Синтез речи из текста с помощью яндекс speechkit
Содержание:
- Для чего это нужно
- Приложения для чтения книг голосом
- Краткий Обзор Решений
- Оценки Качества и Примеры Аудио
- Как настроить правильную техподдержку (helpdesk, service desk на коленке)
- Работа с файлами телефонных звонков
- Программы для озвучки текста
- Командная строка Яндекса
- Знакомство с API Yandex SpeechKit
- Вопросы
Для чего это нужно
Смысл такой: если нужно перевести аудиозапись в текст, можно это сделать очень быстро с помощью нейросетей. Яндекс в этом всяко преуспел, и мы теперь можем этим воспользоваться в своё удовольствие.
Если вы редактор или автор, вам нужно часто общаться с экспертами, чтобы получить необходимую информацию для своей работы. Можно всё конспектировать на ходу, а можно записать на диктофон и потом перевести в текст за 10 минут.
Если коллега вам оставил длинное голосовое сообщение, текст которого нужно разместить на сайте, то можно набрать всё руками или отдать эту задачу компьютеру.
Если вы студент и не хотите конспектировать лекции по гуманитарным наукам, запишите их на телефон, и нейронка переведёт их в текст. У вас будут самые полные лекции, и вся группа будет бегать за вами перед экзаменом.
В некоторых вебинарах или видео на YouTube есть классная информация, но каждый раз приходится их смотреть и перематывать, чтобы найти нужное. Выход простой: берём видео, вырезаем оттуда звук, отправляем в сервис распознавания и получаем готовый текст, с которым работать гораздо проще.
Приложения для чтения книг голосом
Чтобы выбрать лучшую программу для озвучивания текста, нужно перебрать разные варианты читалок. Каждая из этих программ получила свою аудиторию – кому-то нравится оформление, а другим универсальность и малое потребление ресурсов ПК. Прежде чем скачивать и ставить приложение на свой компьютер рекомендуют предварительно просмотреть подробную информацию по наиболее популярным.
Acapela
Речевой синтезатор, который может воспроизводить голосом текст из файлов разного формата. Пакет насчитывает больше 30 языков, среди которых присутствует и русский. Программу Acapela можно купить у разработчика – ее распространяют только на коммерческой основе. Для озвучивания книги на русском языке, пользователь может выбрать один из 2 предустановленных вариантов – устаревший мужской голос «Николай» и обновленный женский «Алена». Программу выпускают под управлением таких систем:
- Windows;
- Mac;
- Linux;
- Android;
- iOS.
Такое широкое распространение позволяет использовать Acapela любому пользователю. Сама программа не занимает много места на устройстве и устанавливается очень быстро. Для предварительной оценки, пользователи могут включить онлайн-версию приложения. Но, количество текста ограничено 300 знаками, поэтому включить книгу не получится, только краткий отрывок для проверки качества озвучки.
Ivona Reader
Программа для озвучивания текстов под управлением Windows, с реалистичным звучанием. Основной голос, который можно поставить на это приложение – «Татьяна». Может зачитывать текстовые файлы в любом формате, в том числе интернет страницы и RSS ленты. Разработчики также включили возможность преобразования текста в аудио-файл MP3 формата, поэтому книгу можно записать и сбросить на смартфон.
ICE Book Reader Professional
Программа, которая знакома пользователям компьютеров Windows уже давно. Она поддерживает большую часть текстовых форматов и проста в управлении. Для использования функции чтения и преобразования текста в аудиозапись, обязательно установить какой-либо голосовой движок. ICE Book Reader – относят к категории приложений с лицензией Freeware – ее можно получить бесплатно и пользоваться всеми функциями.
ToM Reader
https://youtube.com/watch?v=DUXBPLwXT2Q
Эта программа для компьютеров под управлением операционных систем Windows – аналог ICE Book Reader. Работает сходным образом – открывает книги в разных текстовых форматах и может озвучивать только после установки одного из голосовых движков. Для улучшения качеств воспроизведения есть возможность добавлять словари, по которым ориентируется синтезатор.
Программы, которые способны озвучивать текст голосом, становятся распространенней – при активном ритме жизни, не у каждого человека найдется время на чтение обычного буквенного формата. Но, в таких ситуациях можно не только скачивать заготовленные аудиокниги – установив читающую программу и голосовой движок, такой файл можно подготовить самостоятельно или озвучить интересующую информацию в потоковом режиме. Современное ПО синтеза речи, по звучанию приближено к реальному голосу.
Краткий Обзор Решений
Данная статья не ставит своей целью глубокий технический обзор всех доступных решений. Мы хотим просто обрисовать некий ландшафт из доступных вариантов с минимальной степенью готовности. Понятно, что мы не рассматриваем многочисленные тулкиты, а смотрим в первую очередь какие есть более-менее готовые решения с ненулевой библиотекой голосов и подобием поддержки / комьюнити:
Конкатенативные модели (появившиеся до DL бума). Из того, что хоть как-то поддерживается и живо и можно запустить «as-is» без археологических раскопок, я нашел только rhvoice (я глубоко не копал, но есть целые форумы, посвященные использованию голосов из Windows, но вряд ли это можно назвать поддерживаемым решением). На момент, когда я пользовался проектом ради интереса, он по сути был заброшен, но потом у него появился новый «хозяин». К плюсам такого рода решений можно отнести их скорость и нетребовательность к ресурсам (исключая ресурсы, чтобы заставить это работать). Очевидный и основной минус — звучит как говорилка. Менее очевидный минус — довольно тяжело оценить стоимость обладания. Качество звучания: 3+ по пятибалльной шкале;
DL-based модели в основном разделяют end-to-end TTS задачу на подзадачи: текст -> фичи и фичи -> речь (вокодинг). Практически повсеместно для первой подзадачи используется Tacotron2. Выделим следующие сочетания моделей в соответствии с их эффективностью и простотой использования:
Tacotron2 + WaveNet (оригинальный WaveNet принимал на вход лингвофичи, но для такотрона поменяли на более удобные мелспектрограммы). Основная проблема — очень медленный инференс ввиду авторегрессионности модели и необходимость запретительно большого количества ресурсов и времени. Качество звучания: 4+;
Tacotron2 + WaveRNN (тоже с переходом от лингвофичей к спектрограммам). Вокодер заметно быстрее предыдущего: при использовании всех хаков можно получить даже риалтайм синтез без GPU, правда естественность звука несколько просядет. Качество звучания: 3.5-4;
Tacotron2 + Parallel WaveNet. Упомянутый выше медленный вокодер был использован в качестве учителя для получения новой довольно быстрой параллельной модели вокодера: с ней стал возможен синтез быстрее риалтайма, но все еще на мощных GPU. Из недостатков — дистилляция требует качественную учительскую модель и соответствующую схему обучения. Качество звучания: 4+;
Tacotron2 + multi-band WaveRNN. Тоже развитие предыдущих идей, тоже распараллеливание в некотором смысле — здесь доступен синтез быстрее риалтайма уже на CPU. Однако, не слишком популярная работа, меньше имплементаций и поддержки, хотя некоторые подходы хороши и были успешно использованы в более поздних моделях; Качество звучания: 3.5-4+;
Tacotron2 + LPCNet. Интересная идея про сочетание DL и классических алгоритмов, что может дать буст по скорости до подходящего для продакшена уровня и на CPU, но требует вдумчивого допиливания для качественных результатов. Качество звучания: 3.5-4+;
Многочисленные решения на базе Tacotron2 + Waveglow от Nvidia как нынешний стандарт для задачи синтеза речи. Никто не пишет про свой «секретный соус» (например как 15.ai делает голос по 15 минутам и сколько там моделей в цепочке). Есть много имплементаций и репозиториев, которые «копируют» чужой код. Может звучать на cherry-picked примерах неотличимо от живых людей, но когда смотришь реальные модели от комьюнити, качество заметно варьируется, а детали улучшенных решений не раскрываются. Архитектурно к такотрону и его аналогам по скорости и цене обладания претензий нет, но Waveglow очень прожорлив к ресурсам как на тренировке, так и в продакшене, что делает его использование по сути нецелесообразным. Качество звучания: 3.5-4+;
Замена Tacotron2 => FastSpeech / FastSpeech 2 / FastPitch, то есть уход к более простой сетке (на базе forced-align от такотрона и миллион более хитрых и сложных вариантов). Из полезного дает контроль темпа речи и высоты голоса, что неплохо, вообще упрощает и делает более модульной конечную архитектуру
Немаловажно, что сетка перестает быть рекуррентной, что открывает просторы для оптимизаций по скорости. Качество звучания: 3.5-4+;
Оценки Качества и Примеры Аудио
Чтобы не вдаваться в дебри, мы поступили максимально просто: синтезировали аудио из валидационной выборки датасетов (~200 файлов на спикера), смешали с оригинальными аудио этой же выборки и дали группе из 24 людей для оценки качества звучания по пятибалльной шкале. Для и оценки собирали раздельно, градация оценок — — с большей детализацией для более качественного звука.
Всего было поставлено оценок. 12 человек сделали оценку полностью. Еще 12 людей успели проставить только от 10% до 75% оценок. Дальше для каждого спикера мы просто посчитали среднее (в скобочках приведено стандартное отклонение). Расчет среднего от медиан по каждому аудио завышает средние оценки на 0.1 — 0.2 балла, но не влияет на отношения. Показательны естественно скорее отношения средних баллов друг к другу. Дисперсия довольно высокая, но оценки пользователей отличались сильно и мы решили не выбрасывать никакие, т.к. оценки одного пользователя были консистентными друг с другом. По ряду соображений мы провели такую оценку только на своих уникальных голосах:
| Спикер | Оригинал | Синтез | Отношение | Примеры |
|---|---|---|---|---|
| aidar_8khz | 4.67 (.45) | 4.52 (.55) | 96.8% | link |
| baya_8khz | 4.52 (.57) | 4.25 (.76) | 94.0% | link |
| kseniya_8khz | 4.80 (.40) | 4.54 (.60) | 94.5% | link |
| aidar_16khz | 4.72 (.43) | 4.53 (.55) | 95.9% | link |
| baya_16khz | 4.59 (.55) | 4.18 (.76) | 91.1% | link |
| kseniya_16khz | 4.84 (.37) | 4.54 (.59) | 93.9% | link |
Мы просили людей в первую очередь оценивать естественность звучания речи (а не качество звука). Нас удивило, что по расспросам обычные люди на своих ежедневных девайсах не особо слышат разницу между 8 kHz и 16 kHz (что подтверждается оценками)! Самые низкие абсолютные оценки и самое низкое отношение у Байи. Самые высокие абсолютные оценки — у Ксении, а относительные — у Айдара
Тут важно отметить, что у Байи меньше поставлен голос, но поэтому он звучит более по-человечески за счет этого. У Байи также выше дисперсия оценок
Ручной просмотр аудио с большими расхождениями показывает ошибки спикеров, ошибки такотрона, ошибочные паузы (тоже вследствие ошибок такотрона), имена собственные и сложные слова, которые вообще непонятно как читать. Естественно 75% таких расхождений в синтезе (а не оригинале) и частота дискретизации особо не влияет.
Если мы пытались дать численную оценку естественности, то еще хорошо бы оценить «неестественность» или «роботизированность» голоса. По идее ее можно оценивать, давая людям пару аудио на выбор и прося выбрать между ними. Но мы пошли дальше и по сути применили «двойной слепой тест». Мы в случайном порядке дали людям поставить оценки «одному и тому же аудио» 4 раза — оригинал и синтез с разной частотой дискретизации. Для участников исследования, разметивших весь датасет, получается такая таблица:
| Сравнение | Хуже | Одинаково | Лучше |
|---|---|---|---|
| 16k против 8k, оригинал | 957 | 4811 | 1512 |
| 16k против 8k, синтез | 1668 | 4061 | 1551 |
| Оригинал против синтеза, 8k | 816 | 3697 | 2767 |
| Оригинал против синтеза, 16k | 674 | 3462 | 3144 |
Тут напрашивается несколько выводов:
- В 66% случаев люди не слышат разницы между 8k и 16k;
- В синтезе, 8k немного помогает скрыть ошибки;
- Примерно в 60% случаев люди считают, что синтез не хуже оригнала по естественности;
- Показательно, что два последних вывода не особо зависят от частоты дискретизации (8k имеет небольшое преимущество);
Можете оценить сами, как это звучит, как для наших уникальных голосов, так и для спикеров из внешних источников (больше аудио для каждого спикера можно синтезировать в colab.
Если вы не дружите с колабом или глаза разбегаются от количества файлов в папках с примерами, то вот несколько случайных аудио:
Айдар:
Байя:
Ксения:
Еще раз обращаю внимание, что это не cherry-picked примеры, а реальное звучание синтеза
Как настроить правильную техподдержку (helpdesk, service desk на коленке)
Эта статья будет полезна для компаний, которые оказывают техническую поддержку своим пользователям — внешним или внутренним клиентам
В статье я расскажу, как оказываем поддержку мы, как выстроили этот бизнес-процесс, что контролируем и на что обращаем внимание в работе
Вы можете использовать наш опыт при построении собственной системы поддержки или обратиться к нам за помощью за построением такой системы, будем рады помочь. В статье формируется основной набор правил, которые мы сформировали при настройке системы для себя, а так же небольшие примеры того, как мы эти правила применяем.
Работа с файлами телефонных звонков
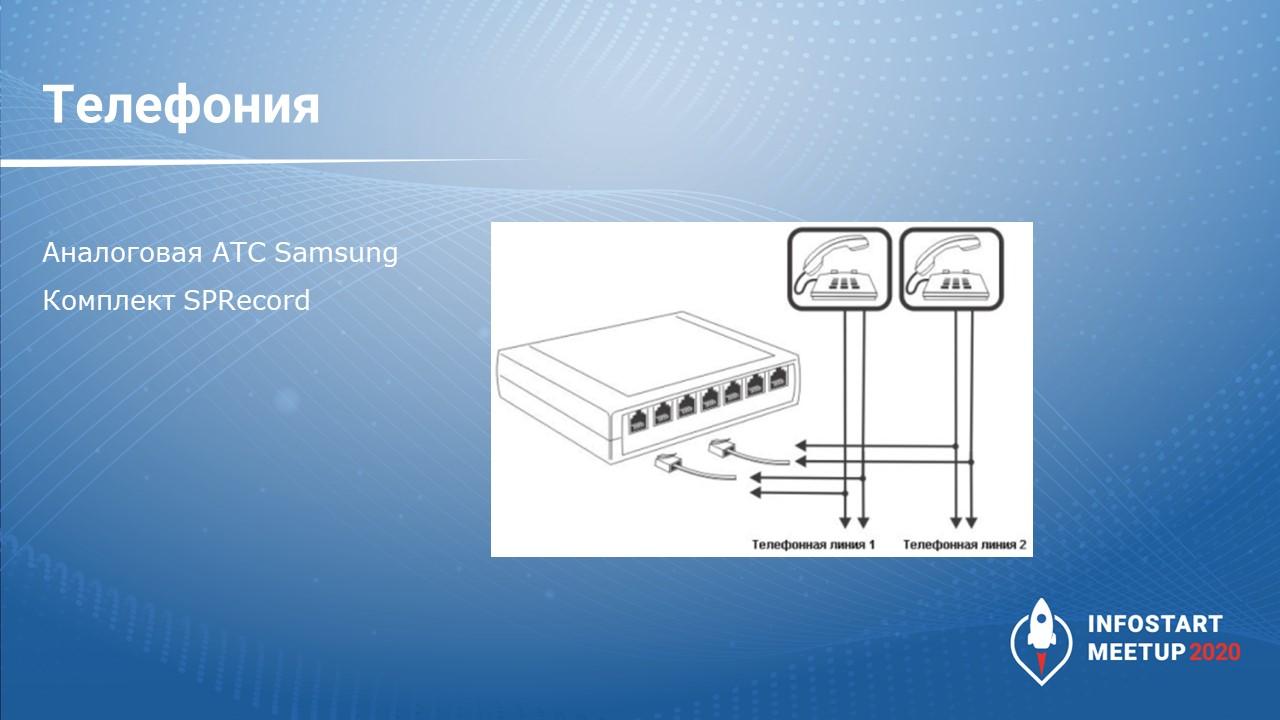
Какая ситуация с телефонией у нас была на предприятии:
-
У нас аналоговая АТС – аналоговые линии.
-
Дополнительно мы докупили комплекты SPRecord – можно перейти на сайт SPRecord, посмотреть, что это за устройство. Оно вешается параллельно аналоговой линии, записывает разговор и преобразует его в цифру – все звуковые файлы у него хранятся в формате *.wav без сжатия.
Соответственно, то, о чем я рассказываю, подходит для старых телефонных сетей. В новых цифровых сетях это уже решается гораздо проще – например, у MANGO есть отдельный сервис расшифровки телефонных звонков и отправка их на на почту.
Итак, у нас на фирме была аналоговая АТС, и все звонки записывались в формате *.wav.
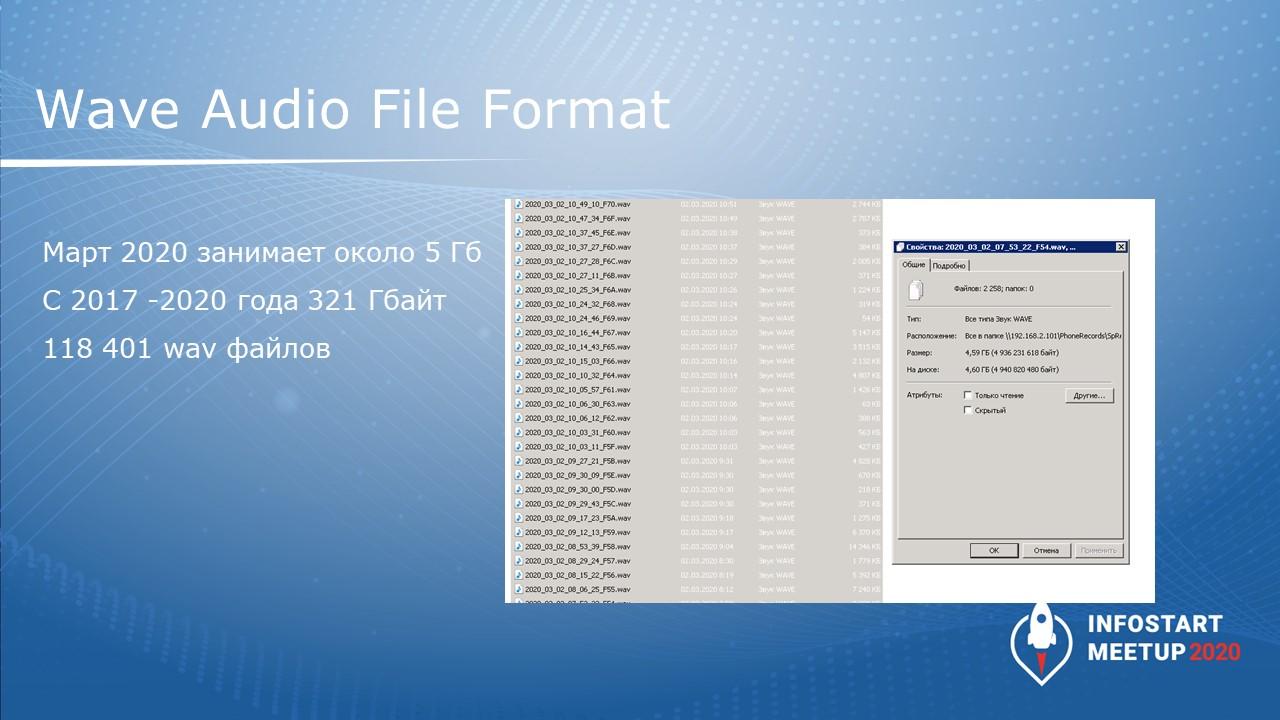
Начинали мы это делать еще в 2017 году, и за это время по текущую дату записано 118 тысяч звонков.
Объем файлов за месяц занимает примерно 5 гигабайт (по данным марта 2020 года).

Что нужно сделать, чтобы как-то обработать эти файлы? Я использовал бесплатную кросс-платформенную утилиту Sox Sound eXchange. Она вызывается из командной строки и с ее помощью можно прямо из 1С выполнить следующие действия:
-
получить длительность аудио – по команде
sox —i -d input.wav > output.txt -
поменять дискретизацию – по команде
sox —i -r » input.wav > output.txt -
обрезать файл – по команде
sox input.wav output.wav trim 20
Обрезку я использовал для исходящих звонков, где у нас обычно 20 секунд занимает дозвон – эти 20 секунд можно спокойно обрезать, чтобы сэкономить на расшифровке звонка.
У Яндекса расшифровка кратна 15 секундам, соответственно даже если вы отправляете одну секунду, вы платите за 15. Обрезав 20 секунд мы экономим на одном такте распознавания.
С аналоговой телефонии мы снимаем файлы в несжатом виде, в формате *.wav, а в Yandex их нужно отправлять в специальном формате OggOpus.
Соответственно, используем бесплатную консольную конвертацию с помощью утилиты opensenc, которую можно скачать с сайта https://opus-codec.org/
Команда выглядит так:
На входе даем wav-формат, и получаем сжатые аудиоданные.
Программы для озвучки текста
Если вам нужно постоянно озвучивать большие объемы текста из электронных документов, то самый удобный вариант — установить специальные приложения, которые умеют работать с файлами разного формата.
Балаболка
Балаболка — бесплатная программа озвучки для Windows от российских разработчиков. Она поддерживает работу с любыми голосовыми движками, установленными в системе. В ее интерфейсе есть стандартные инструменты для управления воспроизведением: пауза, остановка, перемотка, изменение скорости и громкости.
«Балаболка» умеет читать вслух текст из буфера обмена, произносить набираемые на клавиатуре фразы, озвучивать содержимое редактора или загруженных в нее файлов в форматах AZW, AZW3, CHM, DjVu, DOC, DOCX, EML, EPUB, FB2, FB3, HTML, LIT, MOBI, ODP, ODS, ODT, PDB, PDF, PPT, PPTX, PRC, RTF, TCR, WPD, XLS, XLSX.
Результат обработки «Балаболка» сохраняет как аудиофайл в форматах WAV, MP3, MP4, OGG и WMA. У нее также есть возможность сохранения текста внутри файлов MP3 для дальнейшего отображения в виде субтитров в медиапроигрывателе.
Govorilka
Govorilka — ещё одна программа для озвучки с минималистичным интерфейсом. Поддерживает голосовые движки устаревшего стандарта SAPI 4, в том числе на иностранных языках.
По умолчанию Govorilka озвучивает текст голосом стандартного движка Microsoft. В ее составе есть инструменты управления, традиционные для программ такого типа: воспроизведение, пауза, остановка, изменение скорости, громкости и высоты голоса. Одновременно в ней можно открыть до 8 вкладок с разными фрагментами текста.
Несмотря на простоту и устаревший интерфейс, «Говорилка» всё еще актуальна. Она умеет распознавать текстовые документы в разных форматах объёмом до 2 Гб и сохранять результат обработки в MP3 и WAV.
eSpeak
eSpeak — бесплатная программа для озвучки текста, доступная на Windows, macOS, Linux и Android. Она использует голосовые движки, установленные в системе, а также добавляет к ним несколько своих.
Версия этого приложения для Windows имеет максимально простой интерфейс и управление. Текст, который нужно прочитать, достаточно вставить в поле посредине окна, а затем нажать “Speak”.
Максимальный размер текста здесь явно не определен, но приложение справляется с большими объёмами. Также у него есть возможность читать тексты из файлов с расширением TXT, другие форматы не поддерживаются.
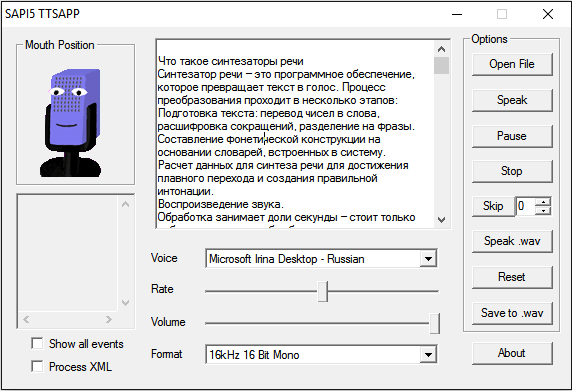
Для управления скоростью чтения в eSpeak используется ползунок Rate. Если вы хотите сохранить прочитанный текст в аудиофайл, нажмите на кнопку «Save to .wav» и задайте имя записи.
В мобильной версии приложения для Android аналогичная функциональность, разве что нет возможности сохранить текст в аудио.
Acapela TTS
Acapela Group разрабатывает программы для всех популярных операционных систем: Windows, macOS, Linux. Android, iOS. Среди главных достоинств этого софта — поддержка большого количества языков и отличное качество голоса. Мощные движки хорошо обучены и имеют развёрнутую справочную базу, которая позволяет им говорить правильно и выразительно.

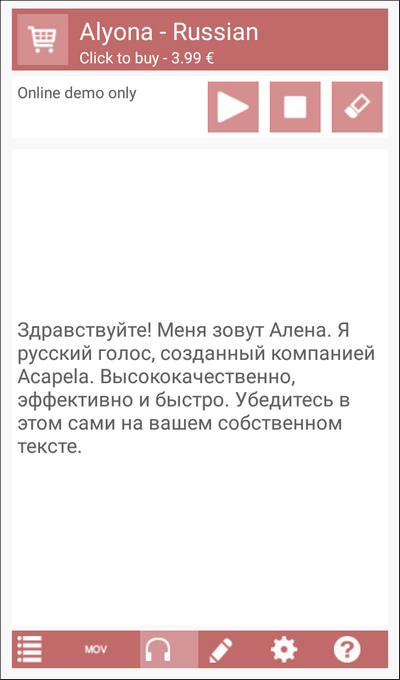
Однако все продукты Acapela коммерческие. Установить приложение на компьютер или телефон можно бесплатно, но без купленного голосового движка в них нет никакого смысла. Стоимость одного пакета — 3,99 евро. Прежде чем оплачивать покупку, вы можете прослушать демо голоса с произвольным текстом, чтобы определить, подходит ли вам такое звучание.
ICE Book Reader Professional
Если вы ищите программу, которая будет озвучивать целые книги, то попробуйте ICE Book Reader Professional. Это приложение поддерживает различные форматы текстовых документов: TXT, HTML, XML, RTF, DOC и DOCX, PALM (.PDB и .PRC), PSION/EPOC (.TCR), Microsoft Reader (.LIT), Microsoft HELP files (.CHM) и FictionBook файлы (все версии) (.FB2, .XML). А для чтения в нем используются голосовые движки стандарта SAPI 4 и 5.
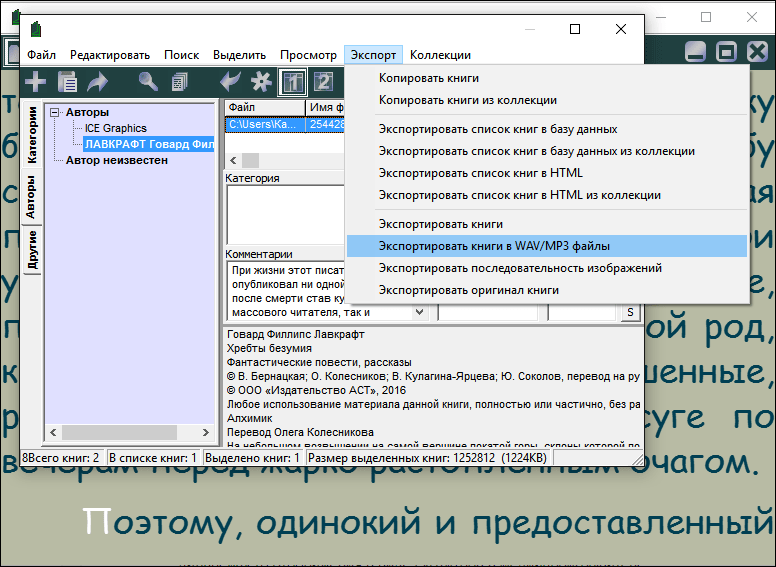
Программа умеет превращать книги в MP3/WAV-файлы. Это значит, что вы можете из любого произведения, доступного в текстовом формате, сделать аудиокнигу.
Скорость преобразования текста в голос в этом приложении увеличивается за счёт одновременного использования нескольких модулей синтеза речи.
Командная строка Яндекса
С её помощью мы сможем получать нужные ключи доступа, чтобы отправлять файлы с записями на сервер для обработки.
Весь процесс установки мы опишем для Windows. Если у вас Mac OS или Linux, то всё будет то же самое, но с поправкой на операционную систему. Поэтому если что — .
Для установки и дальнейшей работы нам понадобится PowerShell — это программа для работы с командной строкой, но с расширенными возможностями. Запускаем PowerShell и пишем там такую команду:
iex (New-Object System.Net.WebClient).DownloadString(‘https://storage.yandexcloud.net/yandexcloud-yc/install.ps1’)
Она скачает и запустит установщик командной строки Яндекса. В середине скрипт спросит нас, добавить ли путь в системную переменную PATH, — в ответ пишем Y и нажимаем Enter:
Командная строка Яндекса установлена в системе, закрываем PowerShell и запускаем его заново. Теперь нам нужно получить токен авторизации — это такая последовательность символов, которая покажет «Облаку», что мы — это мы, а не кто-то другой.
Переходим по специальной ссылке, которая даст нам нужный токен. Сервис спросит у нас, разрешаем ли мы доступ «Облака» к нашим данным на Яндексе — нажимаем «Разрешить». В итоге видим страницу с токеном:
Теперь нужно закончить настройку командной строки Яндекса, чтобы можно было с ней полноценно работать. Для этого в PowerShell пишем команду:
yc init
Когда скрипт попросит — вводим токен, который мы только что получили:
Сначала отвечаем «1», затем «Y» и «4».
Знакомство с API Yandex SpeechKit
Представьте простую, максимально идеальную ситуацию без подводных камней типа “а если..”. Вы организуете закрытую вечеринку и хотите общаться с гостями, ни на что не отвлекаясь. Тем более на тех, кого вы не ждали.
Давайте попробуем создать виртуального дворецкого, который будет встречать гостей и открывать дверь только приглашенным.
Синтез текста через cURL
С помощью встроенной в bash команды export запишем данные в переменные:
Теперь их можно передать в POST-запрос с помощью cURL:
Рассмотрим параметры запроса:
speech.raw – файл формата LPSM (несжатый звук). Это и есть озвученный текст в бинарном виде, который будет сохранен в текущую папку.
lang=ru-RU – язык текста.
emotion=good – эмоциональный окрас голоса. Пусть будет дружелюбным.
voice=ermil – текст будет озвучен мужским голосом Ermil. По умолчанию говорит Оксана.
https://tts.api.cloud.yandex.net/speech/v1/tts:synthesize – url, на который отправляется post-запрос на синтез речи дворецкого.
Бинарный файл послушать не получится, тогда установим утилиту SoX и сделаем конвертацию в wav:
speech.wav – приветствие готово и сохранено в текущую папку.
Для проигрывания wav внутри кода Python, можно взять, например, библиотеку simpleaudio. Она простая и не создает других потоков:
Итак, наш первый гость стоит перед входом на долгожданную party. Пытается открыть дверь, и вдруг слышит голос откуда-то сверху:
«Привет, чувак! Назови-ка мне свои имя и фамилию?» (или ваш вариант)
Отлично! Вы научили дворецкого приветствовать гостей, используя командную строку и cURL. А пока гость вспоминает ответ, научимся работать с API на языке Python.
Распознавание текста с помощью requests
Мы могли бы снова воспользоваться cURL для отправки ответа гостя на распознавание. Но мы пойдем дальше и напишем небольшую программу, основанную на подобных запросах.
Создайте готовый аудио-файл с ответом гостя. Сделать это можно через встроенный микрофон на вашем ноутбуке разными инструментами. Для macos подойдет Quick Time Player. Сконвертируйте аудио в формат ogg: name_guest.ogg. Можно онлайн, например, тут
Итак, пишем код на Python:
Для отправки запросов в Python воспользуемся стандартной библиотекой requests:
Импортируем в код:
Зададим параметры, которые мы получили в командной строке:
Аудио необходимо передавать в запрос в бинарном виде:
Давайте обернем весь процесс распознавания в функцию recognize:
Итак, чтобы дворецкий смог проверить гостя по списку, вызовем функцию и распознаем ответ:
Теперь очередь за дворецким. В нашем случае, он вежлив ко всем. И прежде чем открыть или не открыть гостю дверь, он обратится лично. Например, так:
“Мы вам очень рады, <имя_и фамилия_гостя>, но вас нет в списке, сорян”
Для последующего синтеза вы можете снова воспользоваться CURL или так же написать функцию на Python. Принцип работы с API для синтеза и распознавания речи примерно одинаков.
Вопросы
-
Почему вы используете консольные команды, а не REST-запросы по API?
-
В первых версиях этой обработки я использовал запросы напрямую из 1С. Но поскольку при распознавании коротких аудиозаписей мне приходилось запускать базу 1С в несколько потоков, четыре базы 1С, запущенные на одном компьютере, существенно съедали память. Из-за этого и перешли на Curl.
-
Разве у вас файловая база? В клиент-серверной базе можно пользоваться фоновыми заданиями, сделать REST-запрос на сервере. Такая возможность есть очень давно. У меня тоже используется подобное решение, правда для других целей – стартует несколько фоновых потоков, каждый из которых что-то выполняет. В вашем случае это дало бы очень сильный выигрыш.
-
Как вы решаете случаи, когда одно слово отправлено в разных кусках – будет ли оно распознано?
-
У нас есть исходная расшифровка и есть расшифровка менеджера, который приводит исходную расшифровку в более читаемый текстовый вид, потому что все равно исходное распознавание получается не стопроцентное – аналоговая АТС вносит свои коррективы. Например, при проверке онлайн-распознавания на сайте Яндекса, слова, сказанные в микрофон с ноутбука, распознаются лучше, чем загруженные из файла телефонного разговора, записанного через обычный аналоговый аппарат АТС. Соответственно, менеджеру приходится исправлять за Яндексом ошибки. Так эта проблема и решается.
-
Сколько времени заняла реализация проекта и какое количество суммарно сотрудников менеджеров телефонных звонков у такая статическая информация о понять масштабы?
-
Я на слайде приводил статистику – с 2017 года было обработано 118 тысяч звонков. У нас работает где-то 45 менеджеров, в месяц они наговаривают 5 гигабайт этих телефонных разговоров. Такое количество звуковой информации можно спокойно распознать в четырех потоках. Яндекс предоставляет 20 потоков, соответственно, еще есть куда расти.
-
Когда вы конвертируете wav-файлы в OggOpus, вы не пробовали играться, на каком битрейте уже распознавание хуже?
-
Я пробовал менять частоту дискретизации. Соответственно, сейчас он по умолчанию там на 11000 0,25 герц я пробовал увеличить в два раза до 22000. Размер файла увеличился в два раза, стоимость распознавания увеличилась, но качество не очень увеличилась. Скажу по опыту, что легче поставить хорошие телефонные аппараты, убрать фоновое звучание музыки – сделать тихий кабинет. Тогда все распознается идеально. Допустим, когда распознается автоответчик, что-то наговаривает, то когда Яндекс пытается это преобразовать в текст все идеально получается. Когда менеджер комкает слова либо быстро говорит – соответственно, возможны проблемы. То есть легче поменять оборудование и просить менеджеров следить за четким произнесением ключевых слов. Например, еси нужно, чтобы зафиксировалась слово «Заказ», то они должны четко сказать «Заказ», тогда это слово точно отделится пробелами от всех остальных слов и можно будет делать по нему поиск.
-
Что делать с переадресацией звонков на мобильный, звонки с мобильных, в WhatsApp и так далее? Или у вас все только через корпоративную АТС и других вариантов нет?
-
Если в компании используется мобильная телефония, то лучше перейти на цифровые АТС, например, на MANGO. Нашими силами это не решить – если звонок ушел с АТС, SPRecord его не запишет, и он не будет расшифрован.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Saint Petersburg.Online. Больше статей можно прочитать здесь.