Лучшие сервисы для подбора ключевых слов
Содержание:
- Как пользоваться парсером подсказок от Click.ru: пошаговая инструкция
- Почему нельзя собрать бесплатно и вручную
- Операторы в Яндекс.Вордстат. Уточняем данные по статистике
- Советы специалистам и предпринимателям, занимающимся продвижением самостоятельно
- Сбор поисковых подсказок Яндекса и Гугла
- Сетевые истории
- Согласно последней информации, удалять будут следующие поисковые подсказки:
- Какие типы подсказок бывают?
- Платные инструменты для составления семантического ядра:
- Парсеры поисковых систем#
- Как поисковик формирует подсказки
- Определение перспективных ключевых фраз
- Как пользоваться сервисом для парсинга аудитории Pepper.Ninja?
- Магадан
- Как осуществить наиболее эффективный сбор?
- Зачем они нужны пользователям
Как пользоваться парсером подсказок от Click.ru: пошаговая инструкция
1 Зарегистрируйтесь на Click.ru и перейдите на страницу парсера.
2 Добавьте запросы из эксель-файла или вставьте их списком.
 Этап загрузки запросов
Этап загрузки запросов
3 Выберите нужную поисковую систему и настройте региональность.
 Выбор поисковых систем и управление регионами
Выбор поисковых систем и управление регионами
4 Выберите способы сбора подсказок.По умолчанию подсказки собираются только по заданным запросам. Если нужно собрать семантическое ядро по максимуму, то следует включить дополнительные опции: перебор и/или и/или .
 Просто подсказки по запросу
Просто подсказки по запросу А это подсказки по запросу + первая буква алфавита. Большая разница
А это подсказки по запросу + первая буква алфавита. Большая разница
5 Укажите глубину сбора.
Если оставить первую глубину, то будут собраны подсказки по умолчанию + подсказки, полученные в результате автоподстановок и/или и/или . Если же включить вторую глубину, то вы также получите дополнительные подсказки, собранные по всем словам и фразам первого результата.
 Процесс выбора способа и глубины сбора подсказок
Процесс выбора способа и глубины сбора подсказок
6. Запустите проверку.По окончании парсинга отчет можно будет изучить в интерфейсе Click.ru или же скачать на компьютер в эксель-формате.
Стоимость сбора подсказок зависит от количества ТЗ (внутренняя валюта Click.ru). 1 ТЗ — это сбор подсказок в 1 поисковой системе в 1 регионе по 1 фразе. Чтобы сначала попробовать инструмент, платить ничего не надо, так как при регистрации в Click.ru в подарок дается 50 ТЗ.
Почему нельзя собрать бесплатно и вручную
Теоретически собрать подсказки можно и бесплатно, и вручную, но зачем так мучиться?
Если из Яндекс.Вордстата запросы можно вносить в эксель по принципу «копировать-вставить», то с поисковыми подсказками так не получится. При попытке выделить что-то из списка выделяется набранный вами запрос. Остается только вручную переписывать все запросы, а это просто адский труд. Особенно, когда нужны сотни и тысячи ключевых слов и фраз.
Сбор ключевых слов и фраз происходит «в облаке», не нужно ничего скачивать и устанавливать. Во время парсинга даже можно закрыть браузер, все идет в фоновом режиме. Капчи и фейковые аккаунты тоже не нужны.
Главное преимущество инструмента от Click.ru перед конкурентами – стоимость сбора подсказок в 3–5 раз дешевле, чем у конкурентов.
Операторы в Яндекс.Вордстат. Уточняем данные по статистике
Вордстат собирает статистику по широкому спектру запросов. В выдачу попадает много нерелевантных ключей, а также тех, которые не несут нужного смысла. Для более точного поиска и отсеивания ненужных запросов используют операторы — это специальные знаки, уточняющие параметры подбора слов.
Оператор «»
Кавычки позволяют собирать статистику только по указанному слову или фразе. Например, если ввести уже упомянутый запрос «спальный мешок» — получим статистику 57 164 показов в месяц. Но в это число включены вариации запроса с дополнительными словами: «спальный мешок купить», «спальный мешок цена» и т.д.
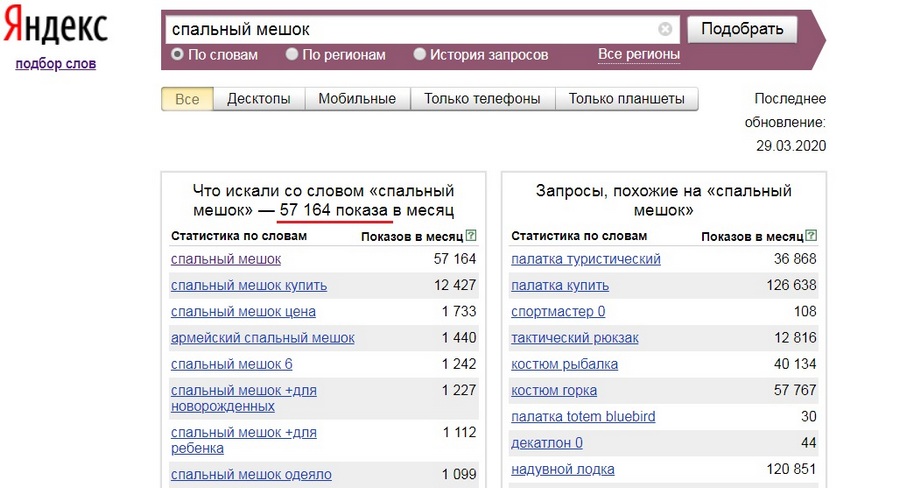
Если они вам не нужны, берем запрос в кавычки и получаем статистику только по исходной формулировке.
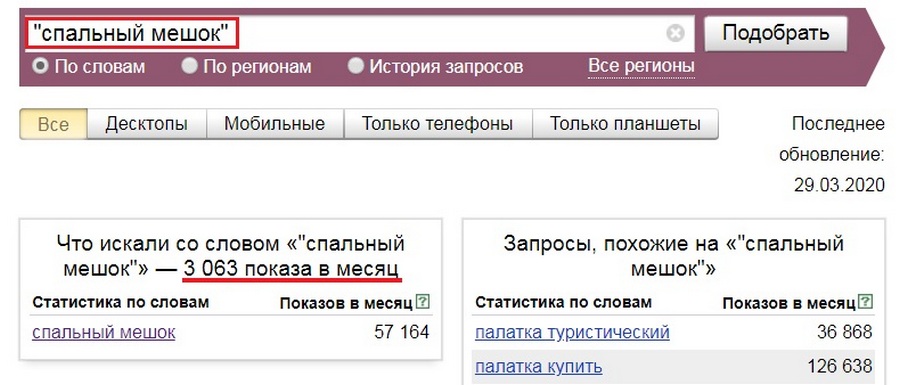
Просто фразу «спальный мешок» в поиск вбивают куда реже — Вордстат выдает 3 063 показа в месяц.
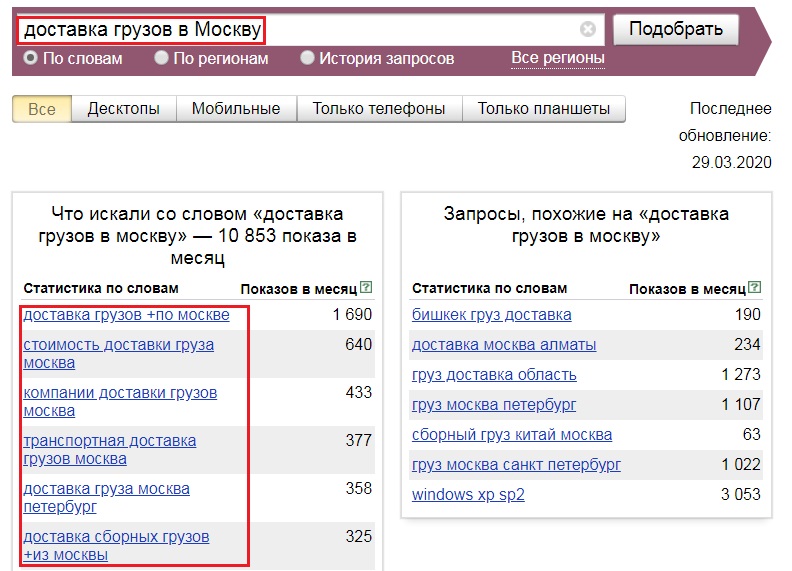
Оператор !Данный оператор фиксирует форму слова в точном вхождении: без изменения падежа, числа, времени. Например, нам нужно узнать частотность запроса «доставка грузов в Москву» строго в таком вхождении, т.к. другие словоформы изменят смысл фразы.
Вот что Вордстат выдает без оператора:
Используя восклицательный знак, мы получим статистику с точным вхождением слов.
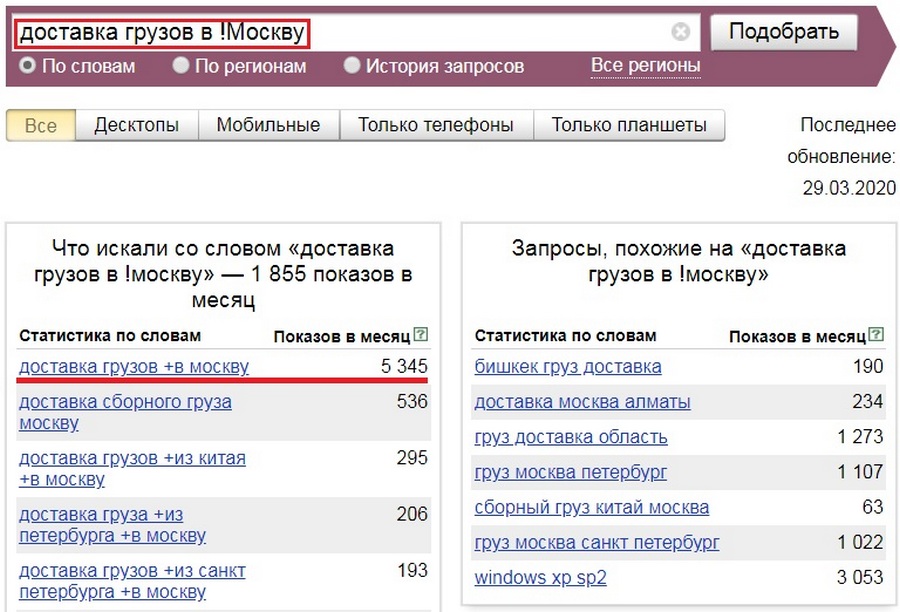
Этот оператор очень полезен при поиске анкоров для ссылок.
Оператор +
Вордстат по умолчанию игнорирует предлоги и союзы, считая их стоп-словами. В некоторых запросах эти части речи имеют принципиальное значение, т.к. без них смысл фразы становится совершенно иным. Оператор + дает указание учитывать все отмеченные предлоги и союзы.
Сравните результаты выдачи с ним и без него:
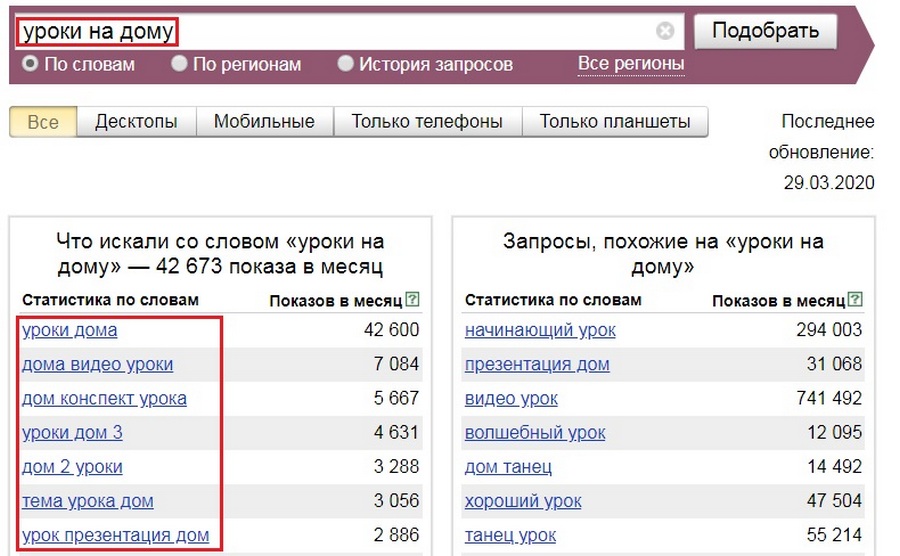
Без учета предлога Вордстат предлагает нерелевантные запросы.
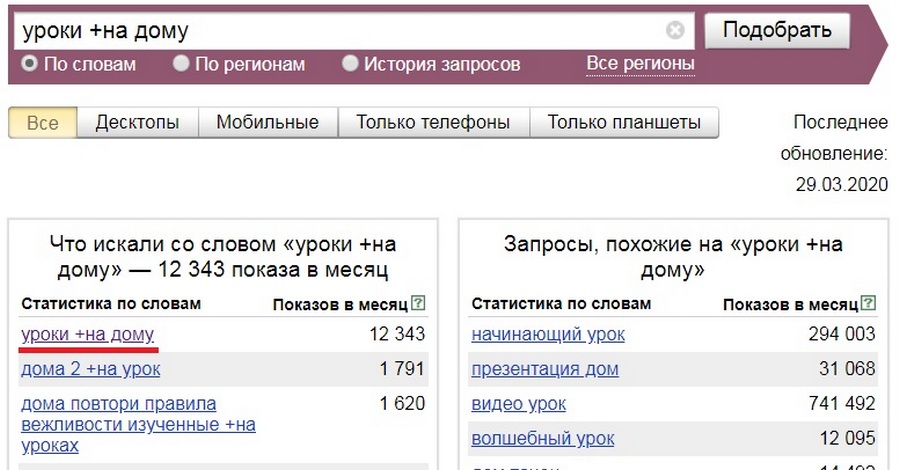
Задав команду учитывать предлог — получаем статистику по нужному запросу.
Оператор —
Логика работы этого оператора обратная: он убирает из выборки нежелательные слова.
Например, если компания изготавливает только шкафы, то все ключи, связанные с мягкой мебелью или «своими руками» будут засорять статистику. Их убирают при помощи знака минус.
Оператор (|)
Оператор перебора используют для проверки серии похожих запросов.
Например, у нас есть три запроса:
- купить беговые лыжи;
- купить лыжи для конькового хода;
- купить охотничьи лыжи.
Мы можем вводить каждый запрос отдельно, но куда удобнее все сделать в один заход. Для этого группируем слова следующим образом: «купить (беговые|для конькового хода|охотничьи) лыжи».
Таким образом, используя оператор (|) можно не вводить один за другим похожие запросы, а сразу получать сводную статистику. Это очень помогает при сборе семантического ядра, когда нужно собрать частотность по большому количеству похожих запросов.
Оператор
Данный оператор фиксирует порядок слов в запросе.
Например: билет из . Благодаря квадратным скобкам Вордстат не будет предлагать ключи, связанные с направлением Москва-Новосибирск.
Другой пример: запрос бронхита. Оператор фиксирует порядок слов и в выдаче не будет запросов осложнения при лечении бронхита, которые придают фразе совершенной иной смысл.
Совет! Для еще более быстрого и точного сбора запросов некоторые операторы сочетают друг с другом. Например, операторы «» и ! работают в комбинации. При этом команды «» и (|) не сочетаются.
Советы специалистам и предпринимателям, занимающимся продвижением самостоятельно
1 Лучше не собирать подсказки одновременно в трех системах, ведь у каждой из них свои алгоритмы. То, что подойдет для продвижения в Яндексе, может не подойти для оптимизации видео YouTube.
2 Выбирайте регионы с учетом местоположения целевой аудитории и географии продвижения. Для Яндекса и Google доступны все регионы РФ и соседних стран, для YouTube – только страны.
3 Если нужно просто быстро оценить семантику по заданному набору фраз, дополнительные опции и расширения не нужны.
4 Подсказки отражают реальные запросы пользователей, но не всегда: в отчете могут встречаться автоматически сформированные подсказки (их еще называют автокомплиты). Да и не все реальные подсказки на самом деле популярные, поэтому лучше перепроверять их частотность с помощью парсера Вордстата.
 Пример бессмысленного автоматически сформированного запроса, так никто не ищет
Пример бессмысленного автоматически сформированного запроса, так никто не ищет
Главное при этом помнить, что Вордстат показывает статистику за последние 30 дней. Если запрос сезонный, лучше еще заглянуть в «Историю запросов».
5 Запросы, на которые поисковик дает ответы в самих подсказках, вряд ли целесообразно использовать для продвижения. Маловероятно, что по таким запросам пользователь пойдет смотреть результаты.
 Примеры ответов на запрос прямо в подсказках
Примеры ответов на запрос прямо в подсказках
Сбор поисковых подсказок Яндекса и Гугла
Сейчас в Интернете есть сервисы и программы, которые осуществляют сбор поисковых подсказок Яндекса и Гугла. Далее, нами будут рассмотрены такие сервисы и программа:
- Пиксель Тулс;
- Раш Аналитикс;
- Программа Кей Коллектор.
Парсер поисковых подсказок выглядит в Яндексе таким образом (Скрин 1).

Например, мы введём поисковый запрос – «заработок в Интернете». И если нажать на клавиатуре кнопку «Пробел» можно получить сразу ещё 9 таких аналогичных подсказок. Тоже самое дело обстоит и с Гуглом (Скрин 2).

Правда он больше подходит для продвижения иностранных ресурсов, чем сайтов, блогов русскоязычного Интернета. Веб-мастера в основном «упираются» на Яндекс, но о Гугле не забывают.
Сетевые истории
Мы уже поняли, что скорость ввода складывается из качества данных и качества представления. Однако оказалось, что есть ещё один аспект проблемы – сетевой.
Исторически источник поисковых подсказок жил на домене , к которому поисковая вёрстка осуществляла асинхронные запросы в процессе пользовательского ввода.
К концу лета 2016 года стало понятно, что эта схема устарела. Многие сервисы уже жили за «единым доменом» : например, картинки , видео и так далее. Зачем? Чтобы экономить сетевые взаимодействия. У нас один единый балансер для всех сервисов, доступных на домене . Это означает, что, не покидая этого домена, пользователю достаточно лишь однажды установить сетевое соединение. В случае с саджестом это было не так: для похода за саджестом с домена требовалось установить новое сетевое соединение, что на 2G-интернете иногда стоило нескольких секунд ожидания.
Другим интересным моментом является поведение блокировщиков рекламы. Оказалось, некоторые из них блокируют кросс-доменные запросы. В нашем случае это привело к тому, что у некоторых пользователей саджест на несколько дней оказался полностью нефункциональным!
Поэтому мы решили провести эксперимент, в котором саджест переносится за единый для сервисов Яндекса балансер.
Тут стоит отметить, чем саджест отличается от других сервисов. Дело в том, что каждый поисковый запрос требует приблизительно столько же запросов в саджестовый источник, сколько в нём символов. Поэтому неудивительно, что типиный RPS для саджестового источника на порядки превосходит RPS других сервисов, в т.ч. большого Поиска. 100k RPS – это норма, саджест является одним из самых высоконагруженных сервисов Яндекса, непосредственно взаимодействующих с пользователями (некоторые внутренние сервисы выдерживают миллионы RPS).
Для единого балансера это означает очень существенный рост нагрузки, так что для удовлетворения нужд поисковых подсказок пришлось значительно вложиться в железо, и мы не хотели этого делать без подтверждения гипотезы о пользе для пользователей.
В результате эксперимент оказался одним из самых успешных за всё время. Его крутизна проявлялась даже в том, что пользователи начинали чаще задавать запросы в поисковую систему, не говоря уже о росте используемости саджеста и скорости ввода на единицы процентов.
Согласно последней информации, удалять будут следующие поисковые подсказки:
Подсказки “взрослой” тематики, которые не относятся к медицинским, научным или образовательным темам;
Поисковик также будет удалять те подсказки, которые оправдывают, восхваляют или подстрекают к насилию или же оскорбляют жертв.
При этом в Google признают, что функционал подсказок явно не идеален, и иногда может выдаваться информация, которая нарушают установленные правила. Однако в компании пытаются в кратчайшие сроки удалять такие результаты, опираясь на жалобы и обращения пользователей.
В Google также поделились аналитикой по работе этого функционала. Так, согласно информации компании, подсказки ежедневно экономят пользователям «более 2 веков времени» и сокращают время ввода запроса не менее чем на четверть.
- https://tools.pixelplus.ru/news/podskazki-google
- https://chromeum.ru/faq/how-to-delete-searches-in-google-chrome
- https://internet-marketings.ru/poiskovye-podskazki-yandeksa-google-i-youtube-zachem-nuzhny-kak-sobirat-bystro-i-pravilno/
- https://texterra.ru/blog/poshagovaya-instruktsiya-kak-popast-v-blok-bystrykh-otvetov-google-ispolzuya-long-tail-zaprosy.html
- https://seofuck.ru/poiskovye-podskazki-v-google/
Какие типы подсказок бывают?
Это только кажется на первый взгляд, что все поисковые подсказки одинаковые. Если посмотреть на них более пристально, то окажется, что их можно разбить на типы, вот и «Пиксель Тулс» теперь может отделить по меньшей мере 6 видов:
Навигационная. Ссылка на сам результат есть в колдунщике. Продвигаться по такой фразе, как правило, смысла нет.
Новостная. Подсказка появилась недавно и, скорее всего, скоро пропадёт. Имеет смысл продвигаться по данному типу если у вас новостной / информационный проект.
Есть в подсказках. Обычный тип
Для большинства проектов (коммерческих) важно удостовериться, что запросы из продвигаемой вами семантики — относятся к этому типу.
Автосгенерированная. Фактически, такой подсказки нет, но она выдается Яндексом для придания пользователю уверенности
Как правило, это мусорные запросы и продвижение по ним нецелесообразно. Важно проверить семантику и убедиться, то таких запросов в ядре нет или что по ним хотя бы не расходуется приличный бюджет.
Перестановка слов — тип, когда она получена с перестановкой слов из пользовательского запроса.
Дополнение / исправление начала запроса — тип, когда Яндекс дополнил фразу с её начала, а не в конце.
Если же подсказки вообще нет по запросу, то он будет скрыт / убран из итоговой таблицы. Такие фразы также следует исключать из продвижения.
К методу существует API, то есть пользователи, которые хотят интегрировать инструмент с каким-то своим сервисом или забирать данные по API — могут это сделать.
Удаче в сборе широкой и целевой семантики для сайта.
Задайте вопрос или оставьте комментарий
Перейти к инструменту «Поисковые подсказки Яндекса»
Платные инструменты для составления семантического ядра:
Базы Пастухова по мнению многих специалистов не имеют конкурентов. В базе отображаются такие запросы, которые не показывает ни Гугл, ни Яндекс. Существует много других особенностей, присущих именно базам Макса Пастухова, среди которых можно отметить удобную программную оболочку.
SpyWords — интересный инструмент, позволяющий анализировать ключевые слова конкурентов. С его помощью можно провести сравнительный анализ семантических ядер интересующих ресурсов, а также получить все данные о РРС и SEO компаниях конкурентов. Ресурс русскоязычный, разобраться с его функционалом не составит никаких проблем.
Key Collector — платная программа, созданная специально для профессионалов. Помогает составлять семантическое ядро, определяя актуальные запросы. Используется для оценки стоимости продвижения ресурса по интересующим ключевым словам. Помимо высокого уровня эффективности, данная программа выгодно отличается удобством в использовании.
SEMrush позволяет на основании данных с конкурирующих ресурсов определить наиболее результативные ключевые слова. С его помощью можно подобрать низкочастотные запросы, характеризующиеся высоким уровнем трафика. Как показывает практика, по таким запросам очень легко продвинуть ресурс на первые позиции выдачи.
SeoLib — сервис, завоевавший доверие со стороны оптимизаторов. Обладает достаточно большим функционалом. Позволяет грамотно составить семантическое ядро, а также выполнить необходимые аналитические мероприятия. В бесплатном режиме можно проанализировать 25 запросов в сутки.
Prodvigator позволяет собрать первичное семантическое ядро буквально за несколько минут. Это сервис используемый главным образом для анализа конкурирующих сайтов, а также для подбора наиболее результативных ключевых запросов. Анализ слов выбирается для Google по России или для Яндекса по Московскому региону.
Семантическое ядро собирается достаточно быстро, если использовать источники и базы данных в качестве подсказки.
Следует выделить следующие процессы
— Согласно содержанию сайта и релевантных тем выбираются ключевые запросы, которые наиболее точно отражают смысловую нагрузку вашего веб-портала.
— Из выбранного набора отсеиваются лишние, возможно, те запросы, которые могут ухудшить индексацию ресурса. Фильтрация ключевых слов проводится на основании результатов анализа, описанного выше.
— Полученное семантическое ядро должно быть равномерно распределено между страницами сайта, при необходимости заказываются тексты с определенной тематикой и объемом вхождения ключевых слов.
Может пригодиться: продвижение объекта недвижимости — действительно достойные результаты от Семантики
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |
Как поисковик формирует подсказки
У каждой системы – Яндекса, Google и даже YouTube, принадлежащего Google, – свои собственные уникальные алгоритмы. Тем не менее можно выделить несколько общих факторов, влияющих на появление определенных поисковых подсказок:
Региональность
Поисковики учитывают географию пользователей при формировании поисковых подсказок. Особенно это касается запросов, начинающихся со слов «купить», «заказать», «доставка», «где» и т. д.
 Примеры подсказок по коммерческому запросу
Примеры подсказок по коммерческому запросу
Популярность и актуальность
Подсказки выдаются с учетом того, что сейчас в тренде, освещается в соцмедиа.
 Google не скрывает, что тренды определяют поисковые подсказки
Google не скрывает, что тренды определяют поисковые подсказки
Это легко проверить на практике. Просто возьмите пару недавних новостей из СМИ и начните вводить в поисковую строку имена героев, названия брендов или города, где произошли те или иные события. Подсказки реагируют быстро, в отличие от Яндекс.Вордстата и готовых баз ключевых слов.
Поисковое поведение
Поисковики учитывают интересы пользователей, часто посещаемые сайты, предыдущие запросы. Персонализация улучшает качество поиска.
 Если вы уже вбивали в Яндексе запросы, которые начинались точно также – таковые появятся в самом верху списка
Если вы уже вбивали в Яндексе запросы, которые начинались точно также – таковые появятся в самом верху списка
Определение перспективных ключевых фраз
Когда денег на SEO мало (в случае с МСБ это почти всегда так), продвигаться по ядру из тысяч запросов не получится. Придется выбирать самые «жирные» из них, а остальные откладывать до лучших времен.
Один из способов — выбрать фразы, по которым страницы сайта находятся с 5 по 20 позицию в Google. По ним можно быстрее и с меньшими затратами выйти в ТОП-5. Ну и скачок позиций, скажем, с двенадцатой на третью даст намного больше трафика, чем с 100-й на 12-ю (узнать точный прирост трафика вы можете с помощью сценарного прогноза в Data Studio).
Позиции по ключевым фразам в Google доступны в Search Console. Для их выгрузки есть шаблон, описанный в Codingisforlosers.
Для выгрузки ключей из ТОП-20 необходимо:
- создать копию шаблона Quick Wins Keyword Finder (все шаблоны в статье закрыты от редактирования, просьба не запрашивать права доступа — просто создайте копию и используйте ее);
- установить дополнение для Google Sheets Search Analytics for Sheets (для настройки экспорта отчетов из Search Console в Google Sheets);
- иметь доступ к аккаунту в Search Console и накопленную статистику по запросам (хотя бы за пару месяцев).
Открываем шаблон и настраиваем выгрузку данных из Search Console (меню «Дополнения» / «Search Analytics for Sheets» / «Open Sidebar»).

Для автоматической выгрузки на вкладке «Requests»:
- в поле «Verified Site» выбираем сайт (после подтверждения доступа к аккаунту в появится список сайтов);
- в поле «Group By» выбираем «Query» и «Page» (то есть мы будем извлекать данные по запросам и страницам);
- в поле «Results Sheet» обязательно задаем «RAW Data», иначе шаблон работать не будет.

Нажимаем кнопку «Request Data». После экспорт данных на листе «Quick Wins» указаны запросы, страницы, количество кликов, показов, средний CTR и позиция за период. Эти ключи подходят для приоритетного продвижения.
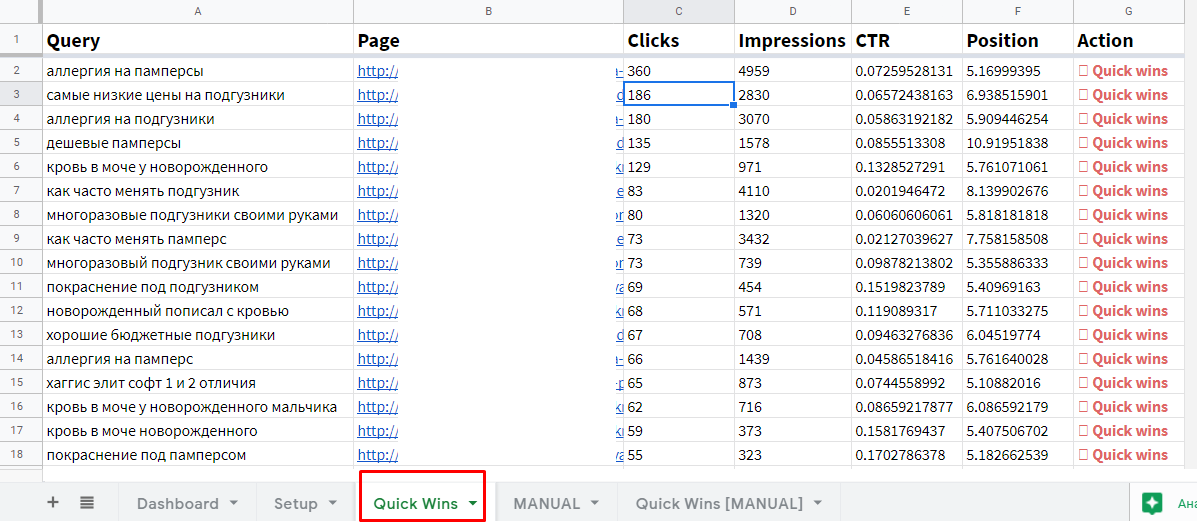
Помимо автоматической выгрузки в шаблоне есть ручной режим. Перейдите на вкладку «MANUAL» и введите данные (ключи, URL и позиции). На вкладке «Quick Wins » будет выборка перспективных запросов.
Как пользоваться сервисом для парсинга аудитории Pepper.Ninja?
Почему Pepper.Ninja? Просто в Pepper.Ninja есть все, что мне нужно, и даже больше. Например, с прямых трансляций во ВКонтакте он умеет собирать зрителей, а не только комментаторов, как другие сервисы.
В общем, это не обзор сервисов парсинга, поэтому покажу на примере Pepper.Ninja, которым пользуюсь сам. Конкретнее – функции «Кто мой клиент 3.0».
«Кто мой клиент 3.0» – это фильтр, который ищет похожую аудиторию из загруженного вами в сервис списка или пользователей, состоящих в тематических сообществах. Парсер:
- проанализирует ЦА;
- подготовит подробную аналитику;
- соберет готовые базы для рекламной кампании;
- найдет похожие сообщества с потенциальными клиентами.
У вас будет две группы пользователей: горячая и теплая аудитория. Еще – подробная статистика по каждой группе и список сообществ, на которые подписаны пользователи. Готовую базу вы сможете сразу выгрузить в рекламный кабинет или отфильтровать по более четким параметрам.
Как это выглядит на практике?
Поиск по ключевым словам. Предположим, что нам надо найти людей, увлекающихся настольным теннисом в Москве. Для этого заходим в парсер «Кто мой клиент 3.0», указываем ключевое слово «настольный теннис», выбираем страну и город.

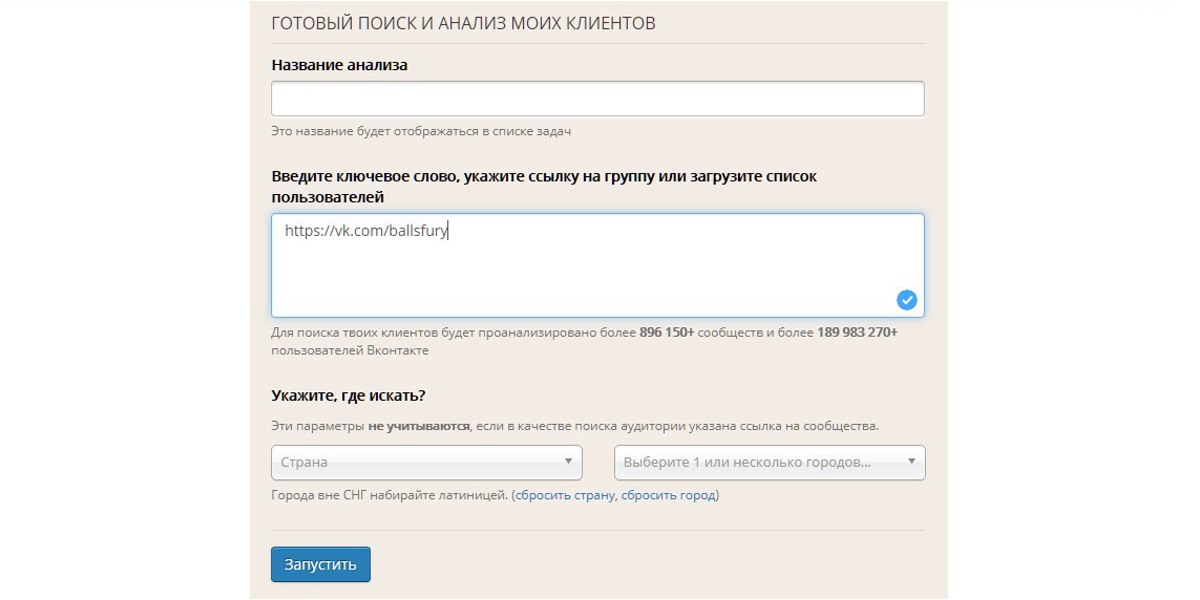
Переходите в раздел «Задания». Жмите на значок воронки напротив выгрузки и применяйте нужные фильтры к найденной аудитории. Затем жмите «сэндвич» в той же строке и выбирайте «Посмотреть результаты».
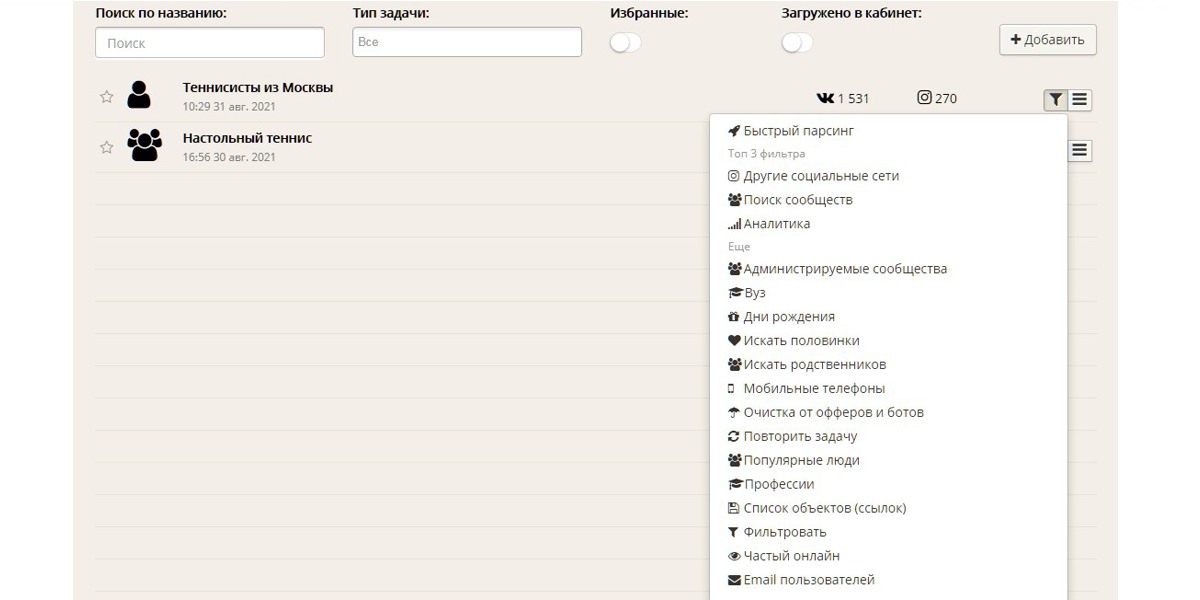
Откроется новое окно, в котором можно посмотреть количество найденной аудитории и подробную аналитику. Собираются данные по городам, странам, полу, возрасту, профессиям и университетам пользователей. Еще парсер покажет 300 самых популярных групп у людей из выгрузки.
Вы можете выбрать конкретные сообщества из перечня и добавить их в список для сохранения – создайте новый список или выберите уже существующий.

Добавить в список для дальнейшей работы можно все выбранные сообщества или по одному. Для выгрузки нескольких групп жмите значок облачка со стрелкой, для выгрузки по одному – жмите «Добавить в список» под названием паблика.
Теперь вы можете парсить список, чтобы выгрузить нужную аудиторию групп. Или примените фильтрацию, например, чтобы сразу отсеять пользователей из регионов, которые бесполезны для вашей задачи.
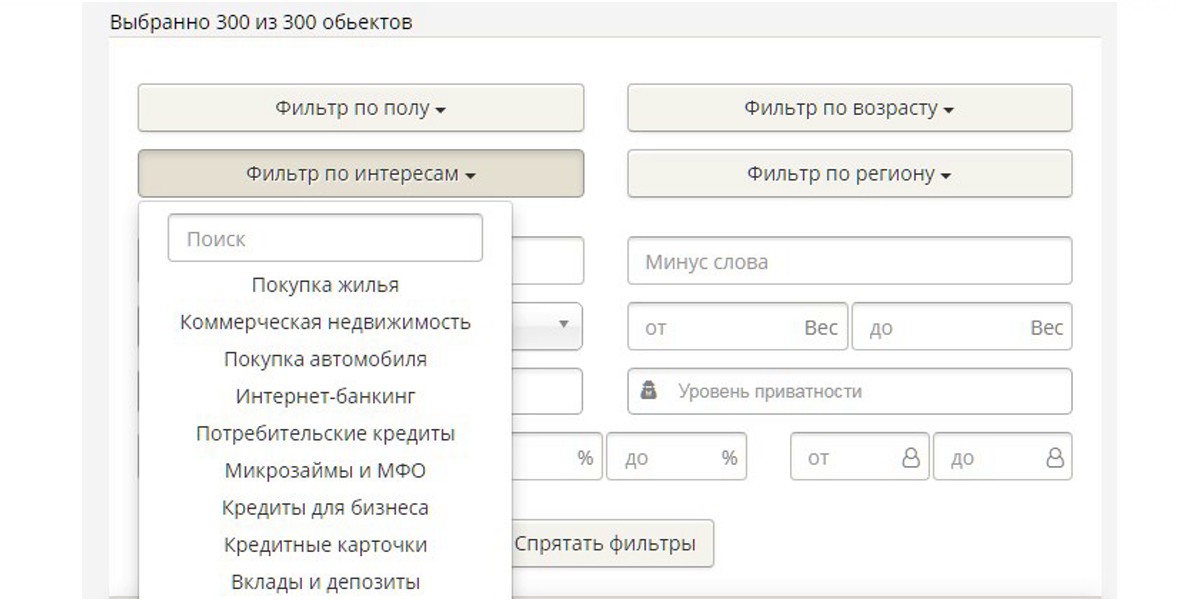
Вот и все.
Полученные данные вы можете скачать в форматах Excel или CSV – парсер выгрузит информацию профилей участников со всеми полями
Обратите внимание: «Кто мой клиент 3.0», даже если парсит во ВКонтакте, автоматически находит аккаунты пользователей в Инстаграме, то есть вы можете скачать ID, профили и ссылки на профили как во ВКонтакте, так и в Инстаграме. Или сразу выгружайте базу в рекламный кабинет во ВКонтакте
Что еще умеет Pepper.Ninja? Все, о чем говорил в статье, и кое-что еще. Например:
- собирать аудиторию в обсуждениях под постом;
- находить в сообществах контакты пользователей или сотрудников, которые указали в профиле паблик как место работы;
- искать пользователей по статусу, месту работы, должности, религии, имени, фамилии и даже имени ребенка;
- собирать сообщества, где еще есть ваша ЦА;
- находить друзей и родственников пользователей.
- собирать рекламные посты конкурентов, искать самые интересные и выделять активную аудиторию промопоста;
- находить пользователей в Инстаграме по геоточке – сможете сконвертировать российскую аудиторию в емейл и телефоны для настройки рекламы в Фейсбуке.
Список можно продолжать еще долго, но лучше изучить возможности парсера на практике. Исключайте пассивную аудиторию, экономьте рекламный бюджет, изучайте самые популярные посты и повышайте эффективность своего контента!
Магадан

Парсер ключевых слов Магадан един в двух лицах вариант Lite распространяется совершенно бесплатно. Хотя программа имеет незначительные символические ограничения, даже бесплатная версия помогает выполнить большинство задач.
Существует платная версия программного обеспечения, которая распространяется по символической плате в 1 500 рублей. Среди наиболее ярких различий двух версий:
-
Регионы. Бесплатная версия лишена возможности указать конкретный регион, по которому парсятся слова. Платная версия дает такую возможность.
-
Базы разрешенных и запрещенных слов. Бесплатная версия лишена возможности подключить базы. В платной версии можно это делать.
- Гибкость списка правил. В бесплатной версии нельзя указать правила, которые генерируют производные ключи. В платной версии эта возможность доступна.
В целом, Магадан по праву считается одним из наилучших парсеров среди представленных в рунете.
Как осуществить наиболее эффективный сбор?
Пользоваться инструментом несложно благодаря интуитивно понятному интерфейсу.
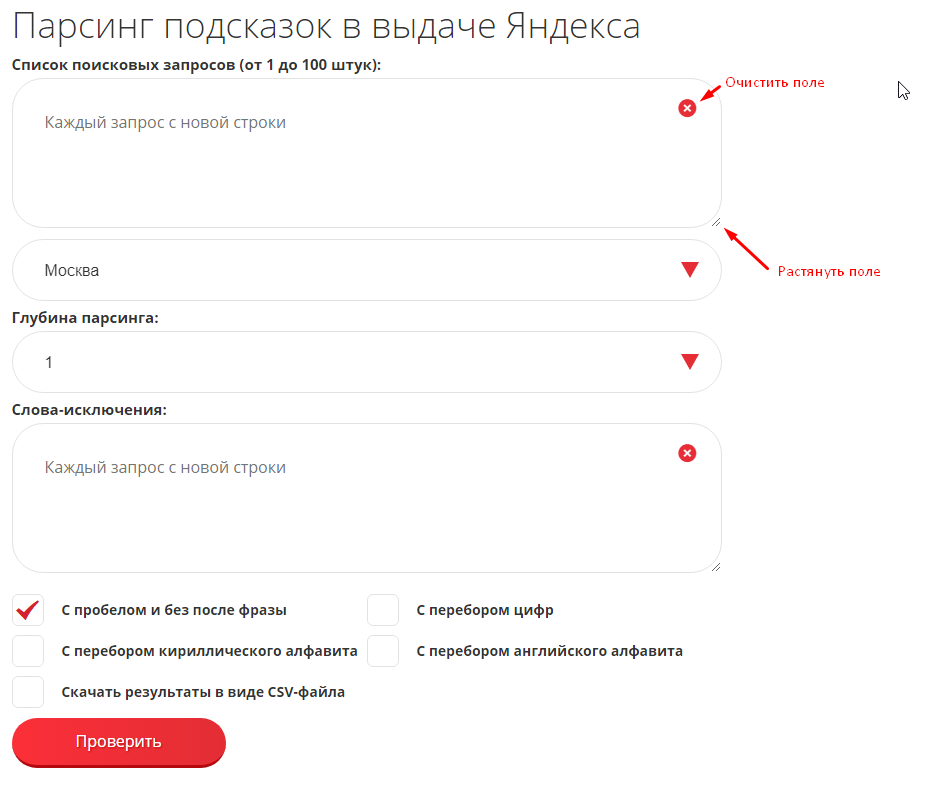
В первую форму вводятся поисковые фразы, для которых необходимо спарсить подсказки. В случае ошибки, можно нажать на крестик в правом верхнем углу и очистить форму. Кроме того, если фраз достаточно много, для удобства можно увеличить поле, потянув значок в правом нижнем углу.
После ввода фраз, из выпадающего меню требуется задать необходимый регион продвижения.
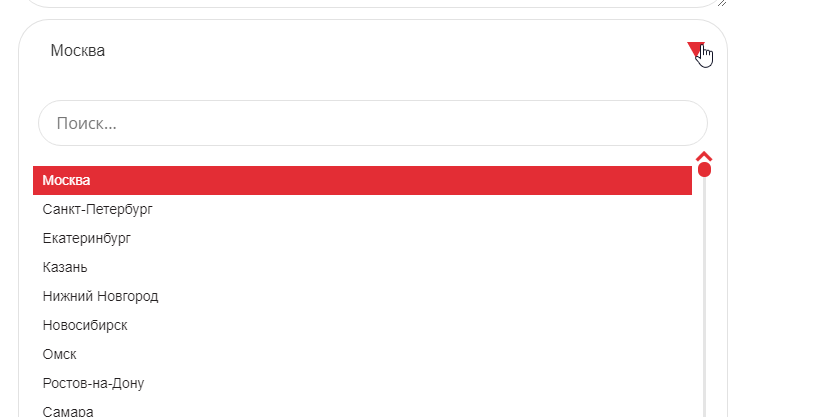
Дальнейшие настройки — зависят от решаемых задач.
Параметр «Глубина парсинга» отвечает за итерационный сбор.
Если указана цифра 1, сбор подсказок будет осуществляться только для фраз, введенных в поле «Список поисковых запросов». Если же нужна более широкая семантика, то имеет смысл сначала собрать подсказки к имеющимся ключевым фразам, а затем — подсказки к уже полученным. Этот последовательный сбор можно выполнить за одну операцию, просто выставив глубину парсинга, равную двум.
Например, если требуется сначала спарсить поисковые подсказки по слову , а затем дополнить их теми подсказками, которые были собраны, например, к , то сервис «Пиксель Тулс» окажется крайне полезен для этой задачи.
Кроме того, инструмент позволяет воспользоваться словами-исключениями для того, чтобы не собирать подсказки, содержащие ненужные слова, например, или .
Зачем они нужны пользователям
В 2012 году в Яндексе подсчитали, что пользователи в общей сложности потеряют 60 лет, если взять и в один прекрасный день отключить поисковые подсказки. Столько бы в совокупности им всем понадобилось на формулировку и исправление своих запросов. Сейчас, как вы понимаете, и пользователей, и поисковых запросов намного больше.
Поисковые подсказки экономят время пользователя: не надо вручную дописывать свой запрос, если можно просто выбрать подходящий вариант, предложенный поисковой системой.
 Особенно актуальны поисковые подсказки на мобильных устройствах, где печатать не очень удобно
Особенно актуальны поисковые подсказки на мобильных устройствах, где печатать не очень удобно