Запрет индексации в robots.txt
Содержание:
- Для чего нужен запрет индексации
- Закрытие контента от индексации при помощи Javacascript
- Работа с файлом robots.txt
- robots.txt в WordPress
- Пример настройки файла robots.txt
- Настройка файла robots.txt: основные директивы
- Robots.txt для Яндекса и Google
- Контент
- Что такое файл robots.txt
- Как закрыть страницу от индексации?
- Правильный robots.txt для wordpress
- Страницы сайта
Для чего нужен запрет индексации
Существует множество причин для полного и частичного запрета. Разберем по порядку.
-
Нежелание участвовать в поиске. Самая банальная причина. Вы просто не хотите, что бы сайт участвовал в результатах поиска.
-
Сайт находится в разработке. Робот индексирует сайт всегда, вне зависимости от того, находится он в разработке или уже закончен.
Поэтому, если работы проводятся не на локальном хостинге, то необходимо запретить поисковым системам индексировать сайт до тех пор, пока он не будет готов. Вот лишь ряд причин, почему необходимо скрывать от поисковика все, что еще не доделали.-
В процессе разработки размещается демо контент, уникальность которого крайне низка. Видеть такой материал поисковая система не должна.
-
Сайт разрабатывается без наполнения и окончательной структуры. Не нужно вводить в заблуждение поисковую систему, иначе ресурс будет признан не интересным для пользователей еще до того, как его наполнят.
-
Во время технических работ появляется множество дублей страниц. Нельзя допустить попадания их в индекс.
-
Ряд других технических причин.
-
-
Информация не для поиска. На любом сайте существуют страницы и разделы, которые не должны участвовать в поиске. К ним относится система управления сайта, результаты вычислений, дубликаты URL, неуникальный контент, не индексируемые документы и т.д.
- Страницы в разработке. Если сайт уже давно присутствует в поиске, но часть страниц находится на стадии редактирования, то их необходимо скрыть от индексирующего робота.
Закрытие контента от индексации при помощи Javacascript
При использовании данного метода текст, блок, код, ссылка или любой другой контент кодируется в Javascript, а далее Данный скрипт закрывается от индексации при помощи Robots.txt
Такой Метод можно использовать для того, чтобы скрыть например Меню от индексации, для лучшего контроля над распределением ссылочного веса. К примеру есть вот такое меню, в котором множество ссылок на разные категории. В данном примере это — порядка 700 ссылок, если не закрыть которые можно получить большую кашу при распределении веса.

Данный метод гугл не очень то одобряет, так-как он всегда говорил, что нужно отдавать одинаковый контент роботам и пользователям. И даже рассылал письма в средине прошлого года о том, что нужно открыть для индексации CSS и JS файлы.
Подробнее об этом можно почитать тут.
Однако в данный момент это один из самых действенных методов по борьбе с индексацией нежелательного контента.
Точно также можно скрывать обычный текст, исходящие ссылки, картинки, видео материалы, счетчики, коды. И все то, что вы не хотите показывать Роботам, или что является не уникальным.
Работа с файлом robots.txt
Скрыть весь информационный портал или его часть можно, создав пустой документ в формате txt и дав ему название robots. Файл надо поместить в корневую папку сайта. Читать подробнее о robots.txt.
Чтобы закрыть сайт от всех поисковых систем, в документе надо прописать следующее:
Проверить изменения можно, набрав в адресной строке название домена.ru/robots.txt. Если браузер покажет ошибку 404, то документ находится не корневой папке ресурса.
Скрыть отдельную папку поможет следующая команда:
Закрыть определенный файл можно, указав в команде путь к нему:
Обращение к другим поисковым системам
Для запрета индексации веб-сайта другими поисковиками, в редактируемом файле в строке user-agent после двоеточия надо указывать имена их поисковых роботов:
- у Yahoo робот Slurp;
- у Спутника — SputnikBot;
- у Bing — MSNBot.
Закрытие поддомена
Заблокировать поддомен, можно, открыв robots.txt в корневой папке поддомена и указав в robots.txt следующее:
Если нужного файла нет, его следует создать самостоятельно.
robots.txt в WordPress
В WordPress запрос на страницу обрабатывается отдельно и для него «налету» через PHP создается контент файла robots.txt. Поэтому не рекомендуется физически создавать файл robots.txt в корне сайта! Потому что при таком подходе никакой плагин или код не сможет нормально изменить этот файл, а вот динамическое создание контента для страницы позволит гибко его изменять.
Изменить содержание robots.txt можно через:
- Хук robots_txt.
- Хук do_robotstxt.
Рассмотрим как использовать оба хука.
По умолчанию WP 5.5 создает следующий контент для страницы :
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: http://example.com/wp-sitemap.xml
Смотрите do_robots() — как работает динамическое создание файла robots.txt.
Этот хук позволяет дополнить уже имеющиеся данные файла robots.txt. Код можно вставить в файл темы functions.php.
// Дополним базовый robots.txt
// -1 before wp-sitemap.xml
add_action( 'robots_txt', 'wp_kama_robots_txt_append', -1 );
function wp_kama_robots_txt_append( $output ){
$str = '
Disallow: /cgi-bin # Стандартная папка на хостинге.
Disallow: /? # Все параметры запроса на главной.
Disallow: *?s= # Поиск.
Disallow: *&s= # Поиск.
Disallow: /search # Поиск.
Disallow: /author/ # Архив автора.
Disallow: */embed # Все встраивания.
Disallow: */page/ # Все виды пагинации.
Disallow: */xmlrpc.php # Файл WordPress API
Disallow: *utm*= # Ссылки с utm-метками
Disallow: *openstat= # Ссылки с метками openstat
';
$str = trim( $str );
$str = preg_replace( '/^+(?!#)/mU', '', $str );
$output .= "$str\n";
return $output;
}
В результате перейдем на страницу и видим:
User-agent: * Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Disallow: /cgi-bin # Стандартная папка на хостинге. Disallow: /? # Все параметры запроса на главной. Disallow: *?s= # Поиск. Disallow: *&s= # Поиск. Disallow: /search # Поиск. Disallow: /author/ # Архив автора. Disallow: */embed # Все встраивания. Disallow: */page/ # Все виды пагинации. Disallow: */xmlrpc.php # Файл WordPress API Disallow: *utm*= # Ссылки с utm-метками Disallow: *openstat= # Ссылки с метками openstat Sitemap: http://wptest.ru/wp-sitemap.xml
Обратите внимание, что мы дополнили родные данные ВП, а не заменили их. Этот хук позволяет полностью заменить контент страницы
Этот хук позволяет полностью заменить контент страницы .
add_action( 'do_robotstxt', 'wp_kama_robots_txt' );
function wp_kama_robots_txt(){
$lines = [
'User-agent: *',
'Disallow: /wp-admin/',
'Disallow: /wp-includes/',
'',
];
echo implode( "\r\n", $lines );
die; // обрываем работу PHP
}
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Пример настройки файла robots.txt
Давайте разберем на примере, как настроить файл robots.txt. Ниже находится пример файла, значение команд из которого будет подробно рассмотрено в статье.
В данном файле мы видим, что от поисковых систем Яндекс и Google закрыты от индексации все документы на сайте, кроме страницы /test.html
Остальные поисковые системы могут индексировать все документы, кроме:
- документов в разделах /personal/ и /help/
- документа по адресу /index.html
- документов, адреса которых включают параметр clear_cache=Y
Последние две команды требуют отдельного внимания.
Командой /index.html закрыт от индексации дубль главной страницы сайта. Как правило, главная страница доступна по двум адресам:
- site.com
- site.com/index.html или site.com/index.php
Если не закрыть второй адрес от индексации, то в поиске может появиться две главных страницы!
Команда Disallow: /*?clear_cache=Y закрывает от индексации все страницы, в адресах которых используется последовательность символов ?clear_cache=Y. Часто различный функционал на сайте, например, сортировки или формы подбора добавляют к адресам страниц различные параметры, из-за чего генерируется множество страниц-дублей. Закрывая дубли с параметрами от индексации, Вы решаете проблему попадания дублей в базу поисковых систем.
Посмотрите, какие страницы необходимо закрывать от индексации, в статье про проведение технического аудита сайта.
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
Директива User-agent: * обозначает, что команды ниже предназначены для всех роботов, для которых нет персональных команд в файле.
Важно соблюдать последовательность команд в файле. В начале прописываются команды для конкретных роботов (Yandex, Googlebot и т.д.), потом – для всех остальных.. Существуют другие директивы, которые используется реже
Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь
Disallow:
Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи).
Allow:
Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow.
Host:
Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом.
Sitemap:
В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте.
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: *Disallow: / | Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: *Disallow: /Allow: /test.html | Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
 Доступная для пользователей ссылка
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Контент
Проблемы, связанные с закрытием контента на сайте:
Страница оценивается поисковыми роботами комплексно, а не только по текстовым показателям. Увлекаясь закрытием различных блоков, часто удаляется и важная для оценки полезности и ранжирования информация.
Приведём пример наиболее частых ошибок:
– прячется шапка сайта. В ней обычно размещается контактная информация, ссылки. Если шапка сайта закрыта, поисковики могут не узнать, что вы позаботились о посетителях и поместили важную информацию на видном месте;
Зачем на сайте закрывают часть контента?
Обычно есть несколько целей:
– сделать на странице акцент на основной контент, убрав из индекса вспомогательную информацию, служебные блоки, меню;
– сделать страницу более уникальной, полезной, убрав дублирующиеся на сайте блоки;
– убрать «лишний» текст, повысить текстовую релевантность страницы.
Всего этого можно достичь без того, чтобы прятать часть контента!У вас очень большое меню?
Выводите на страницах только те пункты, которые непосредственно относятся к разделу.
Много возможностей выбора в фильтрах?
Выводите в основном коде только популярные. Подгружайте остальные варианты, только если пользователь нажмёт кнопку «показать всё». Да, здесь используются скрипты, но никакого обмана нет – скрипт срабатывает по требованию пользователя. Найти все пункты поисковик сможет, но при оценке они не получат такое же значение, как основной контент страницы.
На странице большой блок с новостями?
Сократите их количество, выводите только заголовки или просто уберите блок новостей, если пользователи редко переходят по ссылкам в нём или на странице мало основного контента.
Поисковые роботы хоть и далеки от идеала, но постоянно совершенствуются. Уже сейчас Google показывает скрытие скриптов от индексирования как ошибку в панели Google Search Console (вкладка «Заблокированные ресурсы»). Не показывать часть контента роботам действительно может быть полезным, но это не метод оптимизации, а, скорее, временные «костыли», которые стоит использовать только при крайней необходимости.
Мы рекомендуем:
– относиться к скрытию контента, как к «костылю», и прибегать к нему только в крайних ситуациях, стремясь доработать саму страницу;
– удаляя со страницы часть контента, ориентироваться не только на текстовые показатели, но и оценивать удобство и информацию, влияющую на коммерческие факторы ранжирования;
– перед тем как прятать контент, проводить эксперимент на нескольких тестовых страницах. Поисковые боты умеют разбирать страницы и ваши опасения о снижение релевантности могут оказаться напрасными.
Давайте рассмотрим, какие методы используются, чтобы спрятать контент:
Тег noindex
У этого метода есть несколько недостатков. Прежде всего этот тег учитывает только Яндекс, поэтому для скрытия текста от Google он бесполезен
Помимо этого, важно понимать, что тег запрещает индексировать и показывать в поисковой выдаче только текст. На остальной контент, например, ссылки, он не распространяется
Это видно из самого .
Поддержка Яндекса не особо распространяется о том, как работает noindex. Чуть больше информации есть в одном из обсуждений в официальном блоге.
Вопрос пользователя:
Ответ:

В каких случаях может быть полезен тег:
– если есть подозрения, что страница понижена в выдаче Яндекса из-за переоптимизации, но при этом занимает ТОПовые позиции по важным фразам в Google. Нужно понимать, что это быстрое и временное решение. Если весь сайт попал под «Баден-Баден», noindex, как неоднократно подтверждали представители Яндекса, не поможет;
– чтобы скрыть общую служебную информацию, которую вы из-за корпоративных ли юридических нормативов должны указывать на странице;
– для корректировки сниппетов в Яндексе, если в них попадает нежелательный контент.
Скрытие контента с помощью AJAX
Это универсальный метод. Он позволяет спрятать контент и от Яндекса, и от Google. Если хотите почистить страницу от размывающего релевантность контента, лучше использовать именно его. Представители ПС такой метод, конечно, не приветствую и рекомендуют, чтобы поисковые роботы видели тот же контент, что и пользователи.
Технология использования AJAX широко распространена и если не заниматься явным клоакингом, санкции за её использование не грозят. Недостаток метода – вам всё-таки придётся закрывать доступ к скриптам, хотя и Яндекс и Google этого не рекомендуют делать.
Что такое файл robots.txt
Если robots.txt найден, то прочитывает все директивы, а в конце видит адрес файла sitemap.xml. Дальше робот, в соответствии с картой сайта, обходит все материалы предоставленные для индексации. Делает он это в пределах какого-то ограниченного промежутка времени. Именно поэтому, если вы создали сайт на несколько тысяч страниц и выложили его целиком, то робот просто не успеет обойти все страницы за один заход. И в индекс попадут только те, которые он успел просмотреть. А ходит робот по всему сайту и тратит на это свое время. И не факт что в первую очередь он будет просматривать именно те странички, которые вы так ждёте в результатах поиска.

Если робот файл robots.txt не находит, то считает, что индексировать разрешено всё. И начинает шарить по всем закаулкам. Сделав полную копию всего, что ему удалось найти, он покидает ваш сайт, до следующего раза. Как вы понимаете, после такого обшаривания в базу индекса поисковика попадает всё, что надо и всё, что не надо. То что надо вы знаете — это ваши статьи, страницы, картинки, ролики и т.д. А вот чего индексировать не надо?
Для WordPress это оказывается очень важный вопрос. Ответ на него затрагивает и ускорение индексации содержимого вашего сайта, и его безопасность. Дело в том, что всю служебную информацию индексировать не надо. А файлы WordPress вообще желательно спрятать от чужих глаз. Это уменьшит вероятность взлома вашего сайта.
WordPress создаёт очень много копий ваших статей с разными адресами, но одним и тем же содержанием. Выглядит это так:
//название_сайта/название_статьи,
//название_сайта/название_рубрики/название_статьи,
//название_сайта/название_рубрики/название_подрубрики/название_статьи,
//название_сайта/название_тега/название_статьи,
//название_сайта/дата_создания_архива/название_статьи
С тегами и архивами вообще караул. К скольким тегам привязана статья, столько копий и создаётся. При редактировании статьи, сколько архивов в разные даты будет создано, столько и новых адресов с практически похожим содержанием появится. А есть ещё копии статей с адресами для каждого комментария. Это вообще просто ужас.
Огромное количество дублей поисковые системы оценивают как плохой сайт. Если все эти копии проиндексировать и предоставить в поиске то вес главной статьи размажется на все копии, что очень плохо. И не факт, что будет показана в результате поиска именно статья с главным адресом. Следовательно надо запретить индексирование всех копий.
WordPress оформляет картинки как отдельные статьи без текста. В таком виде без текста и описания они как статьи выглядят абсолютно некорректно. Следовательно нужно принять меры чтобы эти адреса не попали в индекс поисковиков.
Почему же не надо всё это индексировать?
Как закрыть страницу от индексации?
Если нужно скрыть только одну страницу, то в файле robots нужно будет прописать другой код:
User-agent: *
Disallow: /category/kak-nachat-zarabatyvat
Во второй строчке вам нужно указать адрес страницы, но без названия домена. Как вариант, вы можете закрыть страницу от индексации, если пропишите в её коде:
<META NAME=»ROBOTS» CONTENT=»NOINDEX»>
Это более сложный вариант, но если нет желания добавлять строчки в robots.txt, то это отличный выход. Если вы попали на эту страницу в поисках способа закрытия от индексации дублей, то проще всего добавить все ссылки в robots.
Как закрыть от индексации ссылку или текст?
Здесь тоже нет ничего сложного, нужно лишь добавить специальные теги в код ссылки или окружить её ими:
<noindex>
<a rel=»nofollow» href=»http://Workion.ru/»>Анкор</a>
</noindex>
Используя эти же теги noindex, вы можете скрывать от поисковых систем разный текст. Для этого нужно в редакторе статьи прописать этот тег.
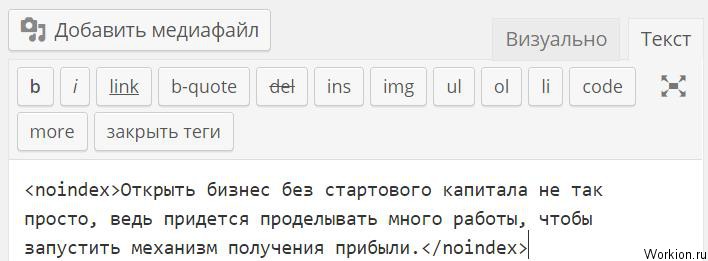
К сожалению, у Google такого тега нет, поэтому скрыть от него часть текста не получится. Самый простой вариант сделать это – добавить изображение с текстом.
Скрывайте от поисковых роботов всё, что не уникально или каким-то образом может нарушать их правила. А если вы решили полностью переделать сайт, то обязательно закрывайте его от индексации, чтобы боты не индексировали внесенные изменения до того, как вы над ними поработаете и всё протестируете.
Вам также будет интересно: — Скорость сайта – важный фактор — Почему Яндекс не индексирует сайт? — Оригинальные тексты для защиты от Yandex
Правильный robots.txt для wordpress
Теперь давайте перейдем непосредственно к содержимому файла robots.txt для сайта wordpress. Какие директивы в нем должны присутствовать обязательно. Примерное содержание файла robots.txt для wordpress, учитывая его особенности приведено ниже:
User-agent: * Disallow: /wp-login.php Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: */*comments Disallow: */*category Disallow: */*tag Disallow: */trackback Disallow: */*feed Disallow: /*?* Disallow: /?s= Allow: /wp-admin/admin-ajax.php Allow: /wp-content/uploads/ Allow: /*?replytocom User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: */comments Disallow: */*category Disallow: */*tag Disallow: */trackback Disallow: */*feed Disallow: /*?* Disallow: /*?s= Allow: /wp-admin/admin-ajax.php Allow: /wp-content/uploads/ Allow: /*?replytocom Crawl-delay: 2,0 Host: site.ru Sitemap: http://site.ru/sitemap.xml
Страницы сайта
Для успешного продвижения важно не только избавиться от лишней информации на страницах, но и очистить поисковый индекс сайта от малополезных мусорных страниц.
Во-первых, это ускорит индексацию основных продвигаемых страниц сайта. Во-вторых, наличие в индексе большого числа мусорных страниц будет негативно влиять на оценку сайта и его продвижение
Сразу перечислим страницы, которые целесообразно прятать:
– страницы оформления заявок, корзины пользователей;
– результаты поиска по сайту;
– личная информация пользователей;
– страницы результатов сравнения товаров и подобных вспомогательных модулей;
– страницы, генерируемые фильтрами поиска и сортировкой;
– страницы административной части сайта;
– версии для печати.
Рассмотрим способы, которыми можно закрыть страницы от индексации.
Закрыть в robots.txt
Это не самый лучший метод.
Во-первых, файл robots не предназначен для борьбы с дублями и чистки сайтов от мусорных страниц. Для этих целей лучше использовать другие методы.
Во-вторых, запрет в файле robots не является гарантией того, что страница не попадёт в индекс.
Вот что Google пишет об этом в своей справке:

Работе с файлом robots.txt посвящена статья в блоге Siteclinic «Гайд по robots.txt: создаём, настраиваем, проверяем».
Метатег noindex
Чтобы гарантированно исключить страницы из индекса, лучше использовать этот метатег.
Рекомендации по синтаксису у Яндекса и Google отличаются.
Ниже приведём вариант метатега, который понимают оба поисковика:
<meta name="robots" content="noindex, nofollow">
Важный момент!
Чтобы Googlebot увидел метатег noindex, нужно открыть доступ к страницам, закрытым в файле robots.txt. Если этого не сделать, робот может просто не зайти на эти страницы.
Выдержка из рекомендаций Google:

Заголовки X-Robots-Tag
Существенное преимущество такого метода в том, что запрет можно размещать не только в коде страницы, но и через корневой файл .htaccess.
Этот метод не очень распространён в Рунете. Полагаем, основная причина такой ситуации в том, что Яндекс этот метод долгое время не поддерживал.
В этом году сотрудники Яндекса написали, что метод теперь поддерживается.

Ответ поддержки подробным не назовёшь))). Прежде чем переходить на запрет индексации, используя X-Robots-Tag, лучше убедиться в работе этого способа под Яндекс. Свои эксперименты на эту тему мы пока не ставили, но, возможно, сделаем в ближайшее время.
Подробные рекомендации по использованию заголовков X-Robots-Tag от Google.
Защита с помощью пароля
Этот способ Google рекомендует, как наиболее надёжный метод спрятать конфиденциальную информацию на сайте.

Если нужно скрыть весь сайт, например, тестовую версию, также рекомендуем использовать именно этот метод. Пожалуй, единственный недостаток – могут возникнуть сложности в случае необходимости просканировать домен, скрытый под паролем.
Исключить появление мусорных страниц c помощью AJAX
Речь о том, чтобы не просто запретить индексацию страниц, генерируемых фильтрами, сортировкой и т. д., а вообще не создавать подобные страницы на сайте.
Например, если пользователь выбрал в фильтре поиска набор параметров, под которые вы не создавали отдельную страницу, изменения в товарах, отображаемых на странице, происходит без изменения самого URL.
Сложность этого метода в том, что обычно его нельзя применить сразу для всех случаев. Часть формируемых страниц используется для продвижения.
Например, страницы фильтров. Для «холодильник + Samsung + белый» нам нужна страница, а для «холодильник + Samsung + белый + двухкамерный + no frost» – уже нет.
Поэтому нужно делать инструмент, предполагающий создание исключений. Это усложняет задачу программистов.
Использовать методы запрета индексации от поисковых алгоритмов
«Параметры URL» в Google Search Console
Этот инструмент позволяет указать, как идентифицировать появление в URL страниц новых параметров.

Директива Clean-param в robots.txt
В Яндексе аналогичный запрет для параметров URL можно прописать, используя директиву Clean-param.
Почитать об этом можно .
Канонические адреса, как профилактика появления мусорных страниц на сайте
Этот метатег был создан специально для борьбы с дублями и мусорными страницами на сайте. Мы рекомендуем прописывать его на всём сайте, как профилактику появления в индексе дубле и мусорных страниц.
Инструменты точечного удаления страниц из индекса Яндекса и Google
Если возникла ситуация, когда нужно срочно удалить информацию из индекса, не дожидаясь, пока ваш запрет увидят поисковые работы, можно использовать инструменты из панели Яндекс.Вебмастера и Google Search Console.
В Яндексе это «Удалить URL»:

В Google Search Console «Удалить URL-адрес»:
