Словоёб
Содержание:
- Как обновить Словоеб
- Сбор семантического ядра на программе словоЕБ
- Что такое Словоеб простыми словами
- Парсинг поисковых фраз в Словоебе
- Другие возможности
- Что такое Словоеб — пара слов для новичков
- Дополнительные функции Словоёба
- Приступаем к работе
- Настройки Словоеба
- Как работать в Словоеб
- Сбор ключевых слов
- Как правильно пользоваться Словоеб
- Заключение
- Заключение
- Заключение
Как обновить Словоеб
Постепенно мы подошли к вопросу о том, как обновить Словоеб. Это бесплатный продукт, у которого нет технической поддержки, и обновляется он нечасто. Последний раз он обновился в связи с изменениями в Yandex.Wordstat, из-за которых Словоеб перестал корректно работать.
Обновление Словоеба – задача не самая простая. Поэтому у многих пользователей часто возникает вопрос, как обновить данную программу, – это связано с тем, что у нее нет не то что автообновления, у Словоеба нет никакой кнопки для обновления. Но если разобраться и следовать нашей инструкции, оказывается, что задача не такая сложная, как может показаться изначально.
Чтобы обновить Словоеб, необходимо:
Теперь у вас есть последняя версия Словоеба. Старую версию можно удалить, только не забудьте перенести настройки со старой версии программы на новую.
Удачного обновления.
Сбор семантического ядра на программе словоЕБ
Семантическое ядро сайта, а также его сбор на примере программы словоЕБ.
Блогеры и SEO-специалисты ценят важность, уникальность и качество контента
Также для продвижения блога или сайта, увеличения читателей их необходимы правильно найденные ключевые слова, по которым читатель сможет быстро найти нужный ему источник, привлечь его внимание
Семантическое ядро — набор ключевых слов для статьи
Правильно составленное семантическое ядро сайта сможет увеличить число посетителей ресурса, что повлечет за собой увеличение рейтинга ресурса. Неверно выбранные ключевики принесут серьезный вред ресурсу.
Будем выполнять сбор ядра с помощью программы словоЕБ. Она имеет такие возможности:
- •выполнять как «плоский», так и «объемный» отбор, применяя службу Yandex.Wordstat;
- •показывает раскладку, зависимую от репутации запросов в разных поисковиках.
Программный продукт может использовать прокси-сервер и разрешает обработку вручную капчи Яндекса, так и с помощью специальных серверов.
Использование программы СловоЕБ для парсинга ключевых слов
• После установки продукта на компьютер, необходимо открыть программу и в ней создать новый проект.
• Обязательно указываем регион который Вам необходим сбора ключевых слов. Это меню находится с права внизу.
• Не забываем указать логин и пароль от аккаунта на Яндекс (зарегистрироваться можно тут). Необходимо для авторизации на сервере Яндекс Вордстат.
• После небольшой настройки, мы модем начать собирать семантику, делается это в два клика. Нажимаем кнопку «Пакетный сбор фраз из левой колонки». Открываться окошко, в котором мы пишем ключевые слова которые нам интересны, например «натяжные потолки».
Нажимаем кнопу «Начать сбор» и ожидаем когда программа остановит свою работу…
•После окончания процесса парсинга появляется список с поисковыми запросами, в котором указываются варианты фраз, а также количество точных вхождений.
Где пятая колонка (частотность) является частотой запроса в месяц по данным Яндекс Вордстатат.
• Затем указываются стоп слова в соответствующем окне. Они помогают исключить ненужные запросы. Например, для парсинга запроса «натяжные потолки», (если мы делаем коммерческую направленность) можно указать в качестве стоп-слов «отзывы» и «фото». Эти слова будут минус словами для Яндекс Директ и объявление по ним показываться не будут, а соответственно и бюджет будет цел.
•В таблицу попадают некоторое число ненужных запросов, которые можно отметить с помощью выпадающего меню удалить.
После чего мы вручную просматриваем ключевые слова которые на подходят, а которые не подходят отправляем в стоп-слова. Очистив всё от нежелательных слов, вы получите чистое семантическое ядро с которым можно работать как в продвижении сайта, так и в контекстной рекламе.
Кроме этого есть возможность выяснить сезонность, другие параметры запросов. Проверить конкурентность можно используя, поисковик сайта Яндекса, проанализировав топ сайтов, по выбранному запросу.
Что такое Словоеб простыми словами
Если вам известно, что представляет собой программа и для чего она нужна, то можете переходить к следующей части статьи. Данное вступление больше подойдет новичкам и нижеописанная инструкция по настройке поможет правильно выставить все параметры приложение.
Смотрите, для того чтобы пользователи приходили на ваш сайт и читали ваши статьи, надо чтобы эти самые статьи отвечали на их запросы, которые они вводят в поисковой строке Яндекса или Гугла. Если ваша запись не будет содержать в тексте этого запроса, то с высокой долей вероятности статья, которую вы написали не будет располагаться в ТОП-10 поисковой выдачи, и следовательно не принесет вам желаемого трафика.
Поэтому надо обязательно включать в текст ключевые слова.
В статистике Яндекса и Google есть огромная база всех ключевых слов (запросов пользователей). Программа Словоеб извлекает из этих баз ключи, которые необходимо использовать для продвижения сайтов.
При парсинге SlovoEB посылает множественные запросы в Яндекс-Вордстат для определения самих ключей и их количества (частотности), т.е. сколько раз их вводили в поиск. Все эти данные сохраняются в программе для дальнейшей обработки.
Таким образом, с использованием программы, за несколько минут можно насобирать тысячи ключевиков. Конечно, можно это сделать и вручную, но сколько времени вы на это потратите? Думаю, что не одну неделю, кропотливой и однообразной работы за компьютером.
Как вы поняли из вышесказанного самые распространенные программы для парсинга на сегодняшний день – это бесплатный СловоЕБ и платный Key Collector. Об их отличиях читайте далее.
Парсинг поисковых фраз в Словоебе
Познакомившись с интерфейсом этой замечательной программы и проставив все нужные настройки, пора переходить к процессу парсинга поисковых запросов из сервиса статистики Яндекса. Далее я расписал пошаговый план сбора будущих ключевых слов в Словоебе. Для примера использовал данные Вордстата по запросу «инфобизнес».
Создаем новый проект (или открываем готовый). В самом начале парсинга нужно сделать свой проект, в котором будут находиться нужные нам поисковые фразы по заданным словам. Обычно каждый проект у меня называется по одной теме.
Указываем стоп-слова. Если мы знаем, какие слова мы не хотели бы видеть в спарсенных поисковых запросах, то их необходимо прописать. Например, для коммерческого сайта этими словами будут «бесплатно», «халява», «скачать» и т.д. Таким образом мы облегчаем процесс сбора будущих ключевиков.
Выбираем регион продвижения. Для того, чтобы получить реальные параметры спарсенных поисковых запросов, необходимо задать нужный регион (аналогичный в сервисе Вордстат). Например, если Ваш блог продвигается по всей России, то в программе необходимо назначить такую же географическую область. Обычно я использую регион «Москва» или «Россия». В данном примере взят второй вариант. Выбрав регион, нажимаем левую кнопку парсинга Вордстата (кнопка №5) и получаем таблицу данных с поисковыми запросами и базовыми частотностями:
Фильтруем полученные запросы. Когда процесс сбора всех поисковых запросов закончился, мы должны пробежаться по ним и удалить те фразы, которые не подходят для нашей тематики. Поверьте, в каждой теме таких слов бывает достаточно. Но их обязательно нужно удалить, потому что они никак не дадут нам ключевые слова для продвижения нашего блога. Чтобы удалить их, сначала надо их выделить в таблице (с помощью чек-боксов):
Затем подводим мышку к нашей таблице с поисковыми фразами, нажимаем ее правую кнопку и в выпадающем меню выбираем соответствующую команду удаления:
Таким образом на выходе мы получаем уже тематические слова по нашим заданным фразам со своими базовыми частотностями. Теперь можно получить и другие параметры поисковых фраз, благодаря которым мы сможем выбрать самые качественные будущие ключевые слова.
Собираем точные частотности. На этом этапе парсинга нашей задачей является получение уточняющих параметров запросов от пользователей поисковых систем — они будут нужны при отборе качественных ключевых слов. Для этого нажимаем кнопку по сбору частотностей (на картинке интерфейса — элемент под номером 7) и выбираем из появившегося меню строку «Собрать частотности !» (картинка справа).
Удаляем слова-пустышки. После того, как в таблице данных наши спарсенные поисковые фразы получат свое значение точной частотности, необходимо удалить из нее так называемые слова-пустышки (точная частотность которых крайне мала и обычно имеет значение от 0 до 2). Удалить можно таким же способом, который показан выше по тексту.
В итоге мы получаем таблицу с данными частотностей для каждого полученного из поиска запроса. Теперь можно сделать ряд дополнительных действий (узнать конкуренцию по версии Словоеба, определить самую релевантную страницу по каждому ключевику) или экспортировать полученные поисковые фразы для дальнейшей обработки.
Таким образом, мы прошли весь процесс парсинга левой колонки Вордстата. Если нам необходимо для расширения тематики узнать дополнительные слова, можно воспользоваться парсингом правой колонки (процесс сбора запросов там такой же, какой мы сейчас рассмотрели).
Другие возможности
У Словоеба есть возможность задавать регион поиска, домен поисковой системы (Google.ru, google.com):
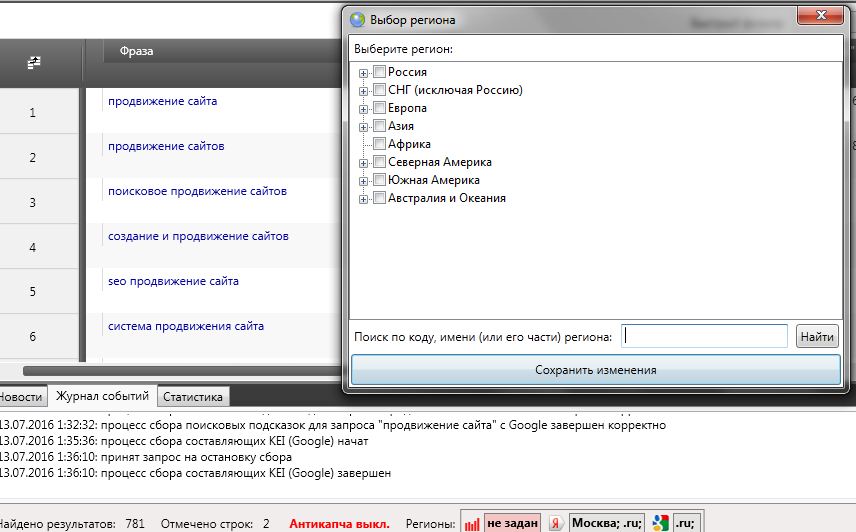
Также в программе можно проверять позиции вашего сайта по ключевым фразам и определять релевантные страницы.

Словоеб в колонках отображает и другую полезную информацию, которую стоит учитывать. Например, количество главных страниц сайтов в ТОП-10 по запросу или количество в ТОП-10 страниц, которые содержат ключевую фразу (проверяется в Яндекс и в Google).
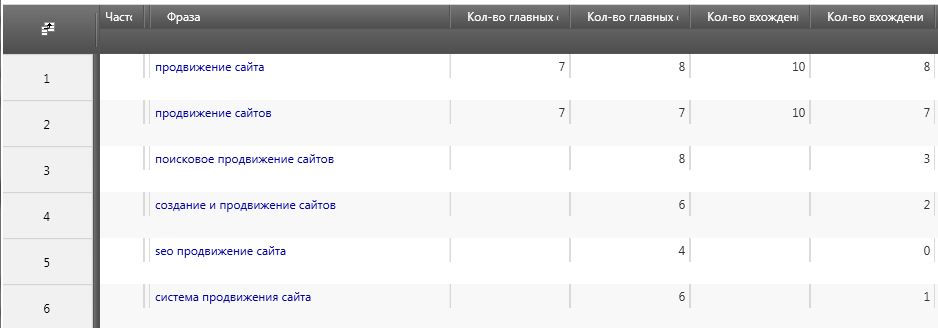
Видно, что по запросу «Продвижение сайтов» в ТОП-10 Яндекса находится 10 сайтов с прямым вхождением в заголовке страницы, а в Google таких только 8. Зато количество главных страниц одинаково – по семь.
В целом, возможностей Словоеба вполне хватит большинству оптимизаторов. У платных программ функционал шире, но он нужен далеко не всем. Но даже не слишком богатый функционал Словоеба дает очень много пищи для размышлений и облегчает поисковое продвижение сайта. Эта программа относится к тем, которые однозначно можно рекомендовать использовать при составлении семантического ядра.
Что такое Словоеб — пара слов для новичков
Настройка рекламы в интернете часто делается через так называемые «ключевые слова». Это запросы, которые пользователи вводят в поисковые системы, чтобы найти то, что им надо. И мы используем эти ключевые слова для того, чтобы показывать конкретным людям нашу конкретную рекламу.
Например, для настройки контекстной рекламы Яндекс-Директ нам надо подобрать запросы, по которым будет показываться наша реклама над результатами поисковой выдачи. Для SEO нам тоже надо правильно подобрать ключевой запрос, под который мы будем оптимизировать нашу статью, чтобы она вышла в ТОП Яндекса или Гугла.
Для подбора ключевых слов вы можете использовать общедоступный сервис Вордстат от Яндекса. Но там вся работа происходит вручную, и отнимает много времени и сил. Соответственно, умельцы придумали специальные программы — парсеры. Эти программы в автоматическом режиме посылают запросы к Яндекс-Вордстат и показывают вам результаты. Это называется парсинг.
При правильном обращении с такими программами, вы можете собрать тысячи ключевых слов буквально за 10-15 минут. Вручную вы бы потратили на это недели.
Самые известные программы парсеры на сегодняшний день — это КейКоллектор и Словоеб. Словоеб, кстати, был первым. Потом к нему добавили разные функции и начали продавать за деньги под именем «КейКоллектор». Но Словоеб остался, и вы можете его совершенно бесплатно скачать с официального сайта.
Кстати, сейчас это уже Словоеб 2.0 — улучшенный и дополненный. Его интерефейс практически ничем не отличается от КейКоллектора. Только у последнего больше настроек для SEO продвиженцев. Но для обычных смертных функций Словоеба хватает с избытком.
Как я уже писал выше, единственная сложность со Словоебом — это его настройка. И если вы уже скачали и установили программу — давайте сразу перейдем к настройке.
Дополнительные функции Словоёба
Кроме основных функций по сбору семантического ядра, есть также дополнительные: сбор данных сезонности, вычисление KEI, анализ релевантных страниц, сбор позиций сайта в ПС.
Сезонность указывает на то, зависит ли количество запросов от времени года, месяца.
Показатель KEI, может указать, по каким запросам из всего вашего списка лучше продвигаться. Это соотношение числа запросов по определенному «ключу» и количества продвигаемых по нему страниц конкурентов. Т.е. значение KEI покажет какие ключевые слова более удачны для продвижения, по каким из них и траффик хороший, и конкуренция невысокая.
Анализ релевантных страниц и сбор позиций в ПС – полезные опции для готового сайта. Первая поможет определить какие страницы больше подходят для заданного ключевого слова. Вторая – позицию сайта по определенному запросу.
Геозависимость. Перед началом сбора запросов, вам нужно указать регион, если ваш ресурс зависит от географии. Соответственно, программа будет показывать частотность и прочие значения по тому региону, который вы зададите. Если вас интересуют все пользователи интернетом, то оставьте эту графу без изменений.
Хочу предупредить также о том, что иногда могут случаться сбои программы. Это может произойти после обновления алгоритмов работы Яндекса. О том, как обновить Словоёб, подумают его разработчики. А вам нужно будет только скачать его новую версию по той же ссылке, которая указана в начале статьи.
На этом все. Мной были приведены основные принципы функционирования данного сервиса, и, надеюсь, вам будет проще разобраться с тем, как работать с программой Словоёб. Она вам послужит хорошим помощником при составлении семантического ядра и анализа ключевых слов.
Приступаем к работе
Приступаем к подбору запросов.
Новый проект
Начинаем работу с создания нового проекта. Их может быть несколько — каждый сохраняется в отдельном файле. Есть возможность переключаться между ними.
По умолчанию проекты сохраняются в папку с программой.
Следующим шагом будет настройка региона. При ориентировании на какой-то определённый из них понадобится статистика именно по нему. Выбор его устанавливается галочкой в нужном месте:
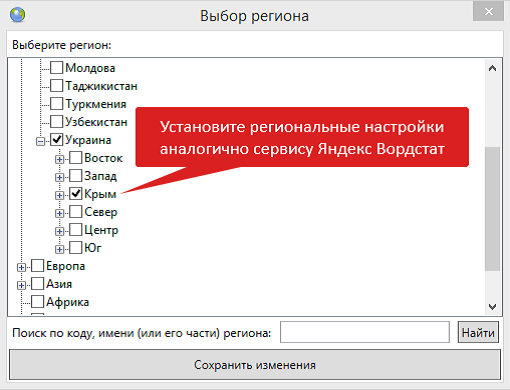
Установите региональные настройки
Собираем запросы
Вызываем пакетный сбор в соответствии с картинкой:
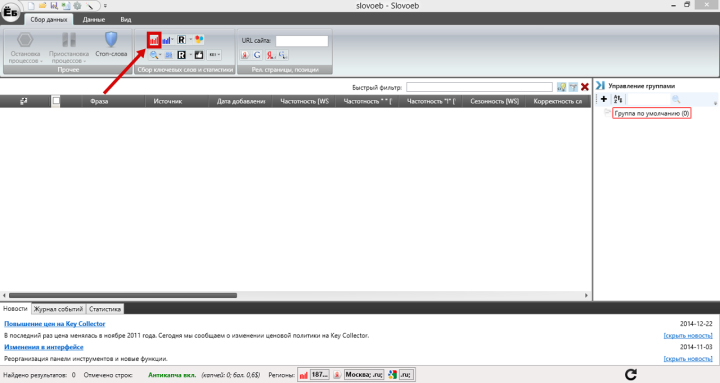
Перейдите в меню сбора запросов
В открывшемся диалоге вводятся ключевые слова для подбора запросов.
По нажатию «Начать сбор» приложение начнёт их собирать.
После парсинга нужно отфильтровать запросы от не интересующих нас сочетаний и формулировок.
Это делается стоп-словами. По нажатию кнопки «Стоп-слова» нужно потом выбрать «Добавить списком». В следующем открывшемся диалоге нужно перечислить (каждое с новой строки) те, которые не хотите видеть в своём поисковом запросе.
Например, если не интересуют слова «скачать», «торрент», «новая версия», «последняя версия», так как распространение программы постановщиком задачи не происходит, то это будет выглядеть так:
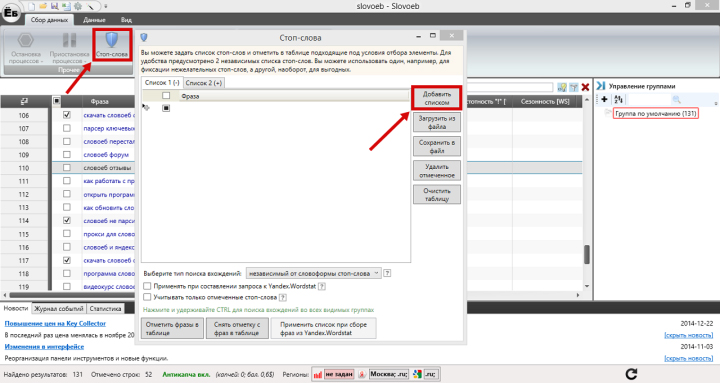
Здесь можно исключить те слова и выражения, которые нас не интересуют
После введения стоп-слов нужно активировать кнопку «Отметить … в таблице» внизу слева этого же окна.
Переместившись на вкладку «Данные» «Удаляем отмеченные фразы».
После этого нужно ещё вручную почистить кривые запросы, не учтённые в стоп-словах.
Проработка частотности
Для сбора информации по частотности запросов с помощью операторов нужно нажать кнопку с изображением лупы и выбрать команду «Собрать частотности вида * *.
После программной проверки слова сортируются по колонке «Частотность * *», удаляются нулевые и микрочастотные.
И уже после этого будет получено семантическое ядро.
Его можно экспортировать в Excel (по кнопке вверху слева), можно сохранить в группу (справа — работа с группами).
Надеемся, что наша пошаговая инструкция оказала вам помощь в правильном подборе слов-ключей.
Оставляйте свои комментарии и делитесь новыми знаниями со своими друзьями.
Настройки Словоеба
Кроме того, стоит оставить 1 поток с основного IP-адреса. Если задействованы прокси, нужно использовать столько же потоков, сколько прокси-серверов.
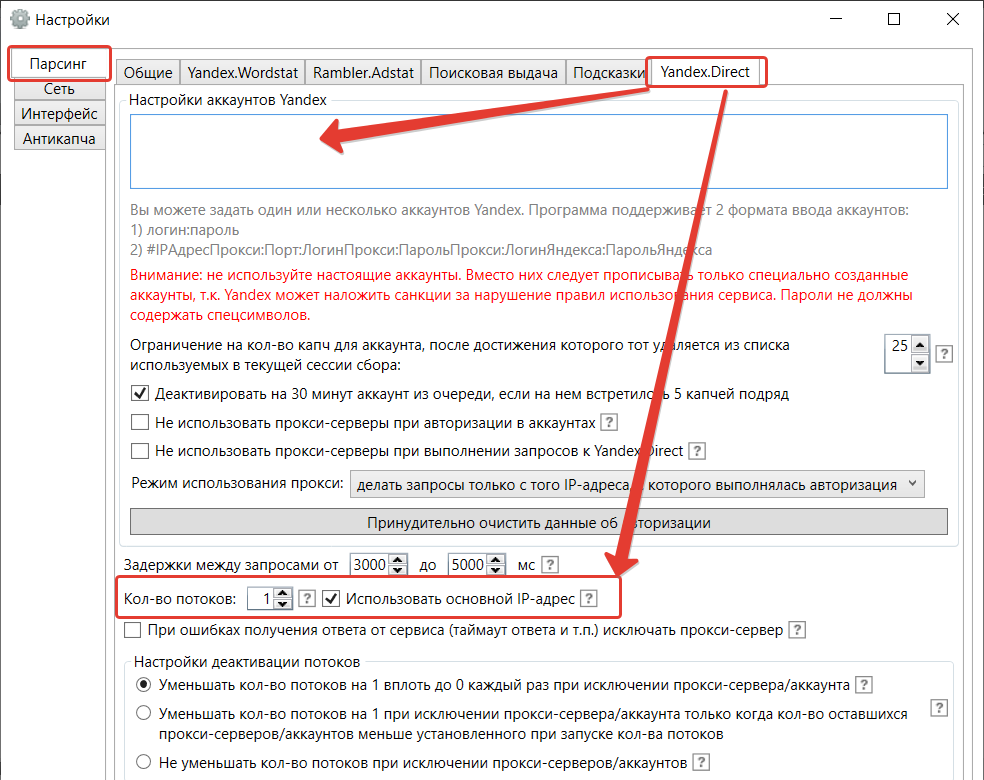
Остальные настройки необязательны.
К примеру, Антикапча желательна, но может не использоваться, если парсинг идет с одного основного IP-адреса.
Если ядро большое (5 000 запросов и более), для ускорения можно использовать прокси. Тогда нужно добавить и антикапчу.
Для сбора частот из Вордстата можно использовать и шаред прокси, и бесплатные сервера, если они не забанены Яндексом.
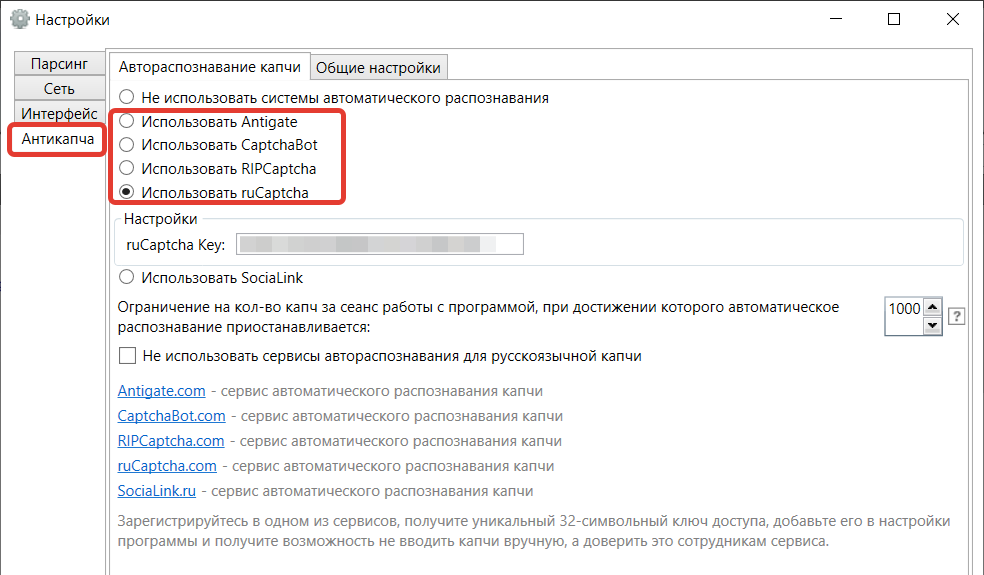
Настройки антикапчи в Словоебе
Для подключения антикапчи нужно зарегистрироваться в одном из поддерживаемых сервисов:
- Antigate (anti-captcha.com).
- CaptchaBot.
- RIPCaptcha.
- RuCaptcha.
Остается добавить API ключ системы в поле «Key» и сохранить изменения.
Прокси в Словоебе
Прокси помогают ускорить процесс сбора частотностей в разы.
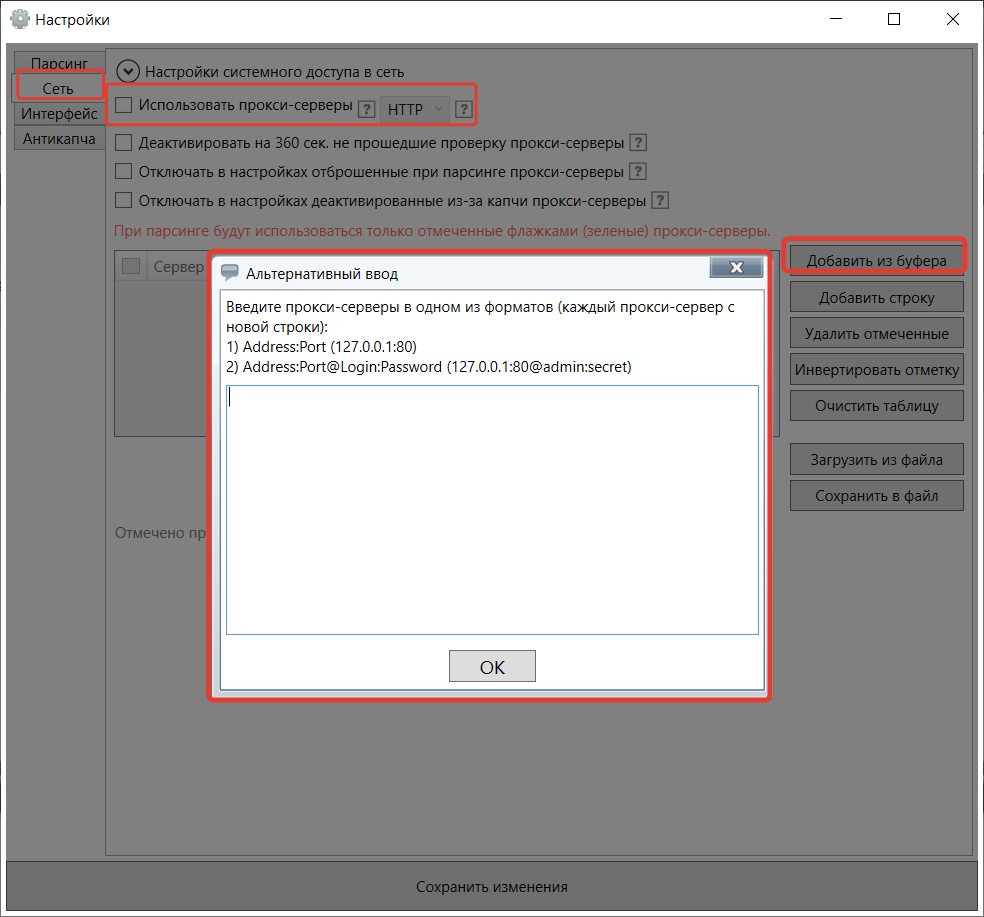
Чтобы добавить прокси, зайдите в настройки, перейдите в раздел «Сеть», поставьте галочку напротив «Использовать прокси-серверы».
Нажмите «Добавить из буфера» и вставьте прокси в формате: АдресПрокси:Порт@Логин:Пароль. Нажмите «Ок» и «Сохранить изменения».
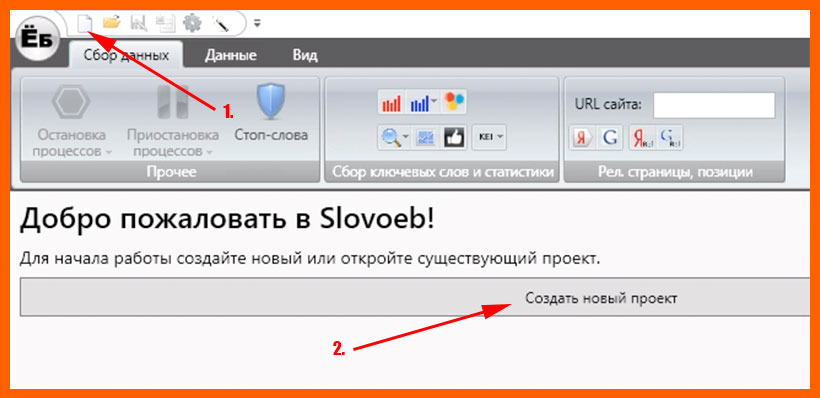
Как работать в Словоеб
Первое, что необходимо сделать – создать новый проект.
Перед нами откроется окно программы. Сверху основная вкладка «Сбор данных», в которой слева расположены основные кнопки управления. Кнопка «Стоп-слова» позволяет игнорировать минус-слова при сборе семантики.
Например, вы продвигаете коммерческий сайт только по городу Москва, и вам не нужны другие города. Для этого скачивайте составленный мной список всех городов России, удаляете оттуда город Москва и используете в качестве стоп-слов, чтобы почистить свой список запросов.
Далее инструменты для парсинга ключевых фраз, для работы с Вордстатом: правой и левой колонкой, поисковыми подсказками. Кнопки вычисления KEI и сбора частотностей.
Большую часть окна занимает пока еще не заполненное поле с названиями колонок сверху. Здесь будут появляться напарсенные ключевые слова, их частотности и т. д.
Снизу три вкладки:
- Новости, которые порядком устарели.
- Журнал событий – в котором будет отображаться ход выполнения парсинга, появляться ошибки и логи.
- Вкладка «Статистика», будет выводить статистику по ключам.
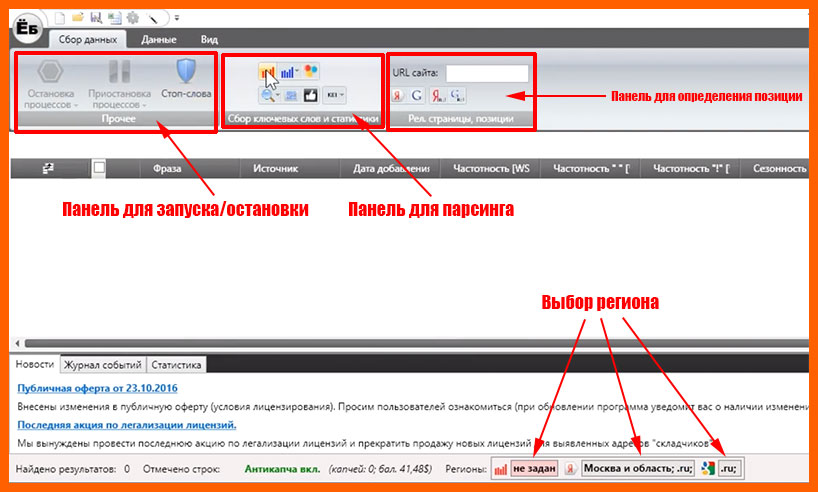
Внизу панель для настройки регионов:
- Яндекс.Вордстат;
- Директ;
Замыкающаяся на себя стрелка поможет вам перезагрузить процесс, если вдруг все зависнет или остановится.
Парсинг запросов
В начале выбираем регион, в нижней панели программы.
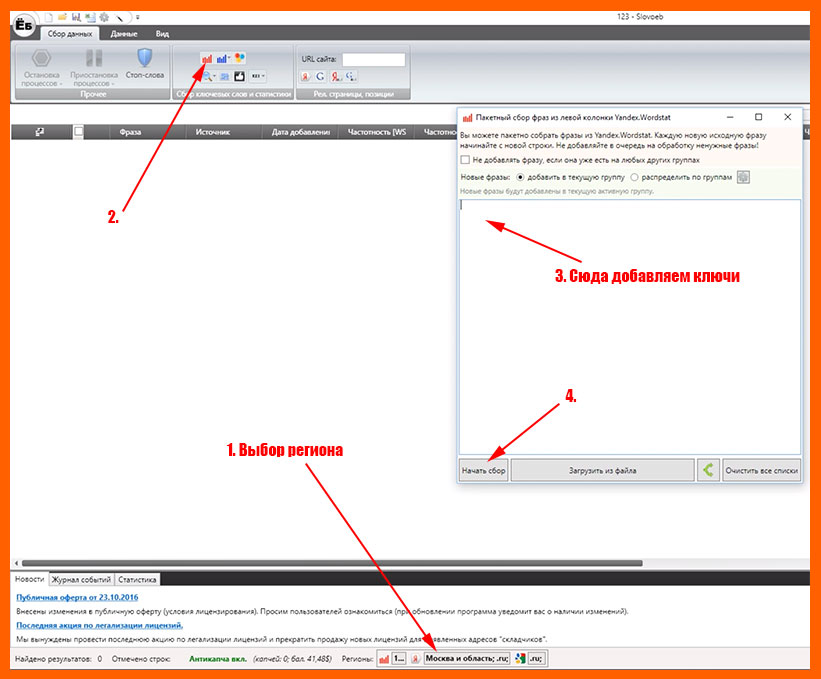
Чтобы добавить слова для парсинга переходим на вкладку «Данные», далее нажимаем на большой зеленый плюс. В появившееся окошко вводим одну или несколько фраз.
Если хотите напарсить фразы из левой колонки Яндекс Вордстат, то для этого на вкладке «Сбор данных» кликните по значку с красными вертикальными полосками. В появившееся окошко добавляете одну или несколько фраз. Потом кликаете «Начать сбор».
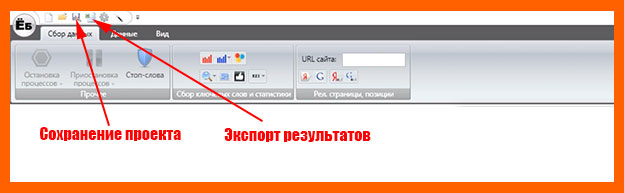
Экспорт результатов
После сбора всех ключей их необходимо экспортировать в excel-файл, кликнув на соответствующую кнопочку вверху окна программы.
Для сохранения всего проекта достаточно кликнуть по дискетке.
Сбор ключевых слов
Сначала создаем новый проект, даем ему имя и сохраняем в нужном месте. Далее выбираем регион, если это нужно.
Следует соблюдать несколько правил пакетного сбора — одно ключевое — одна группа.
Возьмем для примера ключевую фразу – мобильный телефон самсунг.

Открываем в меню сбор фраз из Вордстата, вводим ключевую фразу и нажимаем Начать сбор. Ждем, пока идёт парсинг. За его ходом можно наблюдать во вкладке Журнал событий.

Когда сбор ключей по первому запросу завершается, повторяем эту процедуру для остальных ключевых фраз, если они есть.

Следующий этап, это сбор ключевых слов из правой колонки Яндекс.Вордстата, то есть, из похожих запросов.
Создаем новую группу, которую можно так и назвать – Правая колонка.
Открываем данное меню и вбиваем ключевые фразы. Затем нажимаем Начать сбор.

В результате получаем похожие запросы, из которых можно выбрать несколько подходящих фраз.
Как правильно пользоваться Словоеб
Если вы не против, то я буду показывать процесс работы опять-таки с помощью скриншотов из КейКоллектора. Конечно же вы не против. И давайте тогда рассмотрим например, как собрать ключевые слова для настройки Яндекс-Директа.
Парсинг базового ключа
Первым делом нам надо распарсить наш базовый ключ. Допустим, мы настраиваем рекламу для доставки пиццы на дом. Нашим базовым ключом в этом случае будет «доставка пицца» или просто «пицца». Но ввести просто «пицца» — значит обречь себя на долгую ручную чистку списка ключей от всяких «рецептов пиццы в домашних условиях».
Поэтому давайте возьмем «доставка пицца». Создайте новый проект, и перед началом работы обязательно укажите регион, в котором вы собираетесь рекламироваться.
Если это вся Россия, то ничего не меняйте.
Теперь мы нажимаем на кнопочку парсинга Вордстат и вводим наш базовый ключ.
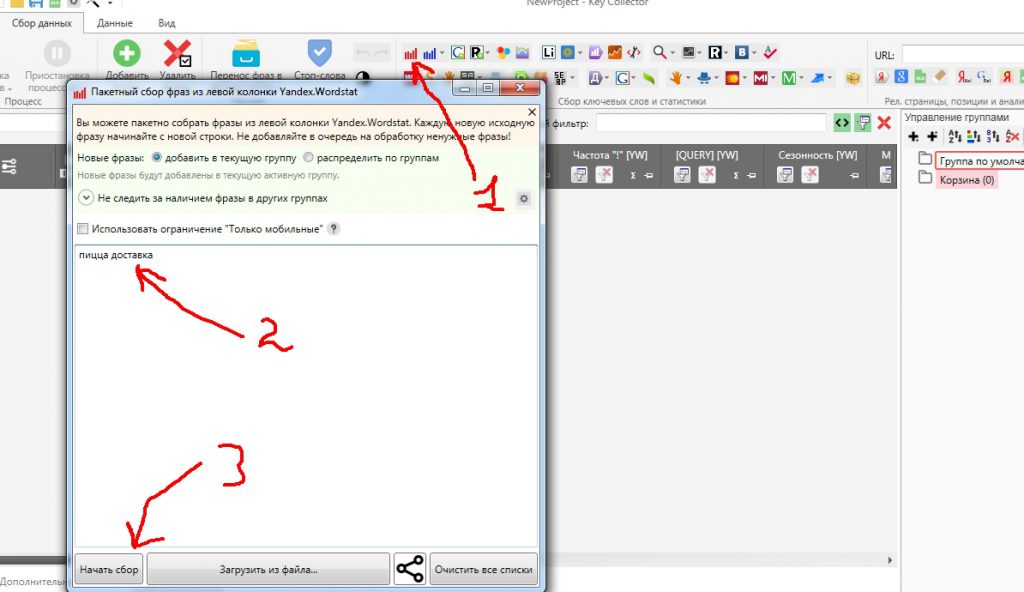
Программа начинает работать, а мы можем пока перекурить и оправиться.
Через некоторое время все процессы остановятся — значит парсинг завершен. И мы увидим список ключевых слов, которые нам подобрал Словоеб.
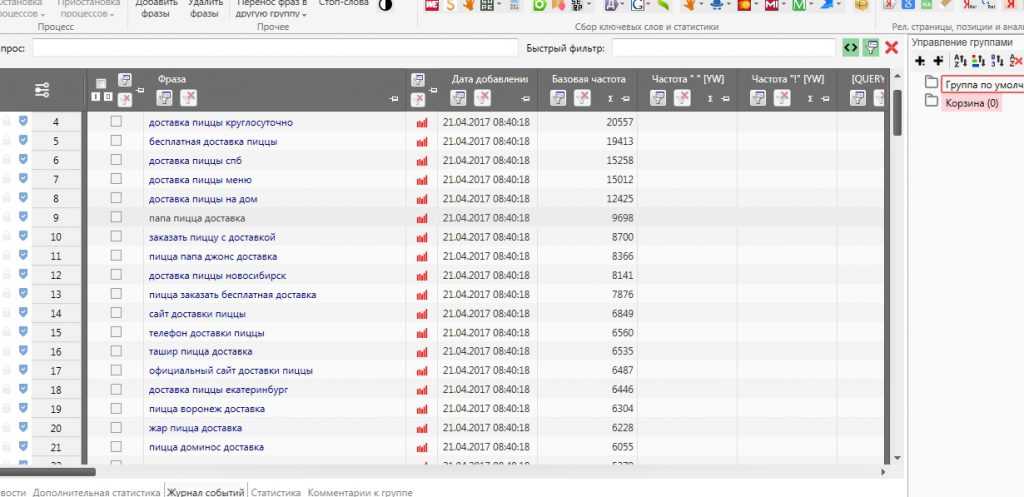
Но при этом он нам показывает только «базовую частотность». То есть мы видим не точное количество запросов в месяц того или иного ключа, а общее количество запросов основного ключа + хвост.
Например, в списке, выданном Словоебом есть основной ключ «Телефон доставки пиццы». И значение — 6560 запросов в месяц. Это значит 1000 запросов «телефон доставки пиццы» + еще 1000 запросов «телефон пицца доставка» + еще и еще.
А нам нужны точные значения, иначе мы никогда не сможем прогнозировать — какое количество трафика в месяц мы получим, и сколько мы с этого сможем заработать.
Поэтому переходим ко второй части парсинга — к Директу.
Узнаем точное количество запросов
Для того, чтобы узнать точное количество запросов к каждому ключу, мы нажимаем на синий значок Яндекс-Директа.
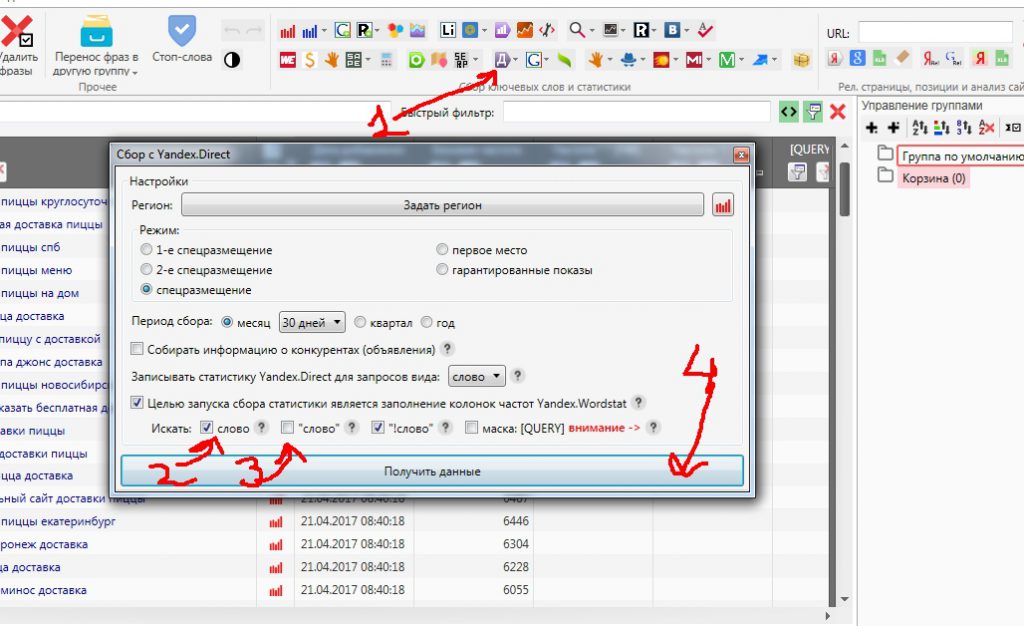
Обратите внимание на галочку «Целью запуска является сбор частотностей для колонок Вордстата». То есть в основном эта функция как раз и используется для того, чтобы узнать точные показатели запросов
Конечно, он вам может показать еще стоимость клика по тому или иному запросу в Директе, но я никогда этим не пользуюсь. Слишком большая нагрузка на программу, и слишком неточные получаются результаты.
Если вам нужны данные по точной словоформе, то можно еще поставить галочку в поле «!». После этого нажимаем «Получить данные» и опять отправляемся пить кофе.
Вот что теперь мы имеем:
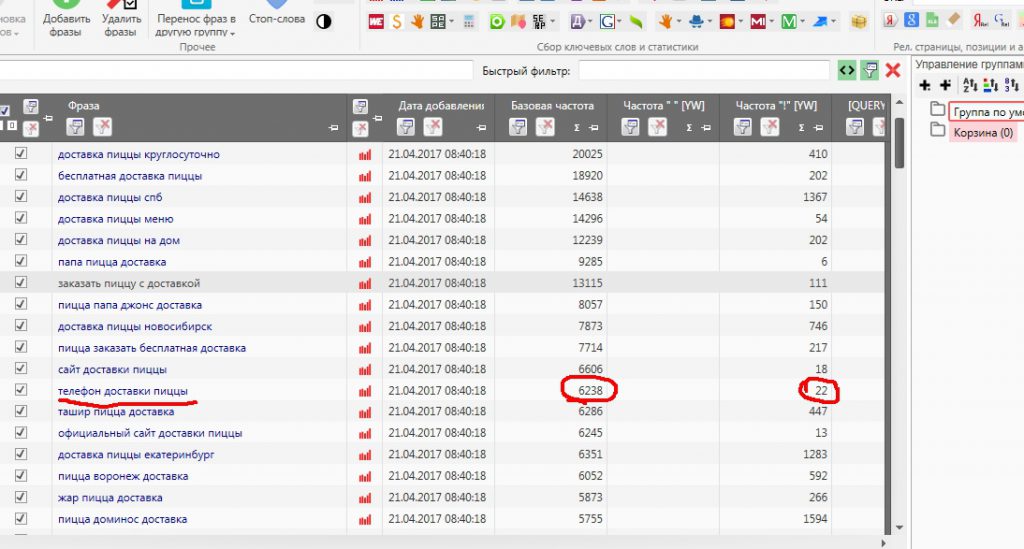
Как вы видите, наш такой перспективный ключ «телефон доставки пиццы» запрашивают на самом деле не шесть тысяч раз в месяц, а всего 22 раза в месяц. А мы-то уже губы раскатали.
Теперь, когда у нас есть объективные результаты, мы можем переходить к следующим этапам настройки. Это будет фильтр слов. То есть нам надо удалять те ключевые запросы, которые нам явно не подходят. Делать это можно прямо в интерфейсе Словоеба, или можете сначла выгрузить результаты в эксель и работать там. Давайте рассмотрим второй вариант.
Экспорт результатов
Для того, чтобы выгрузить полученные данные, нажмите на значок «эксель» в левом верхнем углу интерфейса, и укажите, куда надо сохранить файл.
Когда вы откроете файл, то увидите примерно вот такую картину:
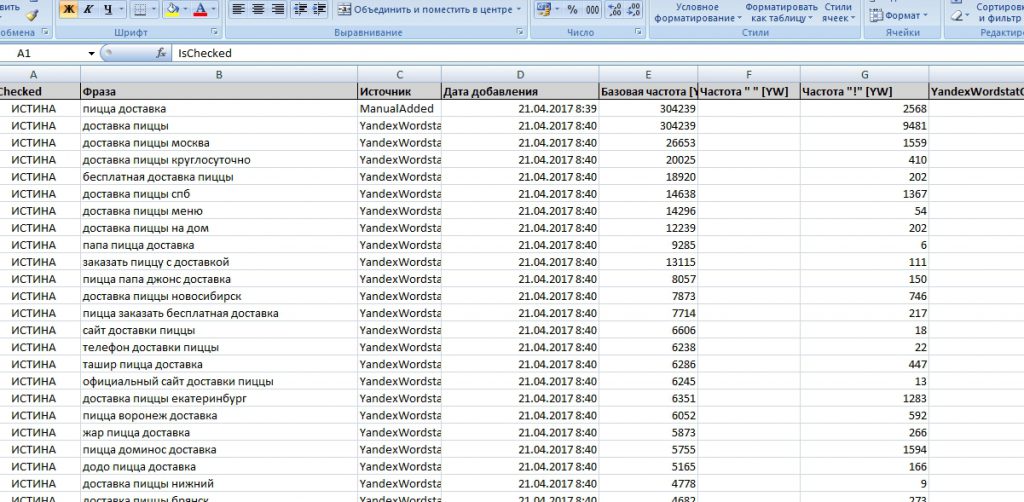
Теперь вы можете спокойно удалять ненужные ключевые запросы, оставляя только те, по которым к вам точно придут клиенты. После этого вам еще надо будет создать рекламные объявления для каждого запроса. Об этом мы уже говорим подробнее в статье «Как самому настроить контекстную рекламу».
Заключение
Словоеб – младший брат KeyCollector’a со значительно урезанным функционалом и тем же интерфейсом. Несмотря на ограниченный функционал, Словоеб – достаточно мощный инструмент с множеством настроек функций, которые он имеет.
Этих функций вполне достаточно, чтобы собрать семантическое ядро для сайта – возможно, не самое полное и качественное, зато бесплатно.
Если говорить о новичках, для них функционала данного продукта на начальных этапах работы более чем достаточно, а когда им станет мало функционала Словоеба, они смогут купить полнофункциональный «комбайн» KeyCollector на официальном сайте.
Из недостатков (если их можно так назвать, ведь продукт бесплатный и предоставляется «как есть») можем отметить отсутствие тех. поддержки и редкие обновления.
Заключение
С помощью программы Словоеб вы можете собрать тысячи ключевых слов буквально за 10 – 15 минут. Вручную вы бы потратили на это несколько дней, а может быть и недель.
Надеюсь, что эта статья поможет вам быстро совладать с этим парсером, и вы начнете сразу начнете делать профессиональные рекламные кампании самостоятельно.
Сохраняйте статью в закладки, чтобы не потерять, и делитесь с друзьями. Мне это будет приятно. Не забудьте скачать мою книгу «Автостопом к миллиону». Там я показываю вам самый быстрый путь с нуля до первого миллиона в интернете (выжимка из личного опыта за 10 лет = )
До скорого!
Ваш Дмитрий Новосёлов
Заключение
Словоеб – младший брат KeyCollector’a со значительно урезанным функционалом и тем же интерфейсом. Несмотря на ограниченный функционал, Словоеб – достаточно мощный инструмент с множеством настроек функций, которые он имеет.
Этих функций вполне достаточно, чтобы собрать семантическое ядро для сайта – возможно, не самое полное и качественное, зато бесплатно.
Если говорить о новичках, для них функционала данного продукта на начальных этапах работы более чем достаточно, а когда им станет мало функционала Словоеба, они смогут купить полнофункциональный «комбайн» KeyCollector на официальном сайте.
Из недостатков (если их можно так назвать, ведь продукт бесплатный и предоставляется «как есть») можем отметить отсутствие тех. поддержки и редкие обновления.