Что такое парсинг и как он помогает экономить на рекламе?
Содержание:
- Вред имуществу и убытки
- Приоритет и ассоциативность операций
- Зачем парсят сайты
- Определение перспективных ключевых фраз
- Парсинг сайта — что это
- Способы применения
- Сила парсинга
- Парсеры сайтов по способу доступа к интерфейсу
- Для чего используют
- Парсить — что это обозначает простыми словами?
- Получение в cURL страниц со сжатием
- Нарушение пользовательского соглашения
- Какой вред сайтам приносит парсинг
- Зачем нужен парсинг?
- Каков алгоритм, по которому работает парсер?
- Начинаем
- Поищите JSON в HTML коде страницы
- Варианты разбора
Вред имуществу и убытки
Начнём с нетипичных и неочевидных вариантов. Казалось бы, при чём здесь вред имуществу, когда речь о программах, делающих что-то в интернете? На самом деле такой подход к вопросу нельзя исключать. Да, информация, сайты, программы — это нематериальные объекты, но серверы, на которых всё работает — вполне себе материальные. Если из-за парсинга что-то случится с сервером, то вполне можно говорить о вреде имуществу. Грубо говоря, если кто-то станет парсить сайт так активно, что сервер задымится и сломается, то можно будет поставить вопрос о возмещении вреда, причинённого имуществу.
нужно как-то оценить вред и доказать, что его размер не взяли с потолка, а посчитали правильно;
нужно доказать, почему парсинг действительно является правонарушением (тут тоже всё не так просто, но некоторые возможные обоснования будут в следующих разделах статьи);
нужно доказать, что вред возник именно из-за парсинга (а не из-за кривой конфигурации сервера и плохой защиты от ботов);
наконец, нужно доказать, что даже если нарушитель и не хотел ничего плохого (то есть не было умысла), но всё равно по-хорошему он мог бы предвидеть последствия, если бы подумал хотя бы в рамках «здравого смысла» (юридически это будет называться «лёгкая неосторожность»).
Кроме того, нарушителя ещё нужно найти, а это тоже та ещё задачка: «я тебя по IP вычислю» — не более чем мем, а в реальности нужно будет в исковом заявлении указать почтовый адрес, причём полиция не подскажет: они розыском по гражданским делам не занимаются. Словом, хотя в теории привлечь к ответственности можно, на практике это один из самых трудных вариантов.
Когда серверы были слабее, вариант с причинением вреда смотрелся чуть реалистичнее. В частности, в конце 1990-х одна американская компания парсила Ebay. Ebay обратился в суд. Основание — парсер делал 100 тысяч запросов в сутки, что составляло 1,5% от общего трафика на сайт. Это привело к дополнительным расходам на обслуживание серверов — следовательно, финансовые потери должны быть возмещены, а парсинг прекращён. Дело в итоге закончилось мировым соглашением (пример я взял из книги «Web Scraping with Python»). Сейчас серверы намного мощнее, так что вряд ли парсинг реально «положит» сайт или как-то ещё приведёт к убыткам для владельца.
Приоритет и ассоциативность операций
Чтобы решить обе проблемы, нам нужно дать парсеру информацию о приоритетах операций.
Делать мы это будем через таблицы . Эти таблицы можно сделать глобальными и переиспользовать между парсерами, но нам проще разместить их прямо в конструкторе парсера, для локальности кода:
Метод теперь будет принимать аргумент :
С помощью нового аргумента парсер знает, когда продолжать, а когда остановиться, что позволяет правильно связать итоговое AST.
Каждый парслет теперь должен передать свой (приоритет) при вызове :
связывает выражения как лево-ассоциативные. Чтобы разобрать право-ассоциативные выражения, нужно вычесть 1 из приоритета операции:
В начале статьи мы уточнили, что у нас будет право-ассоциативный, поэтому обрабатываться побитовый сдвиг будет с помощью .
Зачем парсят сайты
Парсинг сайтов интересен прежде всего маркетологам. Первоочередная цель парсинга – мониторинг цен у конкурентов, анализ их ассортимента, отслеживание акций на товары. «Кто, что, почём и в каких объемах продает?» – вот главные вопросы, на которые призван дать ответ парсинг. Вот пример парсера служащего этим целям.
Кроме этого, парсинг может быть использован для получения контента. Что дает возможность создавать и обновлять сайты, схожие по структуре, оформлению, содержанию. Например, наполнить каталог онлайн-аптеки на базе уже существующих в сети ресурсов.
Пожалуй, самое безобидное применение парсинга – так называемый «самопарсинг». Довольно оригинальный способ проверить собственный ресурс на предмет ошибок в коде, битых ссылок, соответствия выложенного на сайте ассортимента реальному положению дел на складе, и т.п.
И наконец, к горечи простых людей, парсинг сайтов объявлений (тех же Сian или Avito) – практика распространенная. Сбор данных пользователей здесь идет не совсем с невинными целями. Просканировав доску объявлений, парсер выдаст готовенькую таблицу с контактами пользователей, а далее – все прелести в духе «правовых оттенков серого»: перепродажа баз туроператорам, риэлторам, а то и промышляющим телефонным спамом конторам и прочим надоедливым слепням на теле обывателя.
Определение перспективных ключевых фраз
Когда денег на SEO мало (в случае с МСБ это почти всегда так), продвигаться по ядру из тысяч запросов не получится. Придется выбирать самые «жирные» из них, а остальные откладывать до лучших времен.
Один из способов — выбрать фразы, по которым страницы сайта находятся с 5 по 20 позицию в Google. По ним можно быстрее и с меньшими затратами выйти в ТОП-5. Ну и скачок позиций, скажем, с двенадцатой на третью даст намного больше трафика, чем с 100-й на 12-ю (узнать точный прирост трафика вы можете с помощью сценарного прогноза в Data Studio).
Позиции по ключевым фразам в Google доступны в Search Console. Для их выгрузки есть шаблон, описанный в Codingisforlosers.
Для выгрузки ключей из ТОП-20 необходимо:
- создать копию шаблона Quick Wins Keyword Finder (все шаблоны в статье закрыты от редактирования, просьба не запрашивать права доступа — просто создайте копию и используйте ее);
- установить дополнение для Google Sheets Search Analytics for Sheets (для настройки экспорта отчетов из Search Console в Google Sheets);
- иметь доступ к аккаунту в Search Console и накопленную статистику по запросам (хотя бы за пару месяцев).
Открываем шаблон и настраиваем выгрузку данных из Search Console (меню «Дополнения» / «Search Analytics for Sheets» / «Open Sidebar»).

Для автоматической выгрузки на вкладке «Requests»:
- в поле «Verified Site» выбираем сайт (после подтверждения доступа к аккаунту в появится список сайтов);
- в поле «Group By» выбираем «Query» и «Page» (то есть мы будем извлекать данные по запросам и страницам);
- в поле «Results Sheet» обязательно задаем «RAW Data», иначе шаблон работать не будет.

Нажимаем кнопку «Request Data». После экспорт данных на листе «Quick Wins» указаны запросы, страницы, количество кликов, показов, средний CTR и позиция за период. Эти ключи подходят для приоритетного продвижения.
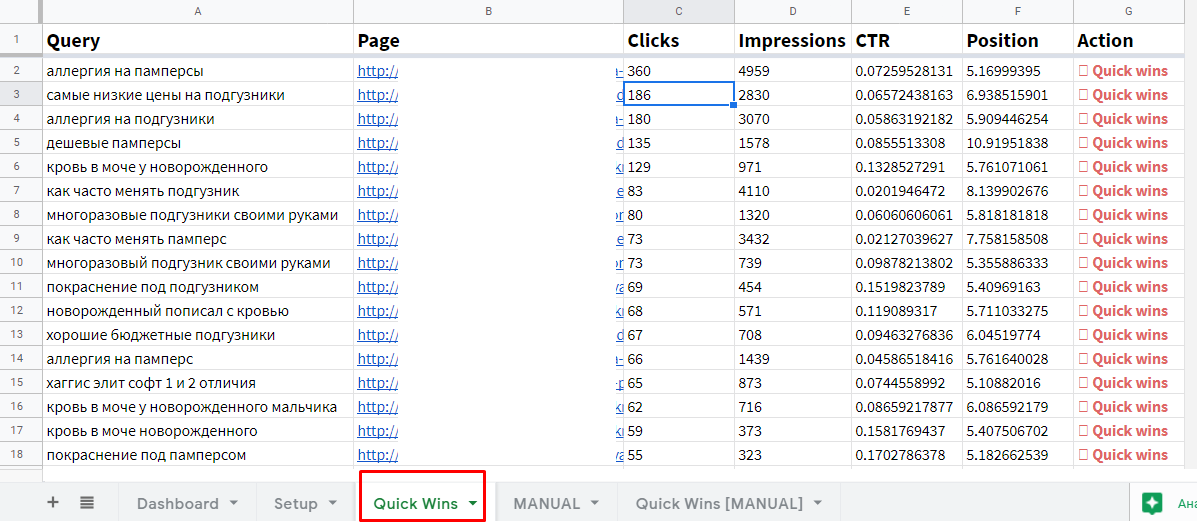
Помимо автоматической выгрузки в шаблоне есть ручной режим. Перейдите на вкладку «MANUAL» и введите данные (ключи, URL и позиции). На вкладке «Quick Wins » будет выборка перспективных запросов.
Парсинг сайта — что это
В общем случае, парсинг строит шаблон последовательности символов. Например, может использоваться древовидная структура. Она показывает, в какой последовательности в строке встречаются символы. Может указывать на приоритет, если речь идет о математическом выражении.
Такие структуры нужны для анализа данных.
Парсить можно и интернет-ресурсы. Это делают, когда нужно понять, какой контент содержится на странице.
Найти на страницах сайта только ту информацию, которая нужна вам для анализа — это задача парсинга.
Например, название, цену на товар, категорию и описание. Далее вы уже сможете проанализировать это. Например, решить, какую цену установить для своего ассортимента.
А может, вам нужно поработать с отзывами клиентов? Это тоже задачка для парсинга сайта — собираете нужную информацию в одном месте и читаете, что о вашем конкуренте пишут клиенты.
Способы применения
Парсинг для начинающих начинается с анализа конкурирующих фирм, чтобы сформировать собственную ценовую политику и план продвижения, стратегию интернет-маркетинга. А уже уверенные пользователи одновременно используют парсеры и для изучения конкурентов, и для аудита своего ресурса, для сравнения полученных сведений. Такая работа в тесной связке помогает поддерживать конкурентоспособность на высоком уровне.

Как парсить данные
Можно пойти двумя путями – купить программу, которых представлено большое множество, или создать приложение собственными силами фактически на любом из языков программирования.
Второе особенно актуально, когда нужно выставить только несколько параметров. Посмотрим теперь на особенности парсинга некоторых данных для «чайников».
Как спарсить цену
Определение ценовой политики – это самая ходовая задача для приложений. Для этого необходимо посмотреть код анализируемого товара и ввести его в программу. Она автоматически подтянет другие позиции, отвечающие запросу. Сэкономить время и повысить эффективность можно, если ограничить круг страничек. Например, так он не будет искать по разделу с информационными статьями. Добавлять стоит категории и сами карточки продукции. Прописываются ссылки на них в карте XML.
Как парсить структуру сайта
Это важное занятие, которым также часто занимаются новички. Основная задача – узнать, из каких разделов, подразделов и категорий состоит веб-ресурс, чтобы сделать аналогичные
Структурирование определяется, благодаря изучению breadcrumbs, или хлебных крошек в буквальном переводе. На самом деле термин подразумевает навигационную цепочку, которая выстраивается от начального элемента (корневого файла) до итогового.

Что нужно для этого сделать:
- навести курсор на одну из строчек навигации;
- скопировать код по аналогии с тем, как мы это делали с ценами;
- отправить его в приложение.
Данный алгоритм следует повторить и с другими элементами структуры.
Сила парсинга
Но какое это всё имеет отношение к заголовку статьи? В конце концов, мы просто изучили два разных способа проверить список на пустоту — и, на первый взгляд, тут нет никакого парсинга. Такая интерпретация тоже верна, однако я предлагаю посмотреть на это с другой стороны: с моей точки зрения, вся разница между валидацией и парсингом полностью состоит в том, как сохраняется информация об этом процессе. Давайте сравним две такие функции:
Эти две функции практически идентичны: они проверяют переданный список на пустоту, и если он пустой, то они возвращают сообщение об ошибке. Вся разница заключается в возвращаемом значении: всегда возвращает , тип, который не содержит никакой информации, а возвращает , уточнение входного типа, которое сохраняет полученное знание в системе типов. Обе функции проверяют одно и то же, но даёт вызывающему коду доступ к полученной информации, а просто выкидывает её.
Эти две функции элегантно иллюстрируют два различных взгляда на роль системы типов: просто подчиняется тайпчекеру, но только полностью использует те преимущества, которые он даёт. Если вы видите, почему функция предпочтительнее, то вы должны уже понимать, что означает мантра «парсите, а не валидируйте». Однако возможно вы скептически относитесь к имени . Действительно ли она что-то парсит, или она просто валидирует вход и возвращает результат? И, хотя точное определение того, что означает парсинг или валидация, является предметом для обсуждения, я считаю что это полноценный парсер, пусть и очень простой.
Подумайте: что такое парсер? В действительности, парсер это всего лишь функция, которая принимает менее структурированный вход, и производит более структурированный выход. По самой своей сути, парсер это частичная функция — некоторые значения домена не соответствуют ни одному допустимому значению — таким образом, все парсеры должны иметь какое-то представление об ошибке. Зачастую, входом парсера является текст, но это ни коим образом не является обязательным требованием, и наш это совершенно законный парсер: он парсит списки в непустые списки, сигнализируя о неудаче сообщением с текстом ошибки.
По такому определению парсеры являются невероятно мощными инструментами: они позволяют производить проверки заранее, прямо на границе приложения и внешнего мира, и как только эти проверки пройдены, их не надо совершать снова! Rust разработчики знают об этой мощи, и они используют множество различных парсеров на постоянной основе:
Все эти библиотеки объединяет одно: они располагаются на границе между вашим приложением и внешним миром. Этот мир не общается в терминах типов-произведений и типов-сумм, он использует потоки байт, поэтому без парсинга тут не обойтись. И, совершая этот парсинг заранее, до того, как мы начинаем работать с этими данными, мы исключаем множество багов, часть из которых могут быть даже серьёзными уязвимостями.
У этого подхода, правда, есть один недостаток: иногда значения необходимо парсить задолго до того, как они действительно понадобятся. Но есть и плюсы: в динамически-типизированных языках поддерживать в соответствии парсинг и бизнес логику довольно трудно без обширного покрытия тестами, многие из которых утомительно поддерживать. При этом в статической системе типов проблема становится удивительно простой, как показано на примере выше: если парсинг и бизнес логика рассинхронизируются, то программа просто не скомпилируется.
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Облачные сервисы не требуют установки на ПК. Все данные хранятся на серверах разработчиков, вы скачиваете только результат парсинга. Доступ к программному обеспечению осуществляется через веб-интерфейс или по API.
Примеры облачных парсеров с англоязычным интерфейсом:
- http://import.io/,
- Mozenda (есть также ПО для установки на компьютер),
- Octoparce,
- ParseHub.
Примеры облачных парсеров с русскоязычным интерфейсом:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
У всех сервисов есть бесплатная версия, которая ограничена или периодом использования, или количеством страниц для сканирования.
Программы-парсеры
ПO для парсинга устанавливается на компьютер. В подавляющем большинстве случаев такие парсеры совместимы с ОС Windows. Обладателям mac OS можно запускать их с виртуальных машин. Некоторые программы могут работать со съемных носителей.
Примеры парсеров-программ:
- ParserOK,
- Datacol,
- SEO-парсеры — Screaming Frog, ComparseR, Netpeak Spider и другие.
Для чего используют
Для чего копировать чужую информацию, если можно написать свою? Чтобы заработать много денег, следует создавать как можно больше вариантов контента Ваших рекламных объявлений с потенциально заинтересованными лицами. Если Вы сами будете кропотливо наполнять сайт уникальными статьями, то потеряете много времени и шанс заработать больше. Зачем придумывать велосипед, если можно спарсить уже готовый контент?
Что будет, если все начнут «слизывать» друг у друга контент? За безразборное копирование программы Яндекс может наказать Вас и Ваш сайт негативной позицией сайта при выдаче запросов. Также грозит черный список.

Поисковик
Прекрасно парсинг зарекомендовал себя среди таргетологов, которые занимаются сбором целевых аудиторий для настройки таргетированной рекламы на нее. Здесь можно реализовать творческие идеи – начиная о поиске горячей аудитории с сиюминутным желанием приобрести товар до людей, которые однажды интересовались или заходили на сайты, чтобы посмотреть цену. Вопрос настройки параметров для выявления целевой аудитории заключается лишь в том, насколько креативно специалист подходит к пониманию портрета своего потенциального клиента.

Парсинг для аудитории
Парсить — что это обозначает простыми словами?
С появлением новых технологий в нашем обиходе появляются новые слова, значения которых многие не знают и не могут понять, что они означают. Много терминов приходит с других языков. В основном в последние десятилетия они приходят в русский язык из англоязычных стран. Одним из таких является слово «парсить«. Так что же это такое?
Определение
Термин «парсить» пришло в русский из английского языка и означает – разбирать, проводить анализ. Это слово употребляют в своей терминологии разработчики Интернет ресурсов, программисты и т. д. В их среде в большинстве случаев означает поиск и копирование чужого контента на свой сайт, а также процедура разбора, проведения анализа статьи. Ещё в информатике это означает – проведение анализа, при котором разрабатываются математические модели сравнения.
Также означает сбор информации в Интернете, используя для этого специально разработанные программы – «парсеры«, которые позволяют сравнивать предложенные сегменты в разработанной базе с теми, что есть в Интернете. Они часто используются аналитиками, экономистами и бизнесменами в разных сегментах экономики.
Для чего применяются
Сбор сведений для исследования рынка
Такая программный продукт может отследить необходимую информацию, что даст специалисту определить, в каком направлении будет развиваться та или иная компания или отрасль в целом, например, в ближайшие полгода. Таким образом, утилита даёт фундамент, базу специалисту для проведения глубокого анализа, что даст компании поднять свой уровень продаж в своём рыночном секторе услуг или производства.
Подобная утилита способна получать информацию от многих источников, которые специализируются на проведении аналитики и компаний по исследованию рынка. И только потом можно будет объединять все полученные сведения для сравнения и проведения глубокого анализа.
Отбор сотрудников или поиск работы
Для работодателя, который динамично разыскивает претендентов в интересах принятия на работу в свою фирму, либо для соискателя, который подыскивает себе работу с определённой должностью, подобная разработка также будет востребована. С её помощью проводится настройка и подборка исходных данных в базе разных применяемых фильтров и результативно извлекать нужное, без обыденного поиска вручную.
Получение сведений
- Так же их применяют, для того чтобы составлять и классифицировать информацию:
- почтовые или электронные адреса,
- контакты с разных веб-сайтов и соцсетей.
Это даёт возможность создавать простые списки контактов и целой сопутствующих данных в интересах бизнеса – о покупателях, посредниках либо изготовителях.
- Изучение стоимости товара в различных онлайн магазинах
- Такие ресурсы могут быть полезны и тем, кто оживлённо пользуется предложениями онлайн магазинов, следит за ценами на продукты питания, разыскивает товары на многих сайтах одновременно.
Самые известные парсеры
https://youtube.com/watch?v=6Anf5nIhuCI
Самые крупные и известные системы, которые занимаются парсером – это, конечно же, Яндекс и Google. Их программы, когда юзер хочет что-то найти во Всемирной паутине и вводит в поисковик, что именно необходимо ему найти, начинают искать из десятков миллионов веб-ресурсов именно то, что нужно юзеру. Выдают ему несколько сотен сайтов на выбранную тему, из которых он ищет необходимую ему информацию.
А перечисленные выше возможности программ для того чтобы «парсить» являются более узкоспециализированными, и их программисты разрабатывают для различных крупных фирм, которые с их помощью определяют свои возможности и конкурентов. Всё это облегчает проведение необходимых мероприятий, так как происходит всё в автоматическом режиме, и специалист может получить всё нужное в виде таблиц или графиков, что упрощает его дальнейшую работу. Ему не нужно тратит драгоценное время на поиск.
Получение в cURL страниц со сжатием
Иногда при использовании cURL появляется предупреждение:
Warning: Binary output can mess up your terminal. Use "--output -" to tell Warning: curl to output it to your terminal anyway, or consider "--output Warning: <FILE>" to save to a file.
Его можно увидеть, например при попытке получить страницу с kali.org,
curl https://www.kali.org/
Суть сообщения в том, что команда curl выведет бинарные данные, которые могут навести бардак в терминале
Нам предлагают использовать опцию «—output -» (обратите внимание на дефис после слова output – он означает стандартный вывод, т.е. показ бинарных данных в терминале), либо сохранить вывод в файл следующим образом: «—output «.
Причина в том, что веб-страница передаётся с использованием компрессии (сжатия), чтобы увидеть данные достаточно использовать опцию —compressed:
curl --compressed https://www.kali.org/
В результате будет выведен обычный HTML код запрашиваемой страницы.
Нарушение пользовательского соглашения
На некоторых сайтах есть условия использования или пользовательские соглашения. Это те самые документы, которые «прячутся» в «подвале» и которые редко читают. А зря: в пользовательском соглашении может оказаться пункт, запрещающий парсинг. Следовательно, тот, кто парсит, нарушает пользовательское соглашение, и это плохо. Но «плохо» — это моральная оценка. Что говорит право?
Пользовательское соглашение — это, по сути, договор, а договоры должны исполняться. Если не исполняются, можно привлечь к гражданско-правовой ответственности. Например, если в пользовательском соглашении написано: «Штраф за парсинг — 1 миллион рублей», то в наказание за парсинг, исходя из условий договора, действительно можно потребовать миллион.
А заключён ли договор? Договор должен исполняться, но только в том случае, если пользователь его, упрощённо говоря, подписал. Заходя на сайт, никто никаких договоров обычно не подписывает. Максимум мы нажимаем «ОК» на уведомление о cookie, но это не пользовательское соглашение. Пользовательское соглашение по-прежнему лежит где-то на задворках сайта. Мы предполагаем, что оно есть, но фактически его не видим и не ищем. Кроме того, если мы просто зашли на сайт без регистрации, то нам никто о пользовательском соглашении и не говорит. Так должны ли мы ему подчиняться?
Есть два типа соглашений: click-wrap и browse-wrap. Click-wrap — это когда нужно нажать кнопку или поставить галочку «Я согласен с условиями». Browse-wrap — это когда договор находится на какой-то странице сайта, и нужно самому зайти туда и прочитать. С click-wrap всё сравнительно просто: человек жмёт на кнопку или ставит галочку и тем самым «подписывает» договор. С browse-wrap ситуация куда сложнее. Для заключения договора требуется, чтобы субъект выразил свою волю. Когда договор просто лежит где-то на сайте, невозможно понять, выразил ли субъект свою волю. Следовательно, если пользователь просто зашёл на сайт, то без дополнительных доказательств вряд ли можно сказать, что договор заключён. Нет договора — нет обязанностей.
Если парсит зарегистрированный пользователь, то с заключённостью договора проблем меньше: при регистрации нужно согласиться с условиями использования. Если эти условия запрещают парсинг, то владелец сайта может применить санкции, предусмотренные договором. Простейшая санкция — это бан, который юридически может являться приостановлением оказания услуг или расторжением договора в одностороннем порядке.
Какой вред сайтам приносит парсинг
Парсинг сайтов может принести не только пользу, но и вред. По наблюдениям за этим блогом выяснилось, что от парсинга повышается нагрузка на сервер, это грозит отключение сайта от хостинга, либо требует оплаты тарифа за повышенную нагрузку. Кроме того, парсинг сайтов приводит к скликиванию рекламы от Яндекса и Гугла, что ведет с резкому снижению выплат за рекламу от указанных сервисов. Согласитесь, это уже наносит прямой вред владельцу сайта, который парсят.
Боты от программы парсер искажают статистику сайтов, понижают ранжирование сайтов, а значит, влияют на позиции статей и сайта в целом. Именно по этой причине на блоге сначала растет посещаемость за счет ботов, а затем резко падает после окончания процесса парсинга.
Чтобы такой проблемы не возникало, рекомендуется использовать варианты защиты от парсинга. О них будет рассказано позже.
Определить парсинг сайта можно по увеличению посещаемости на сайте (блоге). Через статистику LiveInternet, Яндекс Метрику, можно посмотреть, откуда заходят боты. Например, может увеличиться посещаемость за счет соцсетей или посещаемость из закладок. У меня заходили именно их этих источников. Сделав беглый анализ, можно сразу же понять, что Ваш блог (сайт) парсят.
Зачем нужен парсинг?
Сбор информации в интернете – трудоемкая, рутинная, отнимающая много времени работа. Парсеры, способные в течение суток перебрать большую часть веб-ресурсов в поисках нужной информации, автоматизируют ее.
Наиболее активно «парсят» всемирную сеть роботы поисковых систем. Но информация собирается парсерами и в частных интересах. На ее основе, например, можно написать диссертацию. Парсинг используют программы автоматической проверки уникальности текстовой информации, быстро сравнивая содержимое сотен веб-страниц с предложенным текстом.
Возможностью «спарсить» чужой контент для наполнения своего сайта пользуются многие веб-мастера и администраторы сайтов. Это оправдано, если требуется часто изменять контент для представления текущих новостей или другой, быстро меняющейся информации.
Парсинг – «палочка-выручалочка» для организаторов спам-рассылок по электронной почте или каналам мобильной связи. Для этого им надо запустить «бота» путешествовать по социальным сетям и собирать «телефоны, адреса, явки».
Ну и хозяева некоторых, особенно недавно организованных веб-ресурсов, любят наполнить свой сайт чужим контентом. Правда, они рискуют, поскольку поисковые системы быстро находят и банят любителей копипаста.
Каков алгоритм, по которому работает парсер?
Для начала работы необходимо иметь тексты. Парсер успешно ищет файлы в Интернете и скачивает их. Затем занимается непосредственно обработкой текстов. После обработки происходит процесс оформления текстов в файл, вид которого задается пользователем – это как текстовый файл, так и базы данных и прочее.
Парсинг – процесс, который скидывает с плеч пользователя огромный груз нудной и очень долгой работы по поиску и оптимизации контента для его сайта. Эта статься оказалась полезной для тех, кто искал ответы на вопросы: как работает парсер, как написать его самому и чем руководствоваться.
Начинаем
Сперва установите все необходимые библиотеки, запустив pip install.
pip install requests beautifulsoup4 pandas
Получить HTML-код из URL-адреса мы можем при помощи библиотеки . Затем контент передается в BeautifulSoup, после чего можно начать получать данные и делать запросы с помощью селекторов. В детали вдаваться мы не будем, лишь скажем, что селекторы CSS используются для получения отдельных элементов и содержимого страницы. Синтаксис при этом бывает разный, но это мы рассмотрим позже.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://zenrows.com")
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.title.string)
Чтобы не запрашивать HTML каждый раз, мы можем сохранить его в HTML-файле и уже оттуда загружать BeautifulSoup. Чисто для демонстрации давайте сделаем это вручную. Самый простой способ – это просмотреть исходный код страницы, скопировать и вставить его в файл
Важно посетить страницу без входа в систему, как это сделал бы поисковый робот
Получение HTML-кода может показаться простой задачей, но это далеко не так. Вообще эта тема тянет на отдельную полноценную статью, так что здесь мы затронем ее лишь вскользь. Мы советуем использовать статический подход из примера ниже, поскольку многие сайты после нескольких запросов начнут перенаправлять вас на страницу входа. Некоторые покажут капчу, и в худшем случае ваш IP будет забанен.
with open("test.html") as fp:
soup = BeautifulSoup(fp, "html.parser")
print(soup.title.string) # Web Data Automation Made Easy - ZenRows
После статической загрузки из файла мы сможем делать сколько угодно попыток запросов, не имея проблем проблем с сетью и не опасаясь блокировки.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? Нет!
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен!
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
 Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят. И наш любимый (у парсеров) Linkedin!
И наш любимый (у парсеров) Linkedin!
Алгоритм действий такой:
-
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
-
Внизу ищите длинную длинную строчку с данными.
-
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто.
-
Вырезаете JSON из HTML любыми костылямии (я использую ).
Варианты разбора
- Решать задачу в лоб, то есть анализировать посимвольно входящий поток и используя правила грамматики, строить АСД или сразу выполнять нужные нам операции над нужными нам компонентами. Из плюсов — этот вариант наиболее прост, если говорить об алгоритмике и наличии математической базы. Минусы — вероятность случайной ошибки близка к максимальной, поскольку у вас нет никаких формальных критериев того, все ли правила грамматики вы учли при построении парсера. Очень трудоёмкий. В общем случае, не слишком легко модифицируемый и не очень гибкий, особенно, если вы не имплементировали построение АСД. Даже при длительной работе парсера вы не можете быть уверены, что он работает абсолютно корректно. Из плюс-минусов. В этом варианте все зависит от прямоты ваших рук. Рассказывать об этом варианте подробно мы не будем.
- Используем регулярные выражения! Я не буду сейчас шутить на тему количества проблем и регулярных выражений, но в целом, способ хотя и доступный, но не слишком хороший. В случае сложной грамматики работа с регулярками превратится в ад кромешный, особенно если вы попытаетесь оптимизировать правила для увеличения скорости работы. В общем, если вы выбрали этот способ, мне остается только пожелать вам удачи. Регулярные выражения не для парсинга! И пусть меня не уверяют в обратном. Они предназначены для поиска и замены. Попытка использовать их для других вещей неизбежно оборачивается потерями. С ними мы либо существенно замедляем разбор, проходя по строке много раз, либо теряем мозговые клеточки, пытаясь измыслить способ удалить гланды через задний проход. Возможно, ситуацию чуть улучшит попытка скрестить этот способ с предыдущим. Возможно, нет. В общем, плюсы почти аналогичны прошлому варианту. Только еще нужно знание регулярных выражений, причем желательно не только знать как ими пользоваться, но и иметь представление, насколько быстро работает вариант, который вы используете. Из минусов тоже примерно то же, что и в предыдущем варианте, разве что менее трудоёмко.
- Воспользуемся кучей инструментов для парсинга BNF! Вот этот вариант уже более интересный. Во-первых, нам предлагается вариант типа lex-yacc или flex-bison, во вторых во многих языках можно найти нативные библиотеки для парсинга BNF. Ключевыми словами для поиска можно взять LL, LR, BNF. Смысл в том, что все они в какой-то форме принимают на вход вариацию BNF, а LL, LR, SLR и прочее — это конкретные алгоритмы, по которым работает парсер. Чаще всего конечному пользователю не особенно интересно, какой именно алгоритм использован, хотя они имеют определенные ограничения разбора грамматики (остановимся подробнее ниже) и могут иметь разное время работы (хотя большинство заявляют O(L), где L — длина потока символов). Из плюсов — стабильный инструментарий, внятная форма записи (БНФ), адекватные оценки времени работы и наличие записи БНФ для большинства современных языков (при желании можно найти для sql, python, json, cfg, yaml, html, csv и многих других). Из минусов — не всегда очевидный и удобный интерфейс инструментов, возможно, придется что-то написать на незнакомом вам ЯП, особенности понимания грамматики разными инструментами.
- Воспользуемся инструментами для парсинга PEG! Это тоже интересный вариант, плюс, здесь несколько побогаче с библиотеками, хотя они, как правило, уже несколько другой эпохи (PEG предложен Брайаном Фордом в 2004, в то время как корни BNF тянутся в 1980-е), то есть заметно моложе и хуже выглажены и проживают в основном на github. Из плюсов — быстро, просто, часто — нативно. Из минусов — сильно зависите от реализации. Пессимистичная оценка для PEG по спецификации вроде бы O(exp(L)) (другое дело, для создания такой грамматики придется сильно постараться). Сильно зависите от наличия/отсутствия библиотеки. Почему-то многие создатели библиотек PEG считают достаточными операции токенизации и поиска/замены, и никакого вам AST и даже привязки функций к элементам грамматики. Но в целом, тема перспективная.