10 приемов для преобразования и декомпозиции строк в python
Содержание:
- Isdecimal (): Как проверить десятичные дроби только в строке в Python
- Как изменить строку в Python
- Методы Boolean
- Резюме: Длина строки Python
- Мир регулярных выражений
- RSTRIP (): Как удалить пробелы и символы с конца строки в Python
- Синтаксис регулярных выражений
- Кодировки
- Rjust (): как правильно озвучить строку в Python
- Строковые операторы
- Табуляция и разрыв строк в Python.
- Узнайте, какие встроенные методы Python используются в строковых последовательностях
- F-строки. Форматирование строк в Python.
- Простой синтаксис
- re.sub()
- Программы Python для преобразования строчной строки в строчную с помощью lower()
- Как обрабатывать многослойные строки в Python
Isdecimal (): Как проверить десятичные дроби только в строке в Python
Используйте Способ проверки, если строка содержит только десятичные дроби, то есть только номера от 0 до 9 и комбинации этих чисел.
Подписки, суперскрипты, римские цифры и другие вариации будут возвращены как Отказ
word = '32'
print(word.isdecimal())
#output: True
word = '954'
print(word.isdecimal())
#output: True
print("\u2083".isdecimal()) #unicode for subscript 3
#output: False
word = 'beach'
print(word.isdecimal())
#output: False
word = 'number32'
print(word.isdecimal())
#output: False
word = '1 2 3' #notice the space between chars
print(word.isdecimal())
#output: False
word = '@32$' #notice the special chars '@' and '$'
print(word.isdecimal())
#output: False
больше строго, чем , который в свою очередь более строгим, чем Отказ
Как изменить строку в Python
Чтобы изменить строку, используйте синтаксис ломтика:
my_string = "ferrari" my_string_reversed = my_string print(my_string) print(my_string_reversed)
ferrari irarref
Slice Syntax позволяет вам установить шаг, который является в примере.
Шаг по умолчанию – То есть идти вперед 1 символ струны за раз.
Если вы установите шаг в У вас есть противоположное, верните 1 символ за раз.
Таким образом, вы начинаете в положении последнего символа и двигайтесь назад к первому символу в положении 0.
Это оно!
Поздравляем с достижением конца.
Я хочу поблагодарить вас за чтение этой статьи.
Если вы хотите узнать больше, оформить мой блог Renanmf.com Отказ
Помните Для скачивания PDF версия этого Python String Manipution справочника Отказ
Вы также можете найти меня в Twitter: @renanmouraf Отказ
Методы Boolean
Python предоставляет несколько методов строк, которые могут выражать логическое значение. Эти методы полезны при создании форм, которые должен заполнить пользователь. Например, в поле почтового кода пользователь не сможет вводить ничего, кроме цифр, а в поле имени – только буквенные строки.
Ниже приведены методы строк для работы со значениями Boolean.
| Method | True if |
| str.isalnum() | Строка состоит только из алфавитно-цифровых символов |
| str.isalpha() | Строка состоит только из букв |
| str.islower() | Строка содержит буквенные символы только в нижнем регистре |
| str.isnumeric() | Строка состоит только из числовых символов |
| str.isspace() | Строка состоит только из пробельных символов |
| str.istitle() | Слова в строке начинаются с заглавной буквы |
| str.isupper() | Строка содержит буквенные символы только в верхнем регистре |
Попробуйте использовать пару этих методов:
Для строки number метод str.isnumeric() вернул True, поскольку строка содержит только числовые символы. Для строки letters этот метод вернул False, потому что она состоит из буквенных символов.
Аналогичным образом можно запросить, состоит ли строка из буквенных символов в верхнем или нижнем регистре, и начинаются ли слова в строке с заглавной буквы. Создайте несколько строк:
Теперь используйте методы Boolean для проверки регистра в строках:
Результаты будут такими:
Проверяя регистр в строках, вы можете надлежащим образом отсортировать и стандартизировать собранные данные, а также проверять и изменять строки по мере необходимости.
Методы Boolean позволяют убедиться, что пользователь вводит данные согласно установленным параметрам.
Резюме: Длина строки Python
Мы видели все 5 различных способов определения длины строки, но в заключение отметим, что только один из них является практичным. Встроенное ключевое слово len () – это лучший способ найти длину строки в любом формате.
- Python len()-это встроенная функция. Вы можете использовать len (), чтобы найти длину данной строки, массива, списка, кортежа, словаря и т. Д.
- Возвращаемое значение: Он вернет целочисленное значение, то есть длину данной строки.
Однако, если у вас есть какие-либо сомнения или вопросы, дайте мне знать в разделе комментариев ниже. Я постараюсь помочь вам как можно скорее.
Счастливого Пифонирования!
Мир регулярных выражений
Иногда непросто очистить текст с помощью определенных символов или фраз. Вместо этого нам необходимо использовать некоторые шаблоны. И здесь нам на помощь приходят регулярные выражения и соответствующий модуль Python.
Мы не будем обсуждать всю мощь регулярных выражений, а сосредоточимся на их применении — например, на разделении и замене данных. Да, эти задачи были описаны выше, но вот более мощная альтернатива.
Разделение по шаблону:
import re
test_punctuation = " This &is example? {of} string. with.? punctuation!!!! "
re.split('\W+', test_punctuation)
Out:
Замена по шаблону:
import re
test_with_numbers = "This is 1 string with 10 words for 9 digits 2 example"
re.sub('\d', '*', test_with_numbers)
Out: 'This is * string with ** words for * digits * example'
RSTRIP (): Как удалить пробелы и символы с конца строки в Python
Используйте Способ удаления пробелов с конца строки.
regular_text = "This is a regular text. " no_space_end_text = regular_text.rstrip() print(regular_text) #'This is a regular text. ' print(no_space_end_text) #'This is a regular text.'
Обратите внимание, что оригинал Переменная остается неизменным, поэтому вам нужно назначить возврат метода новой переменной, в таком случае. Метод также принимает определенные символы для удаления в качестве параметров
Метод также принимает определенные символы для удаления в качестве параметров.
regular_text = "This is a regular text.$@G#"
clean_end_text = regular_text.rstrip("#$@G")
print(regular_text)
#This is a regular text.$@G#
print(clean_end_text)
#This is a regular text.
Синтаксис регулярных выражений
Каштан: P ** (YIYTIYTHIYTHO)? ** N, регулярные выражения состоят из операторов и операторов, выделенные жирным шрифтом являются операторами
Часто используемые операторы в регулярных выражениях
| оператор | Описание | Пример |
|---|---|---|
| . | Представляет любой одиночный символ | |
| Набор символов, дающий диапазон значений для одного символа | означает a, b, c, означает один символ от a до z, , означает W, K | |
| Не символьный набор, предоставляющий диапазон исключения для одного символа | обозначает единственный символ, отличный от a, b или c | |
| * | Расширить предыдущий символ 0 раз или неограниченное количество раз | abc *, что означает ab, abc, abcc, abcc и т. д. |
| + | Продлить предыдущий символ 1 раз или неограниченное количество раз | abc +, что означает abc, abcc, abccc и т. д. |
| ? | 0 или 1 расширение предыдущего символа | abc? означает ab, abc |
| | | Любое из левого и правого выражений | abc | def означает abc, def |
| {m} | Расширить предыдущий символ m раз | ab {2} c означает abbc |
| {m,n} | Продлить предыдущий символ с m до n раз (включая n) | ab {1,2} c означает abc, abbc |
| ^ | Соответствует началу строки | ^ abc означает abc и находится в начале строки |
| $ | Совпадение конца строки | abc $ означает abc и находится в конце строки |
| ( ) | Отметка группировки, только оператор | может использоваться внутри | (Abc) означает abc, (abc | def) означает abc, def |
| \d | Число, эквивалентное | |
| \w | Символ слова, эквивалентный |
Например:
| Регулярное выражение | Соответствующая строка |
|---|---|
| P(Y|YT|YTH|YTHO)?N | PN,PYN,PYTN,PYTHN,PYTHON |
| PYTHON+ | PYTHON,PYTHONN,PYTHONNN… |
| PYON | PYTON,PYHON |
| PY?ON | PYON, PYAaN, PYbON, PYcON … (без T / H) |
| PY{0:3}N | PN, PYN, PYYN, PYYYN |
Некоторые классические регулярные выражения
| ^+$ | Строка из 26 букв |
|---|---|
| ^+$ | Строка из 26 букв и цифр |
| ^-?\d+$ | Строка в целочисленной форме (может иметь отрицательные числа) |
| ^**$ | Строка в форме положительного целого числа ** (Если элемент в [] не имеет согласованного числа раз, он может повторяться неограниченное количество раз по умолчанию) ** |
| \d{5} | Почтовый индекс в Китае |
| Соответствие китайских иероглифов (использование utf-8 для согласования диапазона значений китайских иероглифов) | |
| \d{3}-\d{8}|\d{4}-\d{7} | Внутренний номер телефона 010-68913536 или 010-6891-3536 |
Регулярное выражение, соответствующее IP-адресу
IP-адрес состоит из 4 сегментов, каждый сегмент — от 0 до 255, разделенных знаком «.», Например 210.134.3.123.
первый шаг:, Независимо от длины
Второй шаг:Учитывайте длину
Шаг 3: Сегментация
0-99:
100-199:
200-249:
250-255:
сочетание:
Кодировки
Другим любопытным моментом является то, что символы которые мы видим внутри строки на самом деле являются порядковыми номерами в таблице которая ставит в соответсвие этому номеру определенный сивол. Эти таблицы мы называем кодировками. Существует очень много кодировок, но возможно вы слышали названия некоторых из них: ASCII, Latin-1, КОИ-8, utf-8. По умолчанию, в Python используется стандарт «Юникод». И в том что каждому символу соответствует определенный код очень легко убедиться с помощью встроенных функций и :
Но к превеликому сожалению, это не только любопытно, но еще и очень печально. Представим себе, что наша программа должна обмениваться текстом с другой программой. Так как строки хранятся в виде байтов, то в нашу программу должна прилететь строка, которая может выглядеть, например, вот так . Что же с ней делать?:
Чтож, похоже что программа-отправитель использует какуюто другую кодировку. Допустим, мы смогли выяснить, что до того как эта строка стала набором байтов ее напечатали на русском языке. Русский язык поддерживают многие кодировки. Придется пробовать декодировать в каждую из них. Поехали…
Какя-то абракадабра. Пробуем следующую:
Как видите, байтовые строки не несут информации о своей кодировке, хотя в зависимости от происхождения, эта кодировка может быть какой угодно. Рассмотренная проблема встречается очень редко, но все же встречается. Многие научные программы до сих пор используют кодировку ascii по умолчанию, а некоторые операционные системы могут использовать какую-то другую кодировку. Вообще, кодировкой по умолчанию является кодировка операционной системы (можно узнать с помощью функции модуля sys). Так что, если вы создаете интернациональное приложение или сайт, или не знаете с какой операционкой придется работать вашей программе, то наверняка тоже встретитесь с этой проблемой. Повторюсь, проблема редкая, весьма специфичная и Python предоставляет относительно неплохие средства для ее преодоления.
Чтож, вот мы и познакомились со строками. Определение, которое мы дали в начале, могло показаться очень сложным и непонятным (я даже не совсем уверен в его правильности), но тем не менее, на деле, все оказалось довольно простым.
Rjust (): как правильно озвучить строку в Python
Используйте направо – оправдать строку.
word = 'beach' number_spaces = 32 word_justified = word.rjust(number_spaces) print(word) #'beach' print(word_justified) #' beach'
Обратите внимание на пробелы во второй строке. Слово «Beach» имеет 5 символов, что дает 27 пространства для заполнения пустым пространством
Оригинал Переменная остается неизменным, поэтому нам нужно назначить возврат метода новой переменной, в таком случае.
Также принимает определенный символ в качестве параметра для заполнения оставшегося пространства.
word = 'beach' number_chars = 32 char = '$' word_justified = word.rjust(number_chars, char) print(word) #beach print(word_justified) #$$$$$$$$$$$$$$$$$$$$$$$$$$$beach
Похоже на первую ситуацию, у меня есть 27 Знаки, чтобы сделать его 32, когда я считаю 5 символов, содержащихся в словом «Beach».
Строковые операторы
| Оператор | Описание |
|---|---|
| + | Он известен как оператор конкатенации, используемый для соединения строк по обе стороны от оператора. |
| * | Известен как оператор повторения. Он объединяет несколько копий одной и той же строки. |
| [] | оператор среза. Он используется для доступа к подстрокам определенной строки. |
| оператор среза диапазона, используется для доступа к символам из указанного диапазона. | |
| in | Оператор членства. Он возвращается, если в указанной строке присутствует определенная подстрока. |
| not in | Также является оператором членства и выполняет функцию, обратную in. Он возвращает истину, если в указанной строке отсутствует конкретная подстрока. |
| r / R | Используется для указания необработанной строки. Необработанные строки применяются в тех случаях, когда нам нужно вывести фактическое значение escape-символов, таких как «C: // python». Чтобы определить любую строку как необработанную, за символом r или R следует строка. |
| % | Необходим для форматирования строк. Применяет спецификаторы формата, используемые в программировании на C, такие как %d или %f, для сопоставления их значений в python. Мы еще обсудим, как выполняется форматирование в Python. |
Рассмотрим следующий пример, чтобы понять реальное использование операторов Python.
str = "Hello"
str1 = " world"
print(str*3) # prints HelloHelloHello
print(str+str1)# prints Hello world
print(str) # prints o
print(str); # prints ll
print('w' in str) # prints false as w is not present in str
print('wo' not in str1) # prints false as wo is present in str1.
print(r'C://python37') # prints C://python37 as it is written
print("The string str : %s"%(str)) # prints The string str : Hello
Выход:
HelloHelloHello Hello world o ll False False C://python37 The string str : Hello
Табуляция и разрыв строк в Python.
В программировании термином пропуск ( whitespace ) называются такие непечатаемые символы, как пробелы, табуляции и символы конца строки. Пропуски структурируют текст, чтобы пользователю было удобнее читать его.
В таблице приведены наиболее часто встречаемые комбинации символов.
|
Последовательность символов |
Описание |
|---|---|
| \t | Вставляет символ горизонтальной табуляции |
| \n | Вставляет в строку символ новой строки |
| \\ | Вставляет символ обратного слеша |
| \» | Вставляет символ двойной кавычки |
| \’ | Вставляет символ одиночной кавычки |
Для добавления в текст табуляции используется комбинация символов \t. Разрыв строки добавляется с помощью комбинации символов \n.
>>> print(«Python»)Python
>>> print(«\tPython»)
Python
>>> print(«Языки программирования:\nPython\nJava\nC»)Языки программирования:
Python
Java
C
Табуляция и разрыв строк могут сочетаться в тексте. В следующем примере происходит вывод одного сообщения с разбиением на строки с отступами.
>>> print(«Языки программирования:\n\tPython\n\tJava\n\tC»)Языки программирования:
Python
Java
C
Узнайте, какие встроенные методы Python используются в строковых последовательностях
Строка — это последовательность символов. Встроенный строковый класс в Python представлен строками, использующими универсальный набор символов Unicode. Строки реализуют часто встречающуюся последовательность операций в Python наряду с некоторыми дополнительными методами, которые больше нигде не встречаются. На картинке ниже показаны все эти методы:
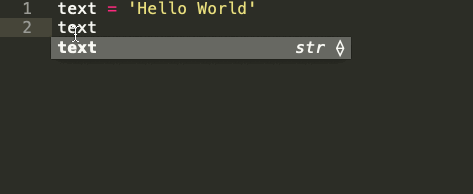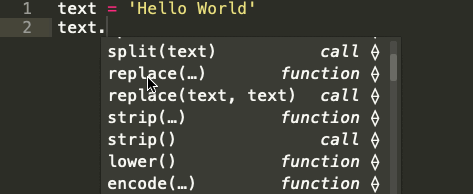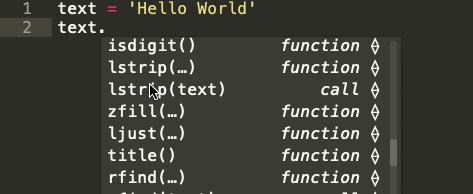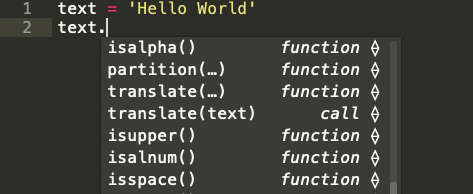 Встроенные строковые функции в Python
Встроенные строковые функции в Python
Давайте узнаем, какие используются чаще всего
Важно заметить, что все строковые методы всегда возвращают новые значения, не меняя исходную строку и не производя с ней никаких действий
Код для этой статьи можно взять из соответствующего репозитория Github Repository.
1. center( )
Метод выравнивает строку по центру. Выравнивание выполняется с помощью заданного символа (пробела по умолчанию).
Синтаксис
, где:
- length — это длина строки
- fillchar—это символ, задающий выравнивание
Пример

2. count( )
Метод возвращает счёт или число появлений в строке конкретного значения.
Синтаксис
, где:
- value — это подстрока, которая должна быть найдена в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
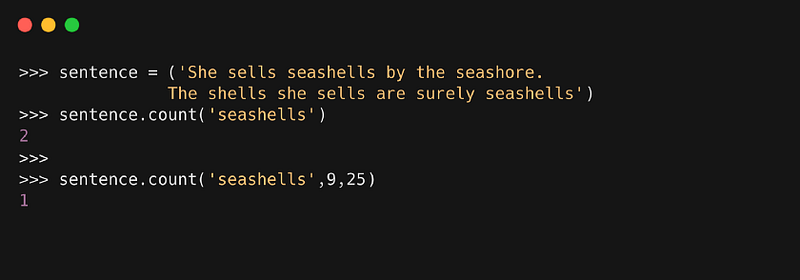
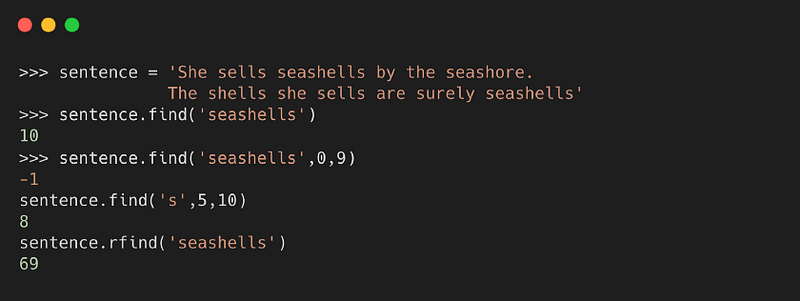
3. find( )
Метод возвращает наименьшее значение индекса конкретной подстроки в строке. Если подстрока не найдена, возвращается -1.
Синтаксис
, где:
- value или подстрока, которая должна быть найдена в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
Метод возвращает копию строки, преобразуя все заглавные буквы в строчные, и наоборот.
Синтаксис
Пример

5. startswith( ) and endswith( )
Метод возвращает True, если строка начинается с заданного значения. В противном случае возвращает False.
С другой стороны, функция возвращает True, если строка заканчивается заданным значением. В противном случае возвращает False.
Синтаксис
- value — это искомая строка в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
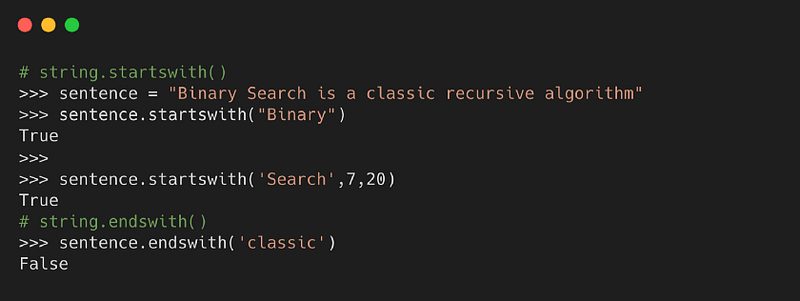
6. split( )
Метод возвращает список слов в строке, где разделителем по умолчанию является пробел.
Синтаксис
- sep: разделитель, используемый для разделения строки. Если не указано иное, разделителем по умолчанию является пробел
- maxsplit: обозначает количество разделений. Значение по умолчанию -1, что значит «все случаи»
Пример
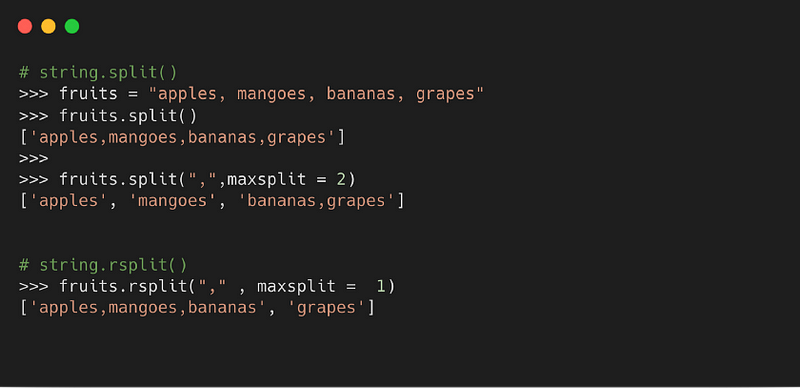
7. Строка заглавными буквами
Синтаксис
Синтаксис
Синтаксис
Пример

8. ljust( ) и rjust( )
С помощью заданного символа (по умолчанию пробел) метод возвращает вариант выбранной строки с левым выравниванием. Метод rjust() выравнивает строку вправо.
Синтаксис
- length: длина строки, которая должна быть возвращена
- character: символ для заполнения незанятого пространства, по умолчанию являющийся пробелом
Пример
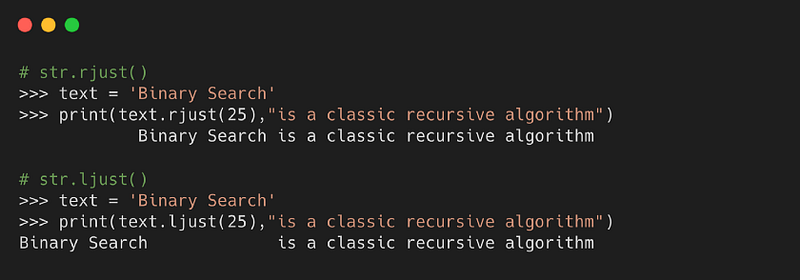
9. strip( )
Метод возвращает копию строки без первых и последних символов. Эти отсутствующие символы — по умолчанию пробелы.
Синтаксис
character: набор символов для удаления
- : удаляет символы с начала строки.
- : удаляет символы с конца строки.
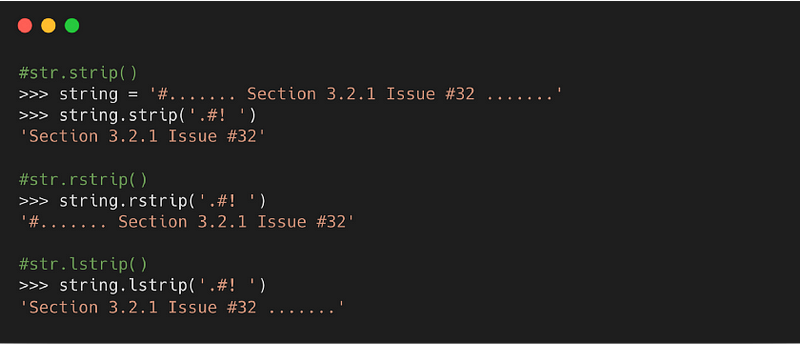
10. zfill( )
Метод zfill() добавляет нули в начале строки. Длина возвращаемой строки зависит от заданной ширины.
Синтаксис
width: указывает длину возвращаемой строки. Нули не добавляются, если параметр ширины меньше длины первоначальной строки.
Пример

Заключение
В статье мы рассмотрели лишь некоторые встроенные строковые методы в Python. Есть и другие, не менее важные методы, с которыми при желании можно ознакомиться в соответствующей документации Python.
- PEG парсеры и Python
- Популярные лайфхаки для Python
- Овладей Python, создавая реальные приложения. Часть 1
Перевод статьи Parul PandeyUseful String Method
F-строки. Форматирование строк в Python.
Часто требуется использовать значения переменных внутри строки. Предположим, что у вас имя и фамилия хранятся в разных переменных и вы хотите их объединить для вывода полного имени.
name = «Александр»
surname = «Пушкин»
Для того чтобы вставить значение переменных в строку, нужно поставить букву f непосредственно перед открывающейся кавычкой. Заключить имя или имена переменных в фигурные скобки {}.
full_name = f»{name} {surname}»
Python заменить каждую переменную на ее значение при выводе строки.
>>> name = «Александр»
>>> surname = «Пушкин»
>>> full_name = f»{name} {surname}»
>>> print(full_name)Александр Пушкин
Буква f происходит от слова format, потому что Python форматирует строку, заменяя имена переменных в фигурных скобках на их значения. В итоге выводится строка имя и фамилия.
Если в переменной имя и фамилия записана с маленькой буквы, то на помощь придет метод . Так же с помощью f строк можно строить сообщения, которые затем сохраняются в переменной.
>>> name = «александр»
>>> surname = «пушкин»
>>> full_name = f»{name} {surname}»
>>> print(f»Русский поэт {full_name.title()}!»)Русский поэт Александр Пушкин!
>>> message = f»Мой любимый поэт {name.title()} {surname.title()}»
>>> print(message)Мой любимый поэт Александр Пушкин
Важно: F-строки впервые появились в Python3.6. Если вы используете более раннею версию, используйте метод format
Что бы использовать метод format(), перечислите переменные в круглых скобках после format.
full_name = «{} {}».format(name, surname)
Простой синтаксис
Синтаксис аналогичен тому, который вы используете в (), но не такой перегруженный. Посмотрите на эту читабельность:
Python
name = «Eric»
age = 74
print(f»Hello, {name}. You are {age}.»)
# Вывод: ‘Hello, Eric. You are 74.’
|
1 2 3 4 5 |
name=»Eric» age=74 print(f»Hello, {name}. You are {age}.») # Вывод: ‘Hello, Eric. You are 74.’ |
Вы также можете использовать заглавную букву F:
Python
print(F»Hello, {name}. You are {age}.»)
# Вывод: ‘Hello, Eric. You are 74.’
|
1 2 |
print(F»Hello, {name}. You are {age}.») # Вывод: ‘Hello, Eric. You are 74.’ |
Вам уже нравится? Надеемся, что да, в любом случае, вы будете в восторге к концу статьи.
re.sub()
Здесь значение «sub» — это сокращение от substring, т.е. подстрока. В данном методе исходный шаблон сопоставляется с заданной строкой и, если подстрока найдена, она заменяется параметром repl.
Кроме того, у метода есть дополнительные аргументы. Это , счетчик, в нем указывается, сколько раз заменяется регулярное выражение. А также , в котором мы можем указать флаг регулярного выражения (например, )
Синтаксис:
В результате работы кода возвращается либо измененная строка, либо исходная.
Посмотрим на работу метода на следующем примере.
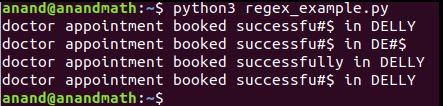
import re
# Шаблон 'lly' встречается в строке в "successfully" и "DELLY"
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY'))
# Благодаря использованию флага регистр игнорируется, и 'lly' находит два совпадения
# Когда совпадения найдены, 'lly' заменяется на '~*' в "successfully" и "DELLY".
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY', flags=re.IGNORECASE))
# Чувствительность к регистру: 'lLY' не находит совпадений, и ничего в строке не будет заменено
print(re.sub('lLY', '#$', 'doctor appointment booked successfully in DELLY'))
# С count = 1 заменяется только одно совпадение с шаблоном
print(re.sub('lly', '#$', 'doctor appointment booked successfully in DELLY', count=1, flags=re.IGNORECASE))
Программы Python для преобразования строчной строки в строчную с помощью lower()
Хватит разговоров, теперь давайте перейдем прямо к программам python, чтобы преобразовать строку в нижний регистр. Здесь мы используем функцию Python lower (), которая преобразует всю строку в нижний регистр. Это простой метод изменения символов верблюжьего регистра на символы строчной буквы.
Пример 1: Базовая программа для преобразования строки в нижний регистр
Выход:
Приведенный выше пример показывает вывод функции lower() Python. Вывод не содержит символов camel case в данной строке после преобразования. Здесь, перед преобразованием, последнее строковое слово содержит все буквы в заглавном регистре. Python также преобразует эти буквы в строчную букву, используя lower().
Пример 2: Программа для преобразования пользовательской входной строки в нижний регистр
Выход:
Здесь, в приведенной выше программе, мы принимаем входные данные от пользователя с помощью функции input (). Затем с помощью метода lower() мы преобразовали пользовательскую строку в нижний регистр.
Моменты, Которые Следует Отметить:
- lower() не принимает никаких аргументов, поэтому возвращает ошибку при передаче параметра.
- Цифры и символы возвращаются как есть, Только заглавная буква возвращается после преобразования в нижний регистр.
Как обрабатывать многослойные строки в Python
Тройные цитаты
Чтобы обрабатывать многослойные струны в Python, вы используете тройные цитаты, либо одиноки, либо двойные.
Этот первый пример использует двойные кавычки.
long_text = """This is a multiline, a long string with lots of text, I'm wrapping it in triple quotes to make it work.""" print(long_text) #output: #This is a multiline, # #a long string with lots of text, # #I'm wrapping it in triple quotes to make it work.
Сейчас так же, как и раньше, но с одиночными цитатами:
long_text = '''This is a multiline, a long string with lots of text, I'm wrapping it in triple quotes to make it work.''' print(long_text) #output: #This is a multiline, # #a long string with lots of text, # #I'm wrapping it in triple quotes to make it work.
Обратите внимание, что оба выхода одинаковы
Круглые скобки
Давайте посмотрим пример с круглыми скобками.
long_text = ("This is a multiline, "
"a long string with lots of text "
"I'm wrapping it in brackets to make it work.")
print(long_text)
#This is a multiline, a long string with lots of text I'm wrapping it in triple quotes to make it work.
Как видите, результат не то же самое. Для достижения новых строк я должен добавить , как это:
long_text = ("This is a multiline, \n\n"
"a long string with lots of text \n\n"
"I'm wrapping it in brackets to make it work.")
print(long_text)
#This is a multiline,
#
#a long string with lots of text
#
#I'm wrapping it in triple quotes to make it work.
Вершины
Наконец, обратные косания также являются возможностью.
Уведомление нет места после персонаж, как он бросил бы ошибку.
long_text = "This is a multiline, \n\n" \ "a long string with lots of text \n\n" \ "I'm using backlashes to make it work." print(long_text) #This is a multiline, # #a long string with lots of text # #I'm wrapping it in triple quotes to make it work.