Осваиваем python 3 — работа с файлами
Содержание:
- Исключения в Python
- Инструменты и библиотеки
- Считываем бинарный файл со строковыми данными в массив
- Использование модуля requests
- Извлечение текста с помощью PyMuPDF
- Использование модуля urllib.request
- 3: Чтение файла
- Извлечение текста с помощью PyPDF2
- Виртуальная среда под проекты
- 2: Открытие файла
- Открытие и чтение текстового файла
- Способ 1
- The read() Method
- Открытие файлов в Python
- Модуль PyYAML¶
- Указываем путь к файлу правильно!
- 2.1. Запись в пустой файл в Python
Исключения в Python
При выполнении программ могут возникать ошибки, для управления ими Python использует специальные объекты, называемые исключениями. Когда в программу включен код обработки исключения, ваша программа продолжится, а если нет, то программа остановится и выведет трассировку с отчетом об исключении. Исключения обрабатываются в блоках try-except. С блоками try-except программы будут работать даже в том случае, если что-то пошло не так.
3.1. Блоки try-except на Python
Приведем пример простой ошибки деления на ноль:
print(7/0)
Traceback (most recent call last):
File «example.py», line 1, in <module>
print(7/0)
ZeroDivisionError: division by zero
Если в вашей программе возможно появление ошибки, то вы можете заранее написать блок try-except для обработки данного исключения. Приведем пример обработки ошибки ZeroDivisionError с помощью блока try-except:
try:
print(7/0)except ZeroDivisionError:
print(«Деление на ноль запрещено»)
Команда print(7/0) помещена в блок try. Если код в блоке try выполняется успешно, то Python пропускает блок except. Если же код в блоке try создал ошибку, то Python ищет блок except и запускает код в этом блоке. В нашем случае в блоке except выводится сообщение «Деление на ноль запрещено». При выполнение этого кода пользователь увидит понятное сообщение:
Деление на ноль запрещено
Если за кодом try-except следует другой код, то Python продолжит выполнение программы.
3.2. Блок try-except-else на Python
Напишем простой калькулятор, который запрашивает данные у пользователя, а затем результат деления выводит на экран. Сразу заключим возможную ошибку деления на ноль ZeroDivisionError и добавим блок else при успешном выполнение блока try.
:
first_number = («Введите первое число: «)
first_number == ‘q’:
second_number = («Введите второе число: «)
second_number == ‘q’:
try:
a = (first_number) / (second_number)
except ZeroDivisionError:
print(«Деление на ноль запрещено»)
else:
print(«Частное двух чисел равно {a}»)
Программа запрашивает у пользователя первое число (first_number), затем второе (second_number). Если пользователь не ввел » q » для завершения работы программа продолжается. В блок try помещаем код, в котором возможно появление ошибки. В случае отсутствия ошибки деления, выполняется код else и Python выводит результат на экран. В случае ошибки ZeroDivisionError выполняется блок except и выводится сообщение о запрете деления на ноль, а программа продолжит свое выполнение. Запустив код получим такие результаты:
Введите первое число: 30
Введите второе число: 5Частное двух чисел равно 6.0
Введите первое число: 7
Введите второе число: Деление на ноль запрещено
Введите первое число: q
В результате действие программы при появлении ошибки не прервалось.
3.3. Блок try-except с текстовыми файлами на Python
Одна из стандартных проблем при работе с файлами, это отсутствие необходимого файла, или файл находится в другом месте и Python не может его найти. Попробуем прочитать не существующий файл:
filename = ‘alice_2.txt’
with open(filename, encoding=’utf-8′) as file:
contents = file.read()
Так как такого файла не существует, Python выдает исключение:
Traceback (most recent call last):
File «example.py», line 3, in <module>
with open(filename, encoding=’utf-8′) as file:
FileNotFoundError: No such file or directory: ‘alice_2.txt’
FileNotFoundError — это ошибка отсутствия запрашиваемого файла. С помощью блока try-except обработаем ее:
filename = ‘alice_2.txt’
try:
with open(filename, encoding=’utf-8′) as file:
contents = file.read()except FileNotFoundError:
print(«Запрашиваемый файл {filename } не найден»)
В результате при отсутствии файла мы получим:
Запрашиваемый файл alice_2.txt не найден
3.4. Ошибки без уведомления пользователя
В предыдущих примерах мы сообщали пользователю об ошибках. В Python есть возможность обработать ошибку и не сообщать пользователю о ней и продолжить выполнение программы дальше. Для этого блок try пишется, как и обычно, а в блоке except вы прописываете Python не предпринимать никаких действий с помощью команды pass. Приведем пример ошибки без уведомления:
ilename = ‘alice_2.txt’
try:
with open(filename, encoding=’utf-8′) as file:
contents = file.read()except FileNotFoundError:
pass
В результате при запуске этой программы и отсутствия запрашиваемого файла ничего не произойдет.
Please enable JavaScript to view the comments powered by Disqus.
Инструменты и библиотеки
Спектр доступных решений для связанных с Python инструментов, модулей и библиотек PDF немного сбивает с толку. Требуется время, чтобы понять, что к чему и какие проекты постоянно поддерживаются. Наше исследование позволило отобрать тех кандидатов, которые соответствуют современным требованиям:
- — библиотека для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц и добавления водяных знаков. PyPDF2 поддерживает как незашифрованные, так и зашифрованные документы.
- — позиционируется как «быстрая и удобная библиотека чистого PDF» и реализована как оболочка для PDFMiner, и . Основная идея заключается в том, чтобы «надежно извлекать данные из наборов PDF‑файлов, используя как можно меньше кода».
- — расширение библиотеки , которое позволяет анализировать и конвертировать PDF‑документы. Не следует его путать с с таким же именем.
- — амбициозная промышленная библиотека, в основном ориентированная на оздание высококачественных PDF‑документов. Доступны как свободная версия с открытым исходным кодом, так и коммерческая, улучшенная, версия ReportLab PLUS.
- — чистый анализатор PDF на основе Python для чтения и записи PDF. Он точно воспроизводит векторные форматы без растеризации. Вместе с ReportLab он помогает повторно использовать части существующих PDF‑файлов в новых PDF‑файлах, созданных с помощью ReportLab.
В своём исследовании мы учитывали мнения Github-сообщества, а именно:
- Звёзды Github: общее количество звезд проекта, выставленных пользователям.
- Релизы Github: количество релизов каждого проекта, что отражает активность работы над проектом и его зрелость.
- Fork-и Github: количество, сделанных копий каждого проекта, что показывает популярность использования проекта в собственных работах.
| Библиотека | Использование | Github | ReleasesGithub | Github |
|---|---|---|---|---|
| Чтение | 2 972 | 10 | 751 | |
| Чтение | 474 | 59 | 111 | |
| Чтение | 20 | 4 | ||
| Чтение | 85 | 69 | ||
| Чтение | 971 | 23 | 200 | |
| Чтение | 1 599 | 11 | 1 400 | |
| Чтение | 477 | 1 | 70 | |
| Чтение, Запись/Создание | 1 145 | 4 | 187 | |
| Запись/Создание | 31 | 48 | 22 | |
| Запись/Создание | 23 | 26 | 7 | |
| Запись/Создание | 457 | 7 | 174 |
Читать это руководство, не прорабатывая приведённые в нём примеры, бессмысленно. Поэтому, вооружимся и воспользуемся менеджером пакетов или pip3 для установки PyPDF2 и PyMuPDF. Наберём в командной строке (Windows):
pip3 install pypdf2 pip3 install pymupdf
Для того, что бы не запутаться создадим папочку для своего проекта. Как видите местом для неё выбрана папка «Документы» стандартной установки Windows. Вот так это выглядит в Windows
Вот так это выглядит в Windows
Папки и будем использовать для записи результатов работы своих программ, а в папке храним исходные PDF‑файлы, сами скрипты будем хранить в корне. Кстати, все примеры этой серии статей о работе с PDF‑файлами есть на , откуда их можно забрать и использовать в качестве «кирпича» для своих упражнений
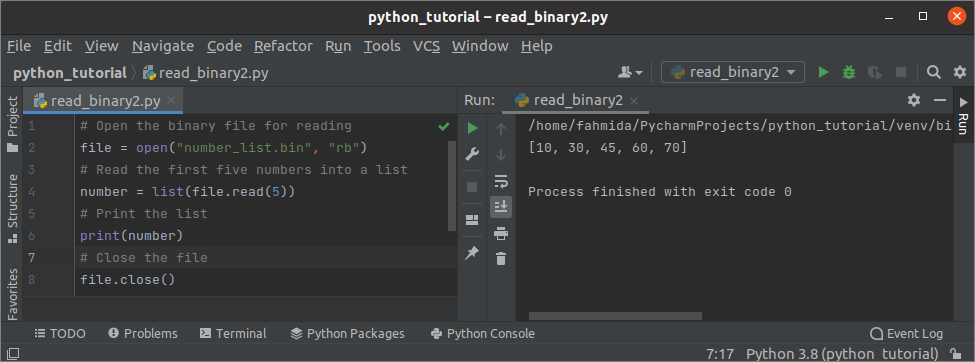
Считываем бинарный файл со строковыми данными в массив
Следующий скрипт поможет нам прочитать бинарник number_list.bin, созданный нами ранее.
# Открываем на чтение бинарный файл
file = open("number_list.bin", "rb")
# Считываем в список первые 5 элементов
number = list(file.read(5))
# Выводим список
print(number)
# Закрываем файл
file.close()
Бинарный файл содержит список с числовыми данными. Как и в предыдущем примере, функция открывает файл и читает из него данные. Затем из бинарника читаются первые 5 чисел и перед выводом объединяются в список.
Результат
После выполнения скрипта мы получим следующий результат. Бинарный файл содержит 7 чисел, первые 5 вывелись на консоль.
Использование модуля requests
Вы также можете скачивать файлы с помощью модуля requests. Метод get модуля запросов используется для загрузки содержимого файла в двоичном формате. Затем вы можете использовать метод open, чтобы открыть файл в вашей системе, как и в предыдущем методе urllib2.urlopen.
Взгляните на следующий сценарий:
import requests
print('Beginning file download with requests')
url = 'http://i3.ytimg.com/vi/J---aiyznGQ/mqdefault.jpg'
r = requests.get(url)
with open('/Users/scott/Downloads/cat3.jpg', 'wb') as f:
f.write(r.content)
# Retrieve HTTP meta-data
print(r.status_code)
print(r.headers)
print(r.encoding)
В приведенном выше скрипте метод open снова используется для записи двоичных данных в локальный файл. Если вы выполните приведенный выше сценарий и перейдете в каталог «Загрузки», вы должны увидеть только что загруженный файл JPG с именем «cat3.jpg».
С помощью модуля запросов вы также можете легко получить соответствующие метаданные о своем запросе, включая код состояния, заголовки и многое другое. В приведенном выше сценарии вы можете увидеть, как мы получаем доступ к некоторым из этих метаданных.
То же самое касается дополнительных параметров, которые требуются для HTTP-запроса GET. Например, если вам нужно добавить заголовки клиентов, все, что вам нужно сделать, это создать dict с вашими заголовками и передать его в запрос на получение:
headers = {'user-agent': 'test-app/0.0.1'}
r = requests.get(url, headers=headers)
Извлечение текста с помощью PyMuPDF
Перейдём к PyMuPDF.
Отображение информации о документе, печать количества страниц и извлечение текста из документа PDF выполняется аналогично PyPDF2 (см. скрипт ниже). Импортируемый модуль имеет имя , что соответствует имени PyMuPDF в ранних версиях.
import fitz
pdf_document = "./source/Computer-Vision-Resources.pdf"
doc = fitz.open(pdf_document)
print("Исходный документ: ", doc)
print("\nКоличество страниц: %i\n\n------------------\n\n" % doc.pageCount)
print(doc.metadata)
for current_page in range(len(doc)):
page = doc.loadPage(current_page)
page_text = page.getText("text")
print("Стр. ", current_page+1, "\n\nСодержание;\n")
print(page_text)
 Извлечение текста с помощью PyMuPDF
Извлечение текста с помощью PyMuPDF
Приятной особенностью PyMuPDF является то, что он сохраняет исходную структуру документа без изменений — целые абзацы с разрывами строк сохраняются такими же, как в PDF‑документе.
Использование модуля urllib.request
Модуль urllib.request используется для открытия или загрузки файла через HTTP. В частности, метод urlretrieve этого модуля – это то, что мы будем использовать для фактического получения файла.
Чтобы использовать этот метод, вам необходимо передать два аргумента методу urlretrieve: первый аргумент – это URL-адрес ресурса, который вы хотите получить, а второй аргумент – это путь к локальному файлу, в котором вы хотите сохранить загруженный файл.
Давайте посмотрим на следующий пример:
import urllib.request
print('Beginning file download with urllib2...')
url = 'http://i3.ytimg.com/vi/J---aiyznGQ/mqdefault.jpg'
urllib.request.urlretrieve(url, '/Users/scott/Downloads/cat.jpg')
В приведенном выше коде мы сначала импортируем модуль urllib.request. Затем мы создаем URL-адрес переменной, который содержит путь к загружаемому файлу. Наконец, мы вызываем метод urlretrieve и передаем ему переменную url в качестве первого аргумента, «/Users/scott/Downloads/cat.jpg» в качестве второго параметра для места назначения файла. Имейте в виду, что вы можете передать любое имя файла в качестве второго параметра, и это местоположение и имя, которое будет иметь ваш файл, при условии, что у вас есть правильные разрешения.
Запустите указанный выше скрипт и перейдите в каталог «Загрузки». Вы должны увидеть загруженный файл с именем «cat.jpg».
Примечание. Этот urllib.request.urlretrieve считается «устаревшим интерфейсом» в Python 3, и в какой-то момент в будущем он может стать устаревшим. Из-за этого я бы не рекомендовал использовать его в пользу одного из методов ниже. Мы включили его сюда из-за его популярности в Python 2.
3: Чтение файла
Теперь вы можете работать с файлом. В зависимости от режима, в котором открыт файл, вы можете выполнить в нём те или иные действия. Для чтения информации Python предлагает три взаимосвязанные операции.
Первая операция – <file>.read(). Она возвращает все содержимое файла в виде одной строки.
Вторая операция – <file>.readline(), которая возвращает содержимое файла построчно.
Прочитав первую строку файла, операция readline при следующем запуске выведет вторую строку.
Третья операция – <file>.readlines(), она возвращает список строк, где строки представлены в виде отдельных элементов.
Читая файлы в Python, важно помнить следующее: если файл был прочитан с помощью одной из операций чтения, его нельзя прочитать снова. К примеру, если вы запустили days_file.read(), а затем days_file.readlines(), вторая операция вернёт пустую строку
Потому нужно открывать новую переменную файла всякий раз, когда вы хотите прочитать данные из файла.
Извлечение текста с помощью PyPDF2
Начнём с . Ниже приведен скрипт, который позволяет извлечь из PDF‑файла текст и вывести него в консоль.
Сначала импортируем , помня о том, что пакет уже установлен. Задаём имя файла из папки (можете загрузить туда свой файл и поменять в скрипте на имя загруженного файла), открывает документ и получаем информацию о документе, используя метод и общее количество страниц . Далее в цикле читаем каждую страницу, получаем содержимое и печатаем в .
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов при извлекает первую страницу документа
from PyPDF2 import PdfFileReader
pdf_document = "source/Computer-Vision-Resources.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print("Количество страниц в документе: %i\n\n" % pages)
print("Мета-описание: ", info)
for i in range(pages):
page = pdf.getPage(i)
print("Стр.", i, " мета: ", page, "\n\nСодержание;\n")
print(page.extractText())
 Извлечение текста с помощью PyPDF2
Извлечение текста с помощью PyPDF2
Как видите, извлеченный текст печатается сплошным потоком. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены на странице. В основном, это зависит от внутренней структуры документа PDF и от того, как поток инструкций, создан во время его записи, поэтому их использование может привести к неожиданностям, надо дополнительно «парсить», не очень удобно.
Виртуальная среда под проекты
Язык Python удобен тем, что может взаимодействовать с разными проектами при различных настройках. Как сказал создатель протокола BitTorrent Брэм Коен:
Важно то, что инкапсуляция работает не только на уровне объектов и классов, но и в масштабах самого языка. Мы можем создавать проекты с отличающимися настройками, и они не будут друг другу «мешать». . Хорошей практикой считается активация виртуальной среды под конкретную проблему
Другими словами, устанавливать библиотеки нужно не глобально, для всей операционной системы, а для отдельного проекта. В этом помогает виртуальное окружение. Прежде чем переходить к написанию кода, нужно сформировать окружение проекта
Хорошей практикой считается активация виртуальной среды под конкретную проблему. Другими словами, устанавливать библиотеки нужно не глобально, для всей операционной системы, а для отдельного проекта. В этом помогает виртуальное окружение. Прежде чем переходить к написанию кода, нужно сформировать окружение проекта.
В Windows это делается следующим образом (в нужной папке открываем терминал и прописываем команды):
Вначале мы создаем папку виртуального окружения «.venv» (имя может быть любым), а затем активируем ее. Теперь все, что мы установим, будет связано только с данным проектом.
В UNIX-системах (Linux, MacOS) команды будут такими:
2: Открытие файла
Создайте сценарий files.py в текстовом редакторе и для простоты сохраните его в тот же каталог (/users/8host/).
Чтобы открыть файл в Python, нужно связать файл на диске с переменной Python. Сначала сообщите Python, где находится нужный файл. Чтобы открыть какой-либо файл, Python должен знать путь к этому файлу. Путь к файлу days.txt выглядит так: /users/8host/days.txt.
В файле files.py создайте переменную path и укажите в ней путь к файлу days.txt.
Теперь можно использовать функцию open(), чтобы открыть файл days.txt. В качестве первого аргумента функция open() требует путь к файлу, который нужно открыть. Эта функция имеет много других параметров. Одним из основных параметров является режим; это опциональная строка, которая позволяет выбрать режим открытия файла:
- ‘r’: открыть файл для чтения (опция по умолчанию).
- ‘w’: открыть файл для записи.
- ‘x’: создать новый файл и открыть его для записи.
- ‘a’: вставить в файл.
- ‘r+’: открыть файл для чтения и записи.
Попробуйте открыть файл для чтения. Для этого создайте переменную days_file и задайте в ней опцию open() и режим ‘r’, чтобы открыть файл days.txt только для чтения.
Открытие и чтение текстового файла
Для этого в Питоне имеются следующие конструкции:
- Функция open() – открывает документ в виде файлового объекта;
- Функция close() – закрывает файл и удаляет его из оперативной памяти;
- Контекстный менеджер with (автоматически очищает память после работы с файлом). Его синтаксис показан на рисунке ниже.
 Рисунок 1 – Синтаксис контекстного менеджера with
Рисунок 1 – Синтаксис контекстного менеджера with
- Метод read() – считывает документ полностью или частично в виде строки;
- Метод readline() – построчно выводит содержимое объекта;
- Метод readlines() – формирует из строк файла список.
В папке проекта создадим текстовый документ «econ.txt» с таким наполнением:
Писать код будем в IDE PyCharm (среду разработки скачиваем с официального сайта).
Пример кода:
Результат выполнения:
Способ 1
import os
import shutil
import glob
# перейти в папку RandomFiles
os.chdir('./RandomFiles')
# получить список файлов в папке RandomFiles
files_to_group = []
for random_file in os.listdir('.'):
files_to_group.append(random_file)
# получить все расширения имен всех файлов
file_extensions = []
for our_file in files_to_group:
file_extensions.append(os.path.splitext(our_file))
print(set(file_extensions))
file_types = set(file_extensions)
for type in file_types:
new_directory = type.replace(".", " ")
os.mkdir(new_directory) # создать папку с именем данного расширения
for fname in glob.glob(f'*.{type}'):
shutil.move(fname, new_directory)
Для этого импортируем еще две библиотеки: shutil и glob. Первая поможет перемещать файлы, а вторая – находить и систематизировать. Но обо всем по порядку.
Для начала получим список всех файлов в директории.
Здесь мы предполагаем, что у нас нет ни малейшего понятия о том, какие именно файлы лежат в этой папке. Вместо того, чтобы вписывать все расширения вручную и использовать лестницу инструкций if или switch, мы желаем, чтобы программа сама просмотрела каталог и определила, на какие типы можно разделить его содержание. Что, если бы там были файлы с десятками расширений или логи? Вы бы стали описывать их вручную?
Получив список всех
файлов, мы заходим в еще один цикл, чтобы извлечь расширения названий.
Обратите внимание на разделение строки:
os.path.splitext(our_file)
Сейчас наша переменная выглядит как-нибудь так: . Когда разделим ее, получим следующее:
`('5', '.docx')`
Мы возьмем отсюда второй элемент по индексу , то есть . Ведь по индексу у нас располагается 5.
Таким образом, у нас имеется список всех файловых расширений в папке, в том числе повторяющихся. Чтобы оставить только уникальные элементы, преобразуем его во множество. К примеру, если бы этот список состоял исключительно из , повторяющегося снова и снова, то в set остался бы всего один элемент.
# создать множество и присвоить его переменной file_types = set(file_extensions)
Заметим, что в списке типов файлов каждое расширение содержит в начале. Если мы назовем так папки на UNIX-системе, то они будут скрытыми, что не входит в наши намерения.
Поэтому, итерируя
по нашему множеству, мы заменяем точку на пустую строку. И создаем папку с полученным
названием.
new_directory = type.replace(".", " ")
# наша директория теперь будет называться "docx"
Но чтобы переместить файлы, нам все еще нужно расширение .
for fname in glob.glob(f'*.{type}')
Этим попросту отбираем все файлы, оканчивающиеся расширением . Заметьте, что в нет пробелов.
Символ подстановки обозначает, что подходит любое имя, если оно заканчивается на . Поскольку мы уже включили точку в поиск, мы используем , что значит «все после первого символа». В нашем примере это .
Что дальше?
Перемещаем любые файлы с данным расширением в директорию с тем же названием.
shutil.move(fname, new_directory)
Таким образом, как только в цикле создана папка для первого попавшегося файла с данным расширением, все последующие файлы будут отправлены в нее же. Все будет сгруппировано без повторения каталогов.
The read() Method
The read() method reads a string from an open file. It is important to note that Python strings can have binary data. apart from text data.
Syntax
fileObject.read()
Here, passed parameter is the number of bytes to be read from the opened file. This method starts reading from the beginning of the file and if count is missing, then it tries to read as much as possible, maybe until the end of file.
Example
Let’s take a file foo.txt, which we created above.
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10);
print "Read String is : ", str
# Close opend file
fo.close()
This produces the following result −
Read String is : Python is
Открытие файлов в Python
Python по умолчанию предоставляет нам функцию open(), которая предназначена для открытия файла. Рассмотрим пример использования данной функции.
file = open("text.txt") # Открытие файла
file = open("C:/text.txt") #Открытие файла по его пути
Существует несколько режимов открытия файла, r — для чтения, w — для записи, a — для добавления. По умолчанию Python использует режим чтение файла
| Режим | Описание |
| r | Открывает файл для чтения. (по умолчанию) |
| w | Открывает файл для записи. Создает новый файл, если он не существует, или усекает файл, если он существует. |
| x | Открывает файл для эксклюзивного создания. Если файл уже существует, операция завершается неудачей. |
| a | Открывает файл для добавления в конце файла без его усечения. Создает новый файл, если он не существует. |
| t | Открывается в текстовом режиме. (по умолчанию) |
| b | Открывается в двоичном режиме. |
| + | Открывает файл для обновления (чтения и записи) |
Режим открытия указывается следующим образом:
f = open("text.txt") #Режим r по умолчанию
f = open("text.txt", "w")# Режим записи в файл
f = open("text.txt", "a") # Режим добавления
Кроме того, надо учитывать кодировку файла, по умолчанию кодировка зависит от вашей операционной системы. Для Windows, кодировка cp1251, а для Linux utf — 8. Соответственно, что бы наша программа вела себя одинаково на разных платформах, лучшим решением будет указание явной кодировки.
file = open("text.txt", "r", encoding = "utf-8" )
Модуль PyYAML¶
Для работы с YAML в Python используется модуль PyYAML. Он не входит в
стандартную библиотеку модулей, поэтому его нужно установить:
pip install pyyaml
Работа с ним аналогична модулям csv и json.
Чтение из YAML
Попробуем преобразовать данные из файла YAML в объекты Python.
Файл info.yaml:
- BS 1550 IT 791 id 11 name Liverpool to_id 1 to_name LONDON - BS 1510 IT 793 id 12 name Bristol to_id 1 to_name LONDON - BS 1650 IT 892 id 14 name Coventry to_id 2 to_name Manchester
Чтение из YAML (файл yaml_read.py):
import yaml
from pprint import pprint
with open('info.yaml') as f
templates = yaml.safe_load(f)
pprint(templates)
Результат:
$ python yaml_read.py
Формат YAML очень удобен для хранения различных параметров, особенно,
если они заполняются вручную.
Запись в YAML
Запись объектов Python в YAML (файл yaml_write.py):
import yaml
trunk_template =
'switchport trunk encapsulation dot1q', 'switchport mode trunk',
'switchport trunk native vlan 999', 'switchport trunk allowed vlan'
access_template =
'switchport mode access', 'switchport access vlan',
'switchport nonegotiate', 'spanning-tree portfast',
'spanning-tree bpduguard enable'
to_yaml = {'trunk' trunk_template, 'access' access_template}
with open('sw_templates.yaml', 'w') as f
yaml.dump(to_yaml, f, default_flow_style=False)
with open('sw_templates.yaml') as f
print(f.read())
Файл sw_templates.yaml выглядит таким образом:
access - switchport mode access - switchport access vlan - switchport nonegotiate - spanning-tree portfast - spanning-tree bpduguard enable trunk - switchport trunk encapsulation dot1q - switchport mode trunk - switchport trunk native vlan 999 - switchport trunk allowed vlan
Указываем путь к файлу правильно!
Внимание! Годный вариант!
Python — умный змей, поэтому в его арсенале, начиная с 3.4 версии появился модуль pathlib, который позволяет вытворять самые приятные вещи с путями к файлу, стоит только импортировать его класс Path:
Кстати, если у вас не установлен модуль pathlib, это легко исправить с помощью команды:
Задаем относительный путь с помощью Path!
После того, как класс импортирован, мы получаем власть над слешами! Теперь вопрос о прямых и обратных слешах в разных операционных системах ложится на плечи Path. Используя Path, вы можете корректно задать относительный путь, который будет работать в разных системах.
Например, в случае расположения файлов, как на представленном изображении, относительный путь, определяемый в скрипте «main_script.py», сформируется автоматически из перечисленных в скобках составных частей. Pathlib инициализирует новый объект класса Path, содержимым которого станет сформированный для Вашей системы относительный путь (в Windows части пути будут разделены обратными слешами, в Linux — обычными):
import pathlib
from pathlib import Path
path = Path("files", "info", "docs.txt")
Задаем абсолютный путь с помощью Path
- cwd() — возвращает путь к рабочей директории
- home() — возвращает путь к домашней директории
Полученную строку, содержащую путь к рабочей или домашней директории, объединим с недостающими участками пути при инициализации объекта класса Path
Пример 1: с использованием функции cwd():
import pathlib from pathlib import Path #Получаем строку, содержащую путь к рабочей директории: dir_path = pathlib.Path.cwd() # Объединяем полученную строку с недостающими частями пути path = Path(dir_path, 'files','info', 'docs.txt')
В данном случае путь к директории имеет вид: dir_path = «/home/molodec/python», а полный путь к файлу «docs.txt» будет иметь вид: «/home/molodec/python/files/info/docs.txt».
Представленный выше код можно оптимизировать и записать в одну строку:
import pathlib from pathlib import Path path = Path(pathlib.Path.cwd(), 'files', 'info', 'docs.txt')
Пример2: с использованием функции home():
import pathlib from pathlib import Path #Получаем строку, содержащую путь к домашней директории: dir_path = pathlib.Path.home() # Объединяем полученную строку с недостающими частями пути path = Path(dir_path, 'files','info', 'docs.txt')
В данном случае путь к директории имеет вид: dir_path = «/home/molodec», а полный путь к файлу ‘docs.txt’ будет иметь вид: «/home/molodec/files/info/docs.txt».
Сократим представленный выше код:
import pathlib from pathlib import Path path = Path(pathlib.Path.home(), 'files', 'info', 'docs.txt')
2.1. Запись в пустой файл в Python
Самый простой способ сохранения данных, это записать их в файл. Чтобы записать текс в файл, требуется вызвать open() со вторым аргументом, который сообщит Python что требуется записать файл. Пример программы записи простого сообщения в файл на Python:
filename = ‘memory.txt’
with open(filename, ‘w’) as file:
file.write(«Язык программирования Python»)
Для начала определим название и тип будущего файла и сохраним в переменную filename. Затем при вызове функции open() передадим два аргумента. Первый аргумент содержит имя открываемого файла. Второй аргумент ‘ w ‘ сообщает Python, что файл должен быть открыт в режиме записи. Во второй строчке метод write() используется для записи строки в файл. Открыв файл ‘ memory.txt ‘ вы увидите в нем строку:
Язык программирования Python
Получившийся файл ничем не отличается от любых других текстовых файлах на компьютере, с ним можно делать все что угодно.
Важно: Открывая файл в режиме записи ‘ w ‘, если файл уже существует, то Python уничтожит его данные перед возвращением объекта файла. Файлы можно открывать в режимах:
Файлы можно открывать в режимах:
- чтение ‘ r ‘
- запись ‘ w ‘
- присоединение ‘ a ‘
- режим как чтения, так и записи ‘ r+ ‘