Контейнеризация в python. часть 1
Содержание:
- Краткое введение в ООП
- Сравнение pickle и JSON
- Usage in Python
- Создание словаря
- Special Characters in Python Print Function
- Сериализация и распаковка нестандартных объектов
- A note on `range`
- Python print() function
- How to Print a simple String in Python?
- How to print blank lines
- Print end command
- Examples
- Словари
- Использование модуля
- Conversion Types in Python Print function
- Операции над словарями Python
- Производительность
- Распаковка
- Погружене в f-строки
- Создание класса в Python:
- Основные операторы
- Python print String Format
- Что можно сериализовать?
- Встроенные функции
- Операционная система
- Заключение
Краткое введение в ООП
Объектно-ориентированное программирование (ООП) – технология разработки сложного программного обеспечения, в которой программа строится в виде совокупности объектов и их взаимосвязей.
Объединение данных и действий, производимых над этими данными, в единое целое, которое называется объектом – является одним из основных принципов ООП.
Основными понятиями являются понятие класса и объекта.
Класс является типом данных, определяемым пользователем и представляет собой структуру в виде данных и методов для работы с данными.
Формально Класс — это шаблон, по которому будет сделан объект.
Объект является экземпляром класса. Объект и экземпляр - это одно и то же.
Вот пример. Форма для изготовления печенья – это класс, а само печенье это объект или экземпляр класса, т.е. это конкретное изделие. Печенье имеет размеры, цвет, состав – это атрибуты класса. Также в классе описываются методы, которые предназначены для чтения или изменения данных объекта.
В Python характеристики объекта, называются атрибутами, а действия, которые мы можем проделывать с объектами, — методами. Методами в Python называют функции, которые определяются внутри класса.
Объект = атрибуты + методы
Сравнение pickle и JSON
Возможно, вы слышали о JSON (нотация объектов JavaScript), который является популярным форматом, который также позволяет разработчикам сохранять и передавать объекты, закодированные в виде строк. Этот метод сериализации имеет некоторые преимущества перед сохранением. Формат JSON удобочитаем, не зависит от языка и быстрее, чем pickle.
Однако у него есть и некоторые важные ограничения
Что наиболее важно, по умолчанию только ограниченное подмножество встроенных типов Python может быть представлено JSON. С помощью Pickle мы можем легко сериализовать очень широкий спектр типов Python и, что важно, настраиваемые классы
Это означает, что нам не нужно создавать настраиваемую схему (как мы делаем для JSON) и писать сериализаторы и парсеры, подверженные ошибкам. С Pickle вся тяжелая работа будет сделана за вас.
Usage in Python
When do I use for loops?
for loops are traditionally used when you have a block of code which you want to repeat a fixed number of times. The Python for statement iterates over the members of a sequence in order, executing the block each time. Contrast the for statement with the »while» loop, used when a condition needs to be checked each iteration, or to repeat a block of code forever. For example:
For loop from 0 to 2, therefore running 3 times.
for x in range(0, 3):
print("We're on time %d" % (x))
While loop from 1 to infinity, therefore running forever.
x = 1
while True:
print("To infinity and beyond! We're getting close, on %d now!" % (x))
x += 1
As you can see, these loop constructs serve different purposes. The for loop runs for a fixed amount — in this case, 3, while the while loop runs until the loop condition changes; in this example, the condition is the boolean True which will never change, so it could theoretically run forever. You could use a for loop with a huge number in order to gain the same effect as a while loop, but what’s the point of doing that when you have a construct that already exists? As the old saying goes, «why try to reinvent the wheel?».
How do they work?
If you’ve done any programming before, you have undoubtedly come across a for loop or an equivalent to it. Many languages have conditions in the syntax of their for loop, such as a relational expression to determine if the loop is done, and an increment expression to determine the next loop value. In Python this is controlled instead by generating the appropriate sequence. Basically, any object with an iterable method can be used in a for loop. Even strings, despite not having an iterable method — but we’ll not get on to that here. Having an iterable method basically means that the data can be presented in list form, where there are multiple values in an orderly fashion. You can define your own iterables by creating an object with next() and iter() methods. This means that you’ll rarely be dealing with raw numbers when it comes to for loops in Python — great for just about anyone!
Nested loops
When you have a block of code you want to run x number of times, then a block of code within that code which you want to run y number of times, you use what is known as a «nested loop». In Python, these are heavily used whenever someone has a list of lists — an iterable object within an iterable object.
for x in range(1, 11):
for y in range(1, 11):
print('%d * %d = %d' % (x, y, x*y))
Early exits
Like the while loop, the for loop can be made to exit before the given object is finished. This is done using the break statement, which will immediately drop out of the loop and contine execution at the first statement after the block. You can also have an optional else clause, which will run should the for loop exit cleanly — that is, without breaking.
for x in range(3):
if x == 1:
break
Создание словаря
Пустой словарь можно создать при помощи функции или
пустой пары фигурных скобок (вот почему фигурные скобки
нельзя использовать для создания пустого множества). Для создания словаря
с некоторым набором начальных значений можно использовать следующие конструкции:
Capitals = {'Russia': 'Moscow', 'Ukraine': 'Kiev', 'USA': 'Washington'}
Capitals = dict(Russia = 'Moscow', Ukraine = 'Kiev', USA = 'Washington')
Capitals = dict()
Capitals = dict(zip(, ))
print(Capitals)
Первые два способа можно использовать только для создания небольших словарей, перечисляя все их элементы.
Кроме того, во втором способе ключи передаются как именованные параметры функции , поэтому
в этом случае ключи могут быть только строками, причем являющимися корректными идентификаторами.
В третьем и четвертом случае можно создавать большие словари, если в качестве аргументов
передавать уже готовые списки, которые могут быть получены не обязательно перечислением всех элементов,
а любым другим способом построены по ходу исполнения программы. В третьем способе
функции нужно передать список, каждый элемент которого является кортежем
из двух элементов: ключа и значения. В четвертом способе используется функция ,
которой передаются два списка одинаковой длины: список ключей и список значений.
Special Characters in Python Print Function
The Python programming language allows you to use special characters by using escape characters. For example, within s1 (‘Hi there, \ “How are You?\”‘), we used \ character to escape double quotes within the print statement. Next, we used \ to escape ‘(single quote) in print (‘I Can\’t Do that’).
print function with special Characters output
The first print statement returns three new lines. And the last statement prints 5 new lines.
This print function example is the same as the above — however, this time, we used three empty lines in between the two strings Hi and Hello.
print function with empty lines output
In this example, we are using the New Line, Horizontal Tab, Vertical Tab, etc., in between a string to show you how they alter the output. For example, the first statement with \n prints Hi there, in the first line and How are You? in the next line.
print function with New Line, Horizontal Tab, and Vertical Tab output
Сериализация и распаковка нестандартных объектов
Как я упоминал ранее, используя Pickle, вы можете сериализовать свои собственные настраиваемые объекты. Взгляните на следующий пример:
import pickle
class Veggy():
def __init__(self):
self.color = ''
def set_color(self, color):
self.color = color
cucumber = Veggy()
cucumber.set_color('green')
with open('test_pickle.pkl', 'wb') as pickle_out:
pickle.dump(cucumber, pickle_out)
with open('test_pickle.pkl', 'rb') as pickle_in:
unpickled_cucumber = pickle.load(pickle_in)
print(unpickled_cucumber.color)
Как видите, этот пример почти такой же простой, как и предыдущий. Между строками 3 и 7 мы определяем простой класс, который содержит один атрибут и один метод, который изменяет этот атрибут. В строке 9 мы создаем экземпляр этого класса и сохраняем его в переменной cucumber, а в строке 10 мы устанавливаем цвет его атрибута на «зеленый».
Затем, используя те же функции, что и в предыдущем примере, мы сериализуем и отделяем наш только что созданный объект. Выполнение приведенного выше кода приводит к следующему выводу:
$ python unpickle_custom.py green
Помните, что мы можем распаковать объект только в среде, где класс Veggy либо определен, либо импортирован. Если мы создадим новый скрипт и попытаемся выделить объект без импорта класса Veggy, мы получим «AttributeError». Например, выполните следующий скрипт:
import pickle
with open('test_pickle.pkl', 'rb') as pickle_in:
unpickled_cucumber = pickle.load(pickle_in)
print(unpickled_cucumber.color)
В выводе приведенного выше скрипта вы увидите следующую ошибку:
$ python unpickle_simple.py
Traceback (most recent call last):
File "<pyshell#40>", line 2, in <module>
unpickled_cucumber = pickle.load(pickle_in)
AttributeError: Can't get attribute 'Veggy' on <module '__main__' (built-in)>
A note on `range`
The function is seen so often in for statements that you might think range is part of the for syntax. It is not: it is a Python built-in function which returns a sequence following a specific pattern (most often sequential integers), which thus meets the requirement of providing a sequence for the for statement to iterate over. Since for can operate directly on sequences, and there is often no need to count. This is a common beginner construct (if they are coming from another language with different loop syntax):
mylist =
for i in range(len(mylist)):
# do something with mylist
It can be replaced with this:
mylist =
for v in mylist:
# do something with v
Consider for var in range(len(something)): to be a flag for possibly non-optimal Python coding.
Python print() function
The print() function in Python is used to print a specified message on the screen. The print command in Python prints strings or objects which are converted to a string while printing on a screen.
Syntax:
print(object(s))
How to Print a simple String in Python?
More often then not you require to Print strings in your coding construct.
Here is how to print statement in Python 3:
Example: 1
To print the Welcome to Guru99, use the Python print statement as follows:
print ("Welcome to Guru99")
Output:
Welcome to Guru99
In Python 2, same example will look like
print "Welcome to Guru99"
Example 2:
If you want to print the name of five countries, you can write:
print("USA")
print("Canada")
print("Germany")
print("France")
print("Japan")
Output:
USA Canada Germany France Japan
How to print blank lines
Sometimes you need to print one blank line in your Python program. Following is an example to perform this task using Python print format.
Example:
Let us print 8 blank lines. You can type:
print (8 * "\n")
or:
print ("\n\n\n\n\n\n\n\n\n")
Here is the code
print ("Welcome to Guru99")
print (8 * "\n")
print ("Welcome to Guru99")
Output
Welcome to Guru99 Welcome to Guru99
Print end command
By default, print function in Python ends with a newline. This function comes with a parameter called ‘end.’ The default value of this parameter is ‘\n,’ i.e., the new line character. You can end a print statement with any character or string using this parameter. This is available in only in Python 3+
Example 1:
print ("Welcome to", end = ' ')
print ("Guru99", end = '!')
Output:
Welcome to Guru99!
Example 2:
# ends the output with ‘@.’
print("Python" , end = '@')
Output:
Python@
Examples
For..Else
for x in range(3):
print(x)
else:
print('Final x = %d' % (x))
Strings as an iterable
string = "Hello World"
for x in string:
print(x)
Lists as an iterable
collection =
for x in collection:
print(x)
Loop over Lists of lists
list_of_lists = , , ]
for list in list_of_lists:
for x in list:
print(x)
Creating your own iterable
class Iterable(object):
def __init__(self,values):
self.values = values
self.location = 0
def __iter__(self):
return self
def next(self):
if self.location == len(self.values):
raise StopIteration
value = self.values
self.location += 1
return value
Your own range generator using yield
def my_range(start, end, step):
while start <= end:
yield start
start += step
for x in my_range(1, 10, 0.5):
print(x)
Словари
Словарь Python, по большей части, представляет собой хэш-таблицу. В некоторых языках, словари могут упоминаться как ассоциативная память, или ассоциативные массивы. Они индексируются при помощи ключей, которые могут быть любого неизменяемого типа. Например, строка или число могут быть ключом. Вам обязательно стоит запомнить тот факт, что словарь – это неупорядоченный набор пар ключ:значение, и ключи обязательно должны быть уникальными.
Вы можете получить список ключей путем вызова метода keys() в том или ином словаря. Чтобы проверить, присутствует ли ключ в словаре, вы можете использовать ключ in в Python. В некоторых старых версиях Python (с 2.3 и более ранних, если быть точным), вы увидите ключевое слово has_key, которое используется для проверки наличия ключа в словаре. Данный ключ является устаревшим в Python 2.X, и был удален, начиная с версии 3.Х. Давайте попробуем создать наш первый словарь:
Python
my_dict = {}
another_dict = dict()
my_other_dict = {«one»:1, «two»:2, «three»:3}
print(my_other_dict) # {‘three’: 3, ‘two’: 2, ‘one’: 1}
|
1 2 3 4 5 |
my_dict={} another_dict=dict() my_other_dict={«one»1,»two»2,»three»3} print(my_other_dict)# {‘three’: 3, ‘two’: 2, ‘one’: 1} |
Первые два примера показывают, как создавать пустой словарь. Все словари находятся в фигурных скобках. Последняя строчка показывает, что мы имеем в виду, когда говорим «неупорядоченный словарь». Теперь настало время узнать, как принимаются значения в словаре.
Python
my_other_dict = {«one»:1, «two»:2, «three»:3}
print(my_other_dict) # 1
my_dict = {«name»:»Mike», «address»:»123 Happy Way»}
print(my_dict) # ‘Mike’
|
1 2 3 4 5 6 |
my_other_dict={«one»1,»two»2,»three»3} print(my_other_dict»one»)# 1 my_dict={«name»»Mike»,»address»»123 Happy Way»} print(my_dict»name»)# ‘Mike’ |
В первом примере, мы использовали словарь из предыдущего примере, и вытащили значение, связанное с ключом под названием one. Второй пример демонстрирует, как задавать значение ключу name. Теперь попробуем узнать, находится ли ключ в словаре или нет:
Python
print(«name» in my_dict) # True
print(«state» in my_dict) # False
|
1 2 3 |
print(«name»inmy_dict)# True print(«state»inmy_dict)# False |
Что-ж, если ключ в словаре, Python выдает нам Boolean True. В противном случае, мы получаем Boolean False. Если вам нужно получить список ключей в словаре, вам нужно сделать следующее:
Python
print(my_dict.keys()) # dict_keys()
| 1 | print(my_dict.keys())# dict_keys() |
В Python 2, метод keys дает нам список. Но в Python 3 он дает объект view. Это дает разработчику возможность обновлять словарь, так что view также обновится
Обратите внимание на то, что когда мы используем ключевое слово in для текста содержимого словаря, лучше будет сделать это в словаре, а не в списке, выдаваемом методом keys. Смотрим ниже:
Python
if «name» in my_dict # Такая конструкция правильная
if «name» in my_dict.keys() # Работает но медленее
|
1 2 3 |
if»name»inmy_dict# Такая конструкция правильная if»name»inmy_dict.keys()# Работает но медленее |
Пока это, возможно, не говорит вам о многом, во время реальной работы ситуация будет другая и каждая секунда будет важна. При создании тысячи файлов для обработки, эти маленькие хитрости могут уберечь вас от бесполезной траты времени.
Использование модуля
В следующем очень простом примере показаны основы использования модуля Pickle в Python 3:
import pickle
test_list =
with open('test_pickle.pkl', 'wb') as pickle_out:
pickle.dump(test_list, pickle_out)
Во-первых, мы должны импортировать модуль pickle, что выполняется в строке 1. В строке 3 мы определяем простой список из трех элементов, который будет обработан.
В строке 5 мы указываем, что имя нашего выходного файла pickle будет test_pickle.pkl. Используя параметр wb, мы сообщаем программе, что хотим записать (w) двоичные данные (b) внутри нее (потому что мы хотим создать поток байтов)
Обратите внимание, что расширение pkl не обязательно – мы используем его в этом руководстве, потому что это расширение включено в документацию Python.
В строке 6 мы используем метод pickle.dump(), чтобы собрать наш тестовый список и сохранить его в файле test_pickle.pkl.
Я рекомендую вам попробовать открыть сгенерированный файл pickle в текстовом редакторе. Вы быстро заметите, что поток байтов определенно не является удобочитаемым форматом.
Conversion Types in Python Print function
The list of conversion types that are available in the Python print function.
- %c – Returns a Single character.
- %d – Returns a Decimal Integer
- %i – for Long integer
- %u – Returns an unsigned decimal integer
- %e, %E – Returns the floating-point value in exponential notation.
- %f – Returns the floating-point value in fixed-point notation.
- %g – Returns the shorter value of %f and %e
- %G – Returns the shorter value of %f and %E
- %c – Returns a Single character
- %o – Returns an Octal value
- %r – Generates string with repr()
- %s – Converts the value to a string using str() function.
- %x, %X – Returns the Hexadecimal integer.
Let me use all the available conversion types. For this, we declared a few variables with a numeric value, string, decimal value, and a character.
print function conversion types output
Python print file example
Here, we are opening a file pythonSample.txt (if it exists). Otherwise, it creates that text file in the default directory. Next, the print function prints the statement inside that text file.
Операции над словарями Python
Если словарь, содержащий полный набор данных, большой, то разумнее использовать список lowscores, который мы только что скомпилировали, чтобы создать совершенно новый словарь (Python список в словарь). Преимущество этого приема заключается в том, что для дальнейшего анализа не нужно хранить в памяти большой словарь. Можно просто перейти к соответствующему подмножеству исходных данных.
Во-первых, мы используем ключи, хранящиеся в lowscores, для создания нового словаря. Чтобы сделать это, есть два способа: первый — извлекаем только соответствующие элементы из исходного словаря с помощью метода .get(), оставляя исходный словарь без изменений. Второй — использовать метод .pop(), который удаляет извлеченные записи из исходного словаря.
Код для подмножества может выглядеть следующим образом: subset = dict(). Такое написание может показаться незнакомым, потому что цикл задан одной строкой кода. Этот стиль называется «генерацией словаря». На самом деле это цикл for, который перебирает элементы lowscores, извлекает значения из отзывов и использует их для заполнения нового словаря.
Вы можете сравнить традиционный стиль с использованием цикла и генерацию словаря и убедиться, что они действительно дают идентичный результат:
# Метод с использованием цикла for для создания подмножества словаря
forloop = {}
for k in lowscores:
forloop = reviews
# Добавляем специальный метод извлечения релевантных элементов из словаря `reviews`
dictcomp = {k : reviews.___(k) for k in lowscores}
# Удостоверимся, что эти объекты аналогичны
print(forloop == ________)
Предположим, что теперь вы хотите изменить словарь Python 3, чтобы оценки выступали в качестве ключей словаря, а не идентификаторов. Можно использовать для этого цикл for, указав как ключи, так и значения, и создав новый вложенный словарь. Нужно будет извлечь «score» из исходного вложенного словаря, чтобы использовать его в качестве нового ключа.
Чтобы упростить код, мы создаем в отдельной строке новый вложенный словарь как новый объект newvalues. После чего заполняем scoredict идентификаторами в качестве ключей и объектами из словаря newvalues в качестве значений:
from collections import defaultdict
scoredict = defaultdict(list)
for key, value in reviews.items():
newvalues = {'id' : key, "title" : value, "review" : value}
# Используем 'score' из значений (!) из исходного словаря в качестве ключей для только что созданного словаря
scoredict].append(newvalues)
# Выводим ключи словаря, чтобы удостовериться, что это на самом деле оценки из отзывов
print(scoredict.keys())
Производительность
F-строки не только гибкие, но и быстрые. И для сравнения производительности разных подходов к форматированию я подготовил два шаблона:
- простой, в который нужно вставить всего два значения: строку и число;
- сложный, данные для которого собираются из разных переменных, а внутри происходит преобразование даты, вещественного числа, а также округление.
Финальная простая строка получается такой:
Сложная строка на выходе такая:
Далее я написал 5 функций, каждая из которых возвращает строку отформатированную одним из способом, а после запустил каждую функцию много раз. Пример всех функций и тестового скрипта можете скачать тут.
После недолгого тестирования я получил следующие результаты:
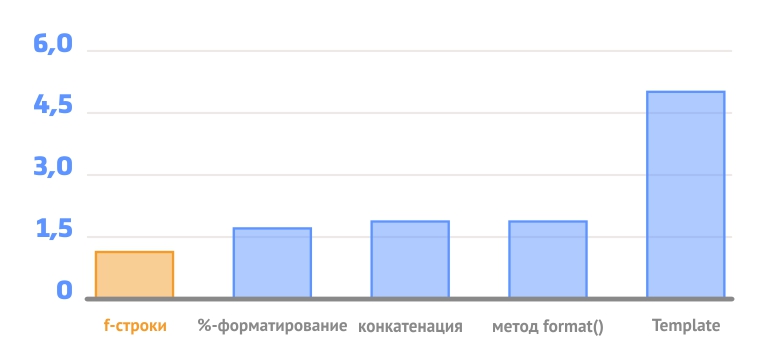
На простых примерах f-строки показывают самые лучшие результаты.На 25% быстрее %-форматирования и метода format().
Распаковка
Теперь давайте раскроем содержимое тестового файла pickle и вернем наш объект к его исходной форме.
import pickle
with open('test_pickle.pkl', 'rb') as pickle_in:
unpickled_list = pickle.load(pickle_in)
print(unpickled_list)
Как видите, эта процедура не сложнее, чем когда мы мариновали объект. В строке 3 мы снова открываем наш файл test_pickle.pkl, но на этот раз наша цель – прочитать (r) двоичные данные (b), хранящиеся в нем.
Затем, в строке 5, мы используем метод pickle.load(), чтобы распаковать наш список и сохранить его в переменной unpickled_list.
Затем вы можете распечатать содержимое списка, чтобы убедиться, что он идентичен списку, который мы выбрали в предыдущем примере. Вот результат выполнения приведенного выше кода:
$ python unpickle.py
Погружене в f-строки
f-строки делают очень простую вещь — они берут значения переменных, которые есть в текущей области видимости, и подставляют их в строку. В самой строке вам лишь нужно указать имя этой переменной в фигурных скобках.
f-строки также поддерживают расширенное форматирование чисел:
С помощью f-строк можно форматировать дату без вызова метода strftime():
Они поддерживают базовые арифметические операции. Да, прямо в строках:
Позволяют обращаться к значениям списков по индексу:
А также к элементам словаря по ключу:
Причем вы можете использовать как строковые, так и числовые ключи. Точно также как в обычном Python коде:
Вы можете вызывать в f-строках методы объектов:
А также вызывать функции:
f-строки очень гибкий и мощный инструмент для создания самых разнообразных шаблонов.
Со всеми возможностя f-строк вы можете ознакомится в PEP498.
Создание класса в Python:
Определение класса начинается с ключевого слова class, после него следует имя класса и двоеточие.
class имя_класса: # тело класса # объявление конструктора # объявление атрибутов # объявление методов
Основные определения
Метод __init__ или Конструктор
В процессе создания объекта атрибутам класса необходимо задать начальные значения
Это действие называется инициализацией. Для этой цели используется специальный метод __init__(), который называется методом инициализации или конструктором. Метод __init__ запускается при создании экземпляра класса — один раз. Обратите внимание на двойные подчёркивания в начале и в конце имени. Синтаксис метода следующий:
def __init__(self, параметр1, параметр2):self.атрибут1 = параметр1 self.атрибут2 = параметр2
Два символа подчеркивания в начале __init__ и два символа подчеркивания в конце обязательны. Параметров у конструктора параметр1, параметр2 может быть сколько угодно, но первым дожен быть параметр self.
Основные операторы
Оператор
Краткое описание
+
Сложение (сумма x и y)
—
Вычитание (разность x и y)
*
Умножение (произведение x и y)
Деление
Внимание! Если x и y целые, то результат всегда будет целым числом! Для получения вещественного результата хотя бы одно из чисел должно быть вещественным. Пример: 40/5 → 8, а вот 40/5.0 → 8.0
=
Присвоение
+=
y+=x; эквивалентно y = y + x;
-=
y-=x; эквивалентно y = y — x;
*=
y*=x; эквивалентно y = y * x;
/=
y/=x; эквивалентно y = y / x;
%=
y%=x; эквивалентно y = y % x;
==
Равно
!=
не равно
>
Больше
=
больше или равно
Часть после запятой отбрасывается
4 // 3 в результате будет 125 // 6 в результате будет 4
**
Возведение в степень
5 ** 2 в результате будет 25
and
логическое И
or
логическое ИЛИ
not
логическое отрицание НЕ
Python print String Format
We are using the print function along with conversion types. Within the first print statement, we used two %s in between a string follows by a tuple with variables. It means print function replace those two %s items with those tuple values.
Here, Python print function uses the same order that we specified. I mean, first, %s is replaced by a person variable, and the second %s replaced by name variable value. Here, print(person +’ is working at ‘+ name) statement is to concat three items.
print function and string formatting output
Python print format Example
It is an example of a Python print format function. In this example, we are using the format function inside the print function. It allows us to format values. I suggest you refer to the Python format Function article.
print and format functions output
Что можно сериализовать?
Следующие типы можно сериализовать и десериализовать с помощью модуля Pickle:
- Все собственные типы данных, поддерживаемые Python (логические, None, целые числа, числа с плавающей запятой, комплексные числа, строки, байты, байтовые массивы).
- Словари, наборы, списки и кортежи – если они содержат выбираемые объекты.
- Функции и классы, определенные на верхнем уровне модуля.
Важно помнить, что травление не является независимым от языка методом сериализации, поэтому ваши консервированные данные могут быть извлечены только с помощью Python. Более того, важно убедиться, что объекты обрабатываются с использованием той же версии Python, которая будет использоваться для их выделения
В этом случае смешивание версий может вызвать множество проблем.
Кроме того, функции выбираются по ссылкам на их имена, а не по их значениям. Полученный в результате Pickling не содержит информации о коде или атрибутах функции. Следовательно, вы должны убедиться, что среда, в которой функция не выбрана, может импортировать функцию. Другими словами, если мы выберем функцию, а затем удалим ее в среде, где она либо не определена, либо не импортирована, возникнет исключение.
Также очень важно отметить, что маринованные предметы могут использоваться специально. Например, извлечение данных из ненадежного источника может привести к выполнению вредоносного кода.
Встроенные функции
print (x, sep = 'y') печатает x объектов, разделенных y
len (x) возвращает длину x (s, L или D)
min (L ) возвращает минимальное значение в L
max (L) возвращает максимальное значение в L
sum (L) возвращает сумму значений в диапазоне L
range(n1,n2,n) (n1, n2, n) возвращает последовательность чисел от n1 до n2 с шагом n
abs (n) возвращает абсолютное значение n
round (n1, n) возвращает число n1, округленное до n цифр
type (x) возвращает тип x (string, float, list, dict…)
str (x) преобразует x в string
list (x) преобразует x в список
int (x) преобразует x в целое число
float (x) преобразует x в число с плавающей запятой
help (s) печатает справку о x
map (function, L) Применяет функцию к значениям в L
Операционная система
Обратите внимание, что в первую очередь нам нужно импортировать модуль OS в нашу программу, только тогда мы можем выполнять любую из его функций

os.name
Эта функция дает имя импортируемого модуля OS. Это зависит от базовой операционной системы. В настоящее время он регистрирует «posix», «os2», «ce», «nt», «riscos» и «java».
Выполним это в системе:
>>> print(os.name) posix
Понятно, что это может выводить разные платформы на основе интерпретатора.
os.environ
Environ – это не функция, а параметр процесса, через который мы можем получить доступ к переменным среды системы.
import os output = os.environ print(output)
Когда мы запустим этот скрипт, на выходе будет следующее:

os.execvp
execvp функция – это один из способов запуска других команд в системе. Давайте посмотрим на фрагмент кода для этой функции:
import os program = "python" arguments = print(os.execvp(program, (program,) + tuple(arguments)))
Давайте посмотрим на фрагмент кода hello.py:
print('Hello')
Когда мы запустим этот скрипт, на выходе будет следующее:

os.getuid
Эта функция модуля os возвращает идентификатор пользователя или UID текущего процесса, как это известно в народе.
>>> os.getuid() 501
Эта функция модуля os возвращает идентификатор пользователя текущего процесса или UID, как это известно в народе.
Итак, текущий идентификатор процесса оболочки – 501.
os.rename
С помощью функции rename мы можем легко переименовать файл.
import os fileDir = "JournalDev.txt" os.rename(fd,'JournalDev_Hi.txt')
Обратите внимание, что для этого мы должны предоставить правильные разрешения нашему скрипту
os.system
Системная функция os позволяет нам запускать команду в скрипте Python, как если бы я запускал ее в своей оболочке. Например:
import os
currentFiles = os.system("users > users.txt")
Когда я запустил этот скрипт, в том же каталоге был создан новый файл с именем users.txt и строкой содержимого как ‘shubham’, так как он также возвращается исходной оболочкой:

Обратите внимание, что это очень мощная команда, и ее следует использовать с осторожностью
os.error
Класс ошибок модуля os – это базовый класс для ошибок, связанных с вводом-выводом. Таким образом, мы можем отлавливать ошибки ввода-вывода, используя OSError в предложении except.
import os
try:
f = open('abc.txt', 'r') # file is missing
except OSError:
print('Error')
os.getpid
Эта функция возвращает текущий идентификатор процесса или PID, как это известно в народе.
>>> os.getpid() 71622
Итак, идентификатор пользователя текущего процесса оболочки – 71622.
os.listdir
Эта функция просто выводит список файлов и каталогов, имеющихся в текущем рабочем каталоге.
>>> import os >>> os.listdir()
Он возвращает повторяющийся список имен каталогов и файлов.
os.uname
Эта функция возвращает информацию, которая определяет текущую операционную систему, в которой она выполняется.
>>> os.uname() posix.uname_result(sysname='Darwin', nodename='Shubham.local', release='17.2.0', version='Darwin Kernel Version 17.2.0: Fri Sep 29 18:27:05 PDT 2017; root:xnu-4570.20.62~3/RELEASE_X86_64', machine='x86_64')
Сравнение import os.path и os
os.path странно работает на самом деле. Похоже, что в os комплекте идет подмодуль path, но на самом деле это обычный модуль, с которым работает sys.module для поддержки os.path. Перечислим, что происходит:
- Когда Python запускается, он загружает множество модулей в sys.module.
- Модуль os также загружается при запуске Python. Он назначает свой путь специфическому атрибуту модуля os.
- Он вводит sys.modules = path, чтобы вы могли импортировать os.path, как если бы это был подмодуль.
Заключение
Как видите, благодаря модулю Pickle сериализация объектов Python довольно проста. В наших примерах мы выбрали простой список, но вы можете использовать тот же метод для сохранения большого спектра типов данных Python, если вы убедитесь, что ваши объекты содержат только другие выбираемые объекты.
У Pickling есть некоторые недостатки, самый большой из которых может заключаться в том, что вы можете распаковать свои данные только с помощью Python – если вам нужно кросс-языковое решение, JSON определенно лучший вариант. И, наконец, помните, что сериализованные объекты можно использовать для переноса кода, который вы не обязательно хотите выполнять.