Пример проектирования простой базы данных в ms sql
Содержание:
- Проектирование баз данных
- Сетевая модель базы данных
- От прошлого к настоящему
- Слово, которое вовсе не имеет значения
- В чём преимущества
- Что такое базы данных (БД) и зачем они нужны
- Сетевые базы данных, структура сетевых данных
- Особенности реляционных баз
- Что такое SQL?
- Индексы и индексация таблиц
- Какие реляционные БД популярны в веб-разработке
- NoSQL как альтернатива традиционным БД
- Особенности реляционных данных
- Классификация баз данных пи типу хранимых данных
- Что такое СУБД и SQL
- Шаг 1. Подготовка данных
- Классификация баз данных по обращению к ним
- PostgreSQL
- Использование баз данных для повышения эффективности бизнеса и принятия решений
- Развитие базы данных
- О выборе NoSQL-баз данных
- Для чего нужны
- Достоинства документных баз
- Разные базы — разные правила
- Итоги
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Сетевая модель базы данных
Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
От прошлого к настоящему
Нет смысла охватывать историю баз данных, цепляясь за любое сходство, поэтому моментом появления баз данных будет не античное время, а 60-е годы 20 века. Именно тогда компьютеры стали эффективным инструментом для коммерческих компаний, а организация COBASYL (COnference on DAta SYstems Language), создавшая в 1959 году язык COBOL и впоследствии наделив его возможностями для управления БД, помогла им управлять резко возросшими потоками информации.
К концу 60-х появилась первая сетевая модель данных, возникло понятие СУБД, а в 1974 году компания IBM стала работать над языком для System R. Так на свет появился SEQUEL (Structured English QUEry Language). Однако позже, когда стало известно, что такое название используется британской авиастроительной компанией, было решено немного сократить до привычного SQL.
С увеличением доступности компьютеров стали появляться ориентированные на простых пользователей БД (Paradox, RBASE 5000, RIM, Dbase III), API (ODBC, Excel, Access) и средства разработки (VB, Oracle Developer, PowerBuilder). Само-собой, тенденция охватила и интернет, на сегодняшний день эффективное взаимодействие с БД – негласное требование к любому ресурсу с более-менее динамической информацией.
Если говорить о компаниях, то на рынке установилось троевластие: практически вся власть в области баз данных распределена между IBM, Microsoft и Oracle.
Слово, которое вовсе не имеет значения
Главная проблема в области информации — стремительно растущая динамика, к которой пользователь не только привык, он сам ее формирует и заинтересован в адекватности используемых им инструментов.
Базы данных — не самый мобильный и динамичный инструмент. Хочет того разработчик или нет, но он всегда в плену технологий. Он не может создать базу данных, которая не поддерживается существующими СУБД, а создавать собственный вариант в 99 % случаев нет возможности и реальной необходимости.

Между тем, есть и отчасти реализуется иной подход к созданию современных информационных систем. Абстракция, которую принесло с собой объектно-ориентированное программирование и облачные технологии, позволяет определить слово, которое поначалу вовсе не имеет значения, но приобретает его с течением времени.
Каждый занимается своим делом. Базы данных работают в штатном режиме, появляются новые, модернизируются старые. Веб-ресурсы берут на себя функции систем управления базами данных на пользовательском уровне. Поисковые системы ассоциируют ключевые слова и запросы с пространством доступной информации, собранной по их уникальным критериям.
В этих двух примерах и веб-ресурсы — окошки в базы данных и поисковики, в собранную по критериям информацию, представляют собой реально работающую идею динамического использования информации.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Представьте, что у вас есть экселька со списком клиентов. Это не база данных, это просто таблица. Чтобы прочитать или записать что-то в эту эксельку, вам нужно её открыть, сделать дело, сохранить.
Допустим, экселька с клиентами лежит на сетевом диске. Вы открыли её и ковыряетесь в данных, вносите изменения. Пока вы это делаете, ваш коллега тоже её открыл и тоже вносит изменения. Потом вы сохранились и закрыли эксельку. Экселька перезаписалась вашими данными. Но у вашего коллеги эти данные не отобразились, он-то открыл её раньше. Теперь, когда он сохранит свою эксельку, его данные перезапишутся поверх ваших, а ваши данные пропадут. Это полный ахтунг: вся ваша работа потеряна.
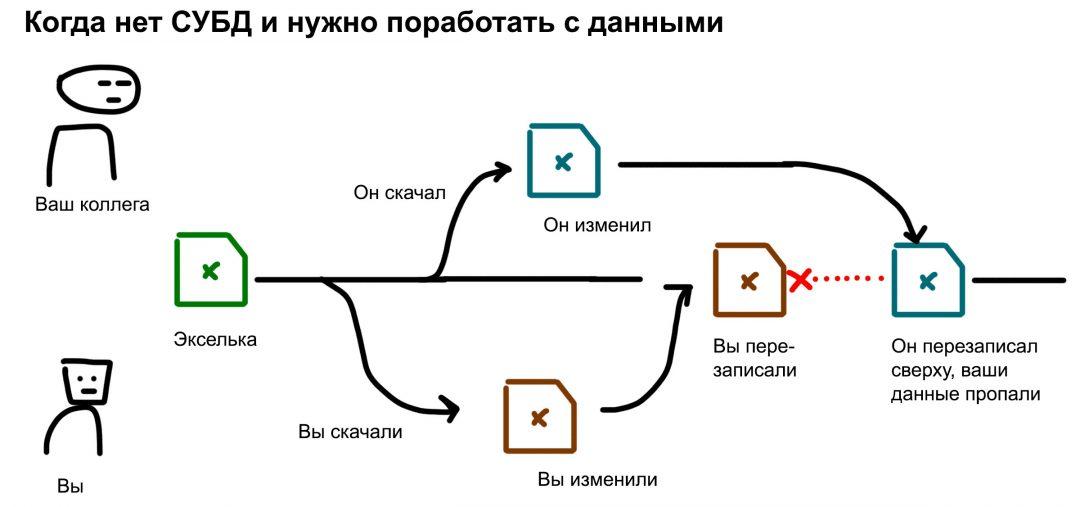
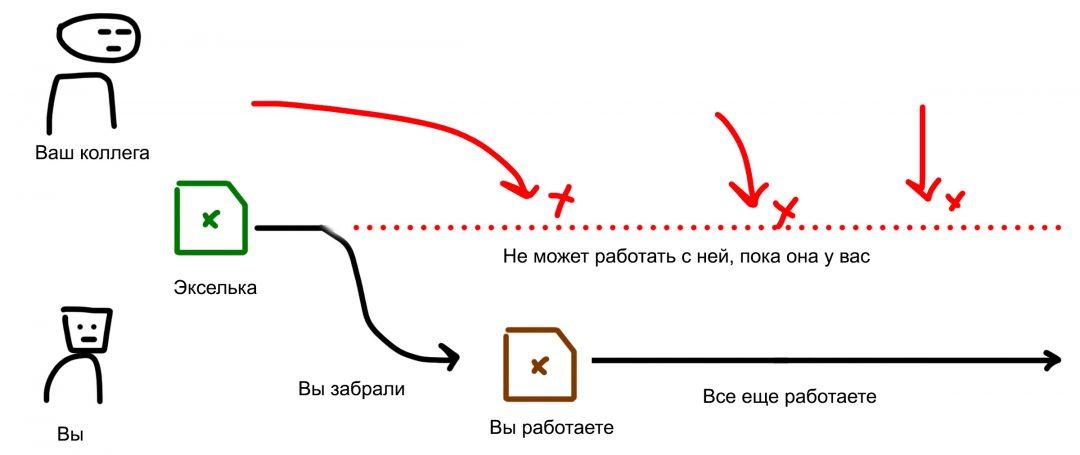
Или у вас в компании правило: экселька всегда на одной флешке, работаем только с неё. Сейчас флешка в вашем компьютере, вы с ней работаете. А вашему коллеге нужно с ней тоже поработать. Он говорит: «Дай». Вы ему «Отстань». Ну и слово за слово…
Но можно организовать своего рода СУБД. Один ответственный сотрудник назначается главным по эксельке. Она открыта на его компьютере, а вы ему говорите: «Петруха, добавь в клиента такого-то вот такие данные». «Петруха, а шо, когда дедлайн по поставке для этих ребят из Воронежа?», «Петруха, питерские отказались, поставь там отказ».
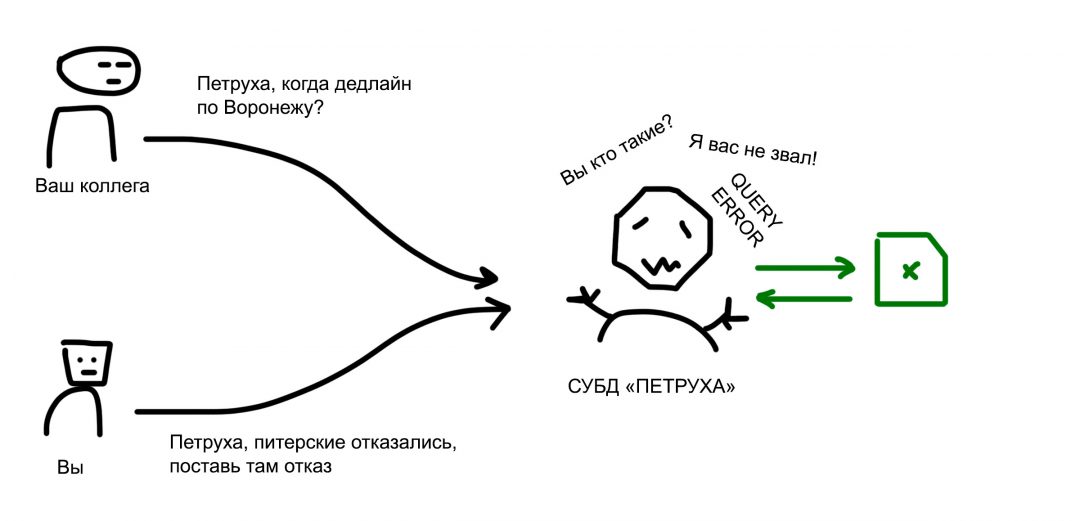
Петруха — ваша система управления базой данных. А экселька — это его база данных.
Понятно, что Петруха медленный и не всегда многозадачный, но хотя бы он избавляет от проблемы рассинхрона версий и потери данных.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Что такое базы данных (БД) и зачем они нужны
База данных (БД) — это программа, которая позволяет хранить и обрабатывать информацию в структурированном виде.
БД это отдельная независимая программа, которая не входит в состав языка программирования. В базе данных можно сохранять любую информацию, чтобы позже получать к ней доступ.
Пример использования
Базы данных нужны для хранения информации. Чтобы получить полное понимание необходимости использования БД в современном веб-программировании, необходимо ответить на три вопроса:
- Какую информацию и зачем мы храним?
- В каком виде и как надо хранить эту информацию?
- Как и каким способом можно получить доступ к этой информации?
Предположим, вы решили сделать сайт, где каждый пользователь может вести личный дневник наблюдения за погодой в своем городе.
Такой сайт должен иметь как минимум одну форму ввода со следующими полями: город, дата, температура, облачность, погодное явление, и так далее.
Каждый день наблюдатель записывает показания погоды в эту форму, чтобы когда-нибудь в будущем вернуться на сайт и посмотреть, какая была погода месяц или даже год назад.
Из этого примера следует, что программист каким-то образом должен сохранять данные из формы для дальнейшего использования.
Кроме обычного просмотра дневника погоды за месяц в виде таблицы, можно сделать и более сложный проект.
Например, чтобы электронный дневник чем-то качественно отличался от своего бумажного аналога, будет неплохо добавить туда возможности для простого анализа: показать какой день был самым холодным в ноябре или какой продолжительности была самая длинная серия пасмурных дней.
Получается, что данные надо не просто как-то хранить, но и иметь возможность их обрабатывать и анализировать.
Именно для этих целей и существуют базы данных.
Сетевые базы данных, структура сетевых данных
В каком-то смысле сетевые базы данных — это своеобразная модификация иерархических баз данных. Разница заключается в том, что в структуре иерархических данных у дочернего элемента бывает лишь один потомок (к каждому элементу, расположенному ниже, идёт лишь одна стрелочка с элемента, размещённого выше). А вот в сетевых базах данных у дочернего элемента бывает несколько предков (элементов, находящихся выше него). Для наглядного понимания структуры сетевых данных смотрите очередной рисунок:
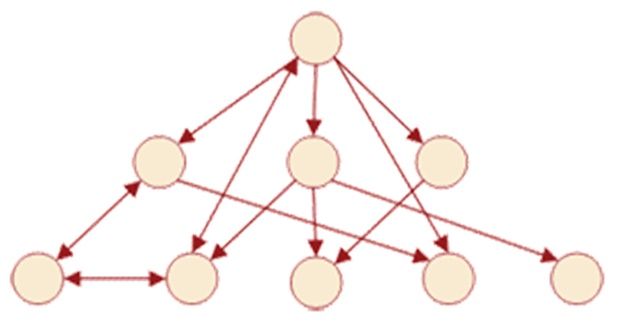
Следует отметить, что сетевые базы данных имеют примерно те же характеристики, что и иерархические данные. Однако в рамках этой статьи мы не будем углубляться в особенности управления сетевыми и иерархическими данными, а лучше подробнее поговорим о реляционных базах данных.
Особенности реляционных баз
Основные особенности реляционных баз можно сформулировать так:
- Все данные представлены в виде набора простых таблиц (двумерных массивов), разбитых на строки и столбцы, на пересечении которых расположены данные.
- У каждого столбца есть имя, уникальное в пределах таблицы, причем все значения в одном столбце — однородны, т.е. имеют один тип.
- Каждая строка имеет одно или несколько полей, набор значений в которых уникален в пределах таблицы. Этот набор называется первичным ключом (primary key) и служит для идентификации строки. Этот принцип не допускает, в частности, хранение в таблице совершенно одинаковых строк.
- Имя таблицы, имя столбца и первичный ключ однозначно определяют хранимый элемент данных.
- Строки в реляционной базе данных не упорядочены. Упорядочивание производится в момент формирования ответа на запрос.
- Запросы к базе данных возвращают результат в виде таблиц, которые также могут выступать как объект для новых запросов.
Чтобы такое изложение не воспринималось скучным и сложным, приведу поясняющий пример. Вот простая таблица — справочник стран. Назовем ее COUNTRIES.
| Справочник стран COUNTRIES | |
| ID | NAME |
| 1 | Россия |
| 2 | Франция |
| 3 | Марокко |
| 4 | Япония |
В таблице COUNTRIES всего два столбца:
- ID — код страны;
- NAME — ее название.
Столбец ID служит первичным ключом таблицы, а столбец NAME содержит ту полезную информацию, которую мы и будем стремиться извлекать запросами. Все данные столбца ID — целочисленны, столбца NAME — содержат текстовую информацию.
Что такое SQL?
SQL — это самый распространенный язык запросов к базам данных. Расшифровывается аббревиатура так: Structured Query Language — «язык структурированных запросов».
Он создавался затем, чтобы привести работу с различными типами баз данных (а их сейчас известно множество) к единому стандарту, сделать работу по управлению данными независимой ни от аппаратной, ни от программной части компьютера.
Последнее удалось не в полной мере, так как в SQL различных систем на какой-то стадии появились расхождения, поскольку разработка SQL-управляемых систем часто опережает формирование стандартов. Но в целом идею такой стандартизации можно считать реализованной.
Собственно, именно поэтому базы данных профессионально сделанных сайтов, как правило, реляционны и SQL-управляемы.
Индексы и индексация таблиц
Представьте себе, что ваш приятель загадал число между 1 и 1000 и просит вас угадать его за минимальное число попыток, сообщая лишь о том, в большую или меньшую сторону вы ошиблись. Как вы поступите? Очевидно, предложите при первой попытке версию 500 (то есть начнете с середины). Если он ответит: «меньше», — предложите 250. Если «больше» — 750. Так, разбивая интервалы пополам, вы уложитесь в 10 попыток (ведь 210 > 103). Если бы приятель загадал число в пределах миллиарда, то количество попыток уложилось бы в 30 (230 > 109).
Угадывая число, вы проводили поиск примерно так, как ведут его системы баз данных, использующие индексы. Понятное дело, их работа гораздо сложнее, но главная идея именно в этом — за небольшое число попыток найти нужное значение из миллиардов возможных. Поля, по которым вам часто придется делать в базе поиск, фильтрацию или связывание таблиц между собой, есть смысл проиндексировать, то есть создать специальный связанный с таблицей объект, содержащий информацию, необходимую для вышеописанного быстрого поиска.
Как это делается практически? Поясню на примерах. Допустим, вас часто просят отобрать информацию о товарах российского производства. Чтобы по колонке COUNTRY_ID таблицы GOODS фильтрация производилась быстрее, создадим по ней индекс с именем IDX_GOODS_COUNTRY:
Если в будущем вы передумаете использовать созданный индекс, то без труда его сможете удалить:
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.
NoSQL как альтернатива традиционным БД
Мир меняется. В ходе цифровой трансформации перед бизнесом встают новые задачи. Компании решают их с помощью новых баз данных. Во-первых, чтобы не перегружать имеющиеся, во-вторых, не для всех современных задач подходят классические реляционные СУБД.
И вот, в начале 2000-х появились нереляционные базы. Помимо решения новых задач, их разработчики сделали упор на исправление главных недостатков реляционных баз — проблем с гибкостью, низкой производительностью и масштабируемостью.
В NoSQL нет таких понятий, как строки, столбцы, таблицы и их соединения. Данные в нереляционных базах хранятся как объекты с произвольными атрибутами: это могут быть пары «ключ-значение», документы в формате JSON, графы и так далее.
Особенности реляционных данных
Главная особенность — все объекты хранятся в виде набора 2-мерных таблиц. Каждая таблица включает в себя набор столбцов, где указываются следующие параметры:
— название;
— тип данных (число, строка и т. д.).
Вторая важная особенность заключается в том, что число столбцов фиксировано. Это значит, что структура БД известна заранее, при этом количество рядов либо строк данных практически не ограничено. Грубо говоря, строки в реляционных БД — есть объекты, хранимые в базе.
По большему счёту, БД — это абстрактное понятие, а в случае с реляционной структурой таблица — есть не более чем удобный способ хранения информации. Причём набор таблиц превращается в базу данных тогда, когда он связан логически. А чтобы этим всем управлять, используют СУБД. Классический пример СУБД — система управления MySQL. Иными словами, СУБД MySQL — есть программное воплощение математических идей.
Классификация баз данных пи типу хранимых данных
Базы данных, объединяющие документы, сгруппированные (организованные) по разным свойствам, классифицируются, как документальные БД.
Под документом понимается текстовой документ или ссылка на него. Документальные БД разделили по типу документов на полнотекстовые, реферативные (рефераты) и библиографические
Это деление не так важно, как важен способ хранения информации. Здесь следующее разделение: базы данных хранящие исходный документ или хранящие ссылки, по которым можно обратиться к исходному документу
Фактографические БД объединяют данные по факту совершения события (дата выпуска товара, год рождения сотрудника).
Лексикографические БД объединяют словари, классификаторы, и т.л. документы.
Характерным примером, документальных баз данных могут послужить базы объединяющие документы по нормативным «формам». Вы встречались с такими документами, например в паспортом столе или отделе кадров, заполняя «бумажку» по форме № такой то.
Что такое СУБД и SQL
Именно с СУБД имеют дело потребители, то есть мы с вами. Современные СУБД позволяют обрабатывать не только тексты или графику, но и медиафайлы (аудио и видео файлы).
Любой программный продукт имеет свой язык, при помощи которого он управляется. Не исключение и СУБД. Один из основных языков для общения с СУБД является язык SQL (structured query language — язык структурированных запросов).
Стоит отметить, что по характеру использования СУБД делятся на однопользовательские (для одного пользователя – локального компьютера) и много пользовательские (для сетей).
Я уверен вы не думаете, что существует одна универсальная СУБД. И правильно, их десятки. В рамках этого раздела мы ограничим себя работой с бесплатной и самой распространенной СУБД MySQL.
СУБД MySQL
СУБД MySQL работает только с реляционными базами данных. Реляционные базы данных наиболее просты для первичного изучения. Кроме этого они используются на всех хостингах и серверах для массового пользования.
Осталось дать понятие реляционная база данных. Это простые таблицы, в которых есть информационные строки и столбцы. Пересечение строки и столбца называют ячейкой. Вся база данных состоит из нескольких или многих таблиц, причем, все таблицы между собой взаимодействуют.
Шаг 1. Подготовка данных
Для того чтобы нам было с чем работать, я набрал в твиттере запрос “#databases” и сформировал таблицу из 10 записей:
Таблица 1
| full_name | username | text | created_at | following_username |
|---|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 | Scootmedia, MetiersInternet |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 | klout, zillow |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 | DayJobDoc, byosko |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 | CindyCrawford, Arjantim |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 | MichaelDell, Yahoo |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 | MichaelDell, Yahoo |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 | RealSkipBayless, stephenasmith |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 | RealSkipBayless, stephenasmith |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 | dellock6, rohitkilam |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 | drsql, steam_games |
В первую очередь, давайте разберёмся с колонками:
- full_name: имя пользователя
- username: логин в Twitter-е
- text: текст твита
- created_at: время создания твита
- following_username: список пользователей, разделённых запятыми, которые подписались на этот твитт. Для краткости я сократил этот список до 2 имён.
Это реальные данные. Если хотите, вы можете их найти и обновить.
Хорошо. Теперь все наши данные находятся в одном месте. Даёт ли это нам возможность легко осуществить поиск по ним? Не совсем. Данная таблица далека от идеала. Во-первых, в некоторых столбцах у нас есть повторяющиеся записи: к примеру, в х “username” и “following_username”. Также колонка “following_username” нарушает правила реляционных моделей, т.к. её в ячейках присутствует более 1 значения (записи разделены запятыми).
К тому же у нас попадаются дубликаты и в строках.
Повторяющиеся данные действительно являются проблемой, т.к. они затрудняют процесс CRUD. К примеру, при поиске по данной таблице на обработку дубликатов будет уходить дополнительное время. К тому же, если пользователь обновит твитт, то нам нужно будет перезаписать все дубликаты.
Решение данной проблемы заключается в разделении Таблицы 1 на несколько таблиц. Давайте примемся за решение первой проблемы, а именно — устранение дубликатов в столбцах.
Классификация баз данных по обращению к ним
Базы данных индивидуального пользования классифицируют, как персональные или локальные базы данных.
Интегрированные иначе централизованные базы данный предоставляют коллективный доступ к данным. Такой доступ может быть как многопользовательский (сразу все), так и параллельный (независимый).
Распределительные базы данных аналогичны интегрированным, но могут быть физически разнесены на разные машины, и при этом логически считаться единым целым.
Перечисленные выше классификации не особо интересны пользователям. Для пользователя интересна классификация по способу организации данных и по типу используемой модели.
PostgreSQL
PostgreSQL является еще одним выдающимся решением с открытым исходным кодом, работающим во всех основных операционных системах, включая Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) и Windows. PostgreSQL полностью отвечает принципам ACID (атомарность, согласованность, изолированность, устойчивость).
Достоинства
- Возможность создания пользовательских типов данных и методов запросов;
- Среда разработки баз данных выполняет хранимые процедуры более чем на десятке языков программирования: Java, Perl, Python, Ruby, Tcl, C/C ++ и собственный PL/pgSQL;
- GiST (система обобщенного поиска): объединяет различные алгоритмы сортировки и поиска: B-дерево, B+-дерево, R-дерево, деревья частичных сумм и ранжированные B+ -деревья;
- Возможность создания для большего параллелизма без изменения кода Postgres, например, CitusDB.
Недостатки
- Система MVCC требует регулярной «чистки»: проблемы в средах с высокой скоростью транзакций;
- Разработка осуществляется обширным сообществом: слишком много усилий для улучшений.
Использование баз данных для повышения эффективности бизнеса и принятия решений
Благодаря массивному сбору данных из Интернета вещей, меняющему жизнь и промышленность во всем мире, сегодня предприятия имеют доступ к большему количеству данных, чем когда-либо прежде. Дальновидные организации теперь могут использовать базы данных, чтобы выйти за рамки простого хранения данных и транзакций для анализа огромных объемов данных из нескольких систем. Используя базы данных и другие инструменты для вычислений и бизнес-аналитики, организации теперь могут использовать собираемые данные для более эффективной работы, обеспечения более эффективного принятия решений и повышения гибкости и масштабируемости.
Автономные базы данных должны существенно расширить эти возможности. Поскольку самоуправляемые базы данных автоматизируют дорогостоящие и трудоемкие ручные процессы, они освобождают бизнес-пользователей, чтобы они могли более активно работать со своими данными. Имея прямой контроль над возможностью создания и использования баз данных, пользователи получают контроль и автономию, сохраняя при этом важные стандарты безопасности.
Развитие базы данных
Базы данных сильно изменились с момента их создания в начале 1960-х годов. Навигационные базы данных, такие как иерархическая база данных (которая основывалась на древовидной модели и допускала только отношения один-ко-многим) и сетевая база данных (более гибкая модель, допускающая множественные отношения), были исходными системами, используемыми для хранения и манипулировать данными. Несмотря на простоту, эти ранние системы были негибкими. В 1980-х годах стали популярными реляционные базы данных, а в 1990-х последовали объектно-ориентированные базы данных. Совсем недавно базы данных NoSQL появились как ответ на рост Интернета и потребность в более высокой скорости и обработке неструктурированных данных. Сегодня облачные базы данных и автономные базы данных открывают новые возможности, когда речь идет о том, как данные собираются, хранятся, управляются и используются.
О выборе NoSQL-баз данных
- Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
- Использование облачных вычислений и хранилищ. Облачные хранилища — отличное решение, но они требуют, чтобы данные можно было легко распределить между несколькими серверами для обеспечения масштабирования. Использование, для тестирования и разработки, локального оборудования, а затем перенос системы в облако, где она и работает — это именно то, для чего созданы NoSQL базы данных.
- Быстрая разработка. Если вы разрабатываете систему, используя agile-методы, применение реляционной БД способно замедлить работу. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
- Сохранить наши данные по запросу — чтобы вы могли открыть дверь, повесить куртку, закрыть дверь и больше не думать ни о куртке, ни о гардеробной.
- Изменить наши данные по запросу — чтобы можно было легко извлечь из гардеробной все дырявые носки и положить на их место целые.
- Найти эти данные по запросу — чтобы быстро найти приличный пиджак или парный носок.
- Не дать прочитать эти данные тем, кому не следует, а кому надо — дать. Например, младший брат может смотреть на ваши кроссовки, но не может их брать. А девушка (или парень) может положить свои вещи, но только на определённую полку.
- Поддерживать порядок и не дать захламиться — если вам было лень и вы просто кинули толстовку куда попало, чтобы гардеробная либо сама нашла, куда эту толстовку правильно положить, либо сказала: «Э БРАТ ЗАЧЕМ ЗАХЛАМЛЯЕШЬ ПОЛОЖИ НОРМАЛЬНО ДАВАЙ»
- Масштабироваться — чтобы вы могли просто вешать в гардеробную вещи и не думать об объёме полок.
- Не потерять данные — если квартира будет гореть, приличная гардеробная не должна даже нагреться. Или, если она всё-таки горит, чтобы где-то в защищённом подземном гараже была точная копия этой гардеробной со всеми актуальными вещами.
Достоинства документных баз
- Позволяют хранить объекты с разной структурой.
- Могут отображать почти все структуры данных, включая объекты на основе ООП, списки и словари, используя старый добрый JSON.
- Несмотря на то, что NoSQL не схематичны по своей природе, они часто поддерживают проверку схемы. Это значит, что вы можете сделать коллекцию со схемой. Эта схема не будет простой, как таблица: это будет JSON схема со специфическими полями.
- Запросы к NoSQL очень быстрые — каждая запись независима и, следовательно, время запроса не зависит от размера базы. По той же причине эта БД поддерживает параллельность.
- В NoSQL масштабирование БД осуществляется добавлением компьютеров и распределением данных между ними, этот метод называется горизонтальное масштабирование. Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
Разные базы — разные правила
Внутри каждой базы данных и её управляющей системы свои строгие правила:
- какие данные могут храниться: текст, цифры, фото, видео или всё вместе;
- какие свойства есть у этих данных: дата записи, кто записал, кто может прочитать;
- что делать, если с базой хотят работать одновременно несколько человек: разрешать только одному или пусть все вместе работают.
Рабочая ситуация: допустим, вы работаете в банке и открыли карточку клиента, чтобы поменять ему кредитный лимит. В этот же момент другой сотрудник из соседнего офиса тоже хочет поменять лимит этому же клиенту, но уже на другую сумму. Как база отреагирует на такое? Должна ли она разрешать второму сотруднику открывать карточку или её нужно заблокировать, пока первый не закончит? А если она разрешит открыть карточку, то что будет, если двое сотрудников напишут там разный лимит — какой из них сохранять в итоге? СУБД задаёт эти правила и следит за их выполнением.
Итоги
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.