные ключи могут быть указаны во время CREATING TABLE или во время изменения структуры существующей таблицы с помощью инструкции ALTER TABLE.
Это ограничение является комбинацией ограничения NOT NULL и ограничения UNIQUE. Это ограничение гарантирует, что конкретный столбец или комбинация из двух или более столбцов для таблицы имеют уникальную идентификацию, которая помогает легче и быстрее найти конкретную запись в таблице.
Синтаксис:
CREATE TABLE <имя_таблицы> column1 data_type NOT NULL PRIMARY KEY, column2 data_type , ...);
Параметры:
| название | Описание |
|---|---|
| table_name | Имя таблицы, в которой хранятся данные. |
| column1, column2 | Наименование столбцов таблицы. |
| тип данных | Это char, varchar, целое число, десятичное число, дата и многое другое. |
| размер | Максимальная длина столбца таблицы. |
SQL FOREIGN KEY в CREATE TABLE
Следующий SQL создает внешний ключ в столбце «PersonID» при создании таблицы «Orders»:
MySQL:
CREATE TABLE Orders
(
OrderID int NOT NULL,
OrderNumber int NOT NULL,
PersonID int,
PRIMARY KEY (OrderID),
FOREIGN KEY (PersonID) REFERENCES Persons(PersonID)
);
SQL Server / Oracle / MS Access:
CREATE TABLE Orders
(
OrderID int NOT NULL PRIMARY KEY,
OrderNumber int NOT NULL,
PersonID int FOREIGN KEY REFERENCES Persons(PersonID)
);
Чтобы разрешить именование ограничения внешнего ключа и определить ограничение внешнего ключа для нескольких столбцов, используйте следующий синтаксис SQL:
MySQL / SQL Server / Oracle / MS Access:
CREATE TABLE Orders
(
OrderID int NOT NULL,
OrderNumber int NOT NULL,
PersonID int,
PRIMARY KEY (OrderID),
CONSTRAINT FK_PersonOrder FOREIGN KEY (PersonID)
REFERENCES Persons(PersonID)
);
Составной ключ (composite key)
Что касается составного ключа — это несколько первичных ключей в таблице. Таким образом, создав composite key, уникальность записи будет проверяться по полям, которые объединенные в этот ключ.
Бывают ситуации, когда при вставке в таблицу нужно проверять запись на уникальность сразу по нескольким полям. Вот для этого и придуман составной ключ. Для примера я создам простую таблицу с composite key, чтобы показать синтаксис:
create table test(field_1 int, field_2 text, field_3 bigint, primary key (field_1, field_3));

В примере выше два поля объединенные в составной ключ и в таблице не будет записей с этими одинаковыми полями.
Это все, что касается ключей в SQL. Это небольшое пособие — подготовка к статье связи sql где мы подробно рассмотрим как объединять таблицы, чтобы они составляли единую базу данных.