Среднеквадратичное отклонение в excel
Содержание:
- Расчет в Excel
- Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
- Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
- Коэффициент вариации в статистике: примеры расчета
- Вычисление дисперсии
- Примечание. Почему именно квадраты разностей?
- Другие меры разброса
- Как написать коэффициент в экселе
- Понятие корреляции
Расчет в Excel
Рассчитать указанную величину в Экселе можно с помощью двух специальных функций СТАНДОТКЛОН.В (по выборочной совокупности) и СТАНДОТКЛОН.Г (по генеральной совокупности). Принцип их действия абсолютно одинаков, но вызвать их можно тремя способами, о которых мы поговорим ниже.
Способ 1: мастер функций
- Выделяем на листе ячейку, куда будет выводиться готовый результат. Кликаем на кнопку «Вставить функцию», расположенную слева от строки функций.
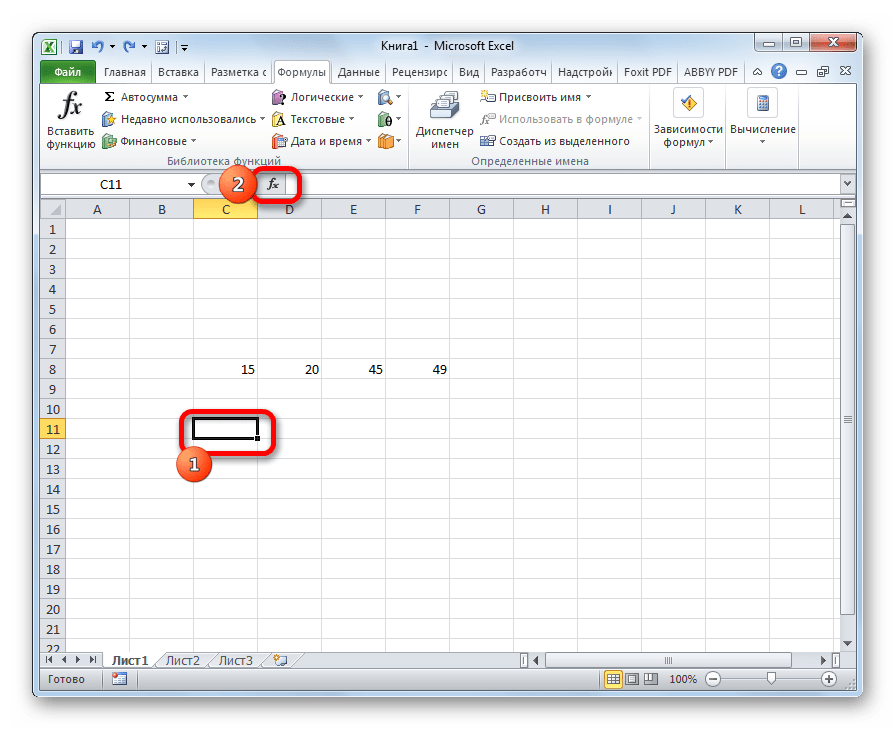
В открывшемся списке ищем запись СТАНДОТКЛОН.В или СТАНДОТКЛОН.Г. В списке имеется также функция СТАНДОТКЛОН, но она оставлена из предыдущих версий Excel в целях совместимости. После того, как запись выбрана, жмем на кнопку «OK».
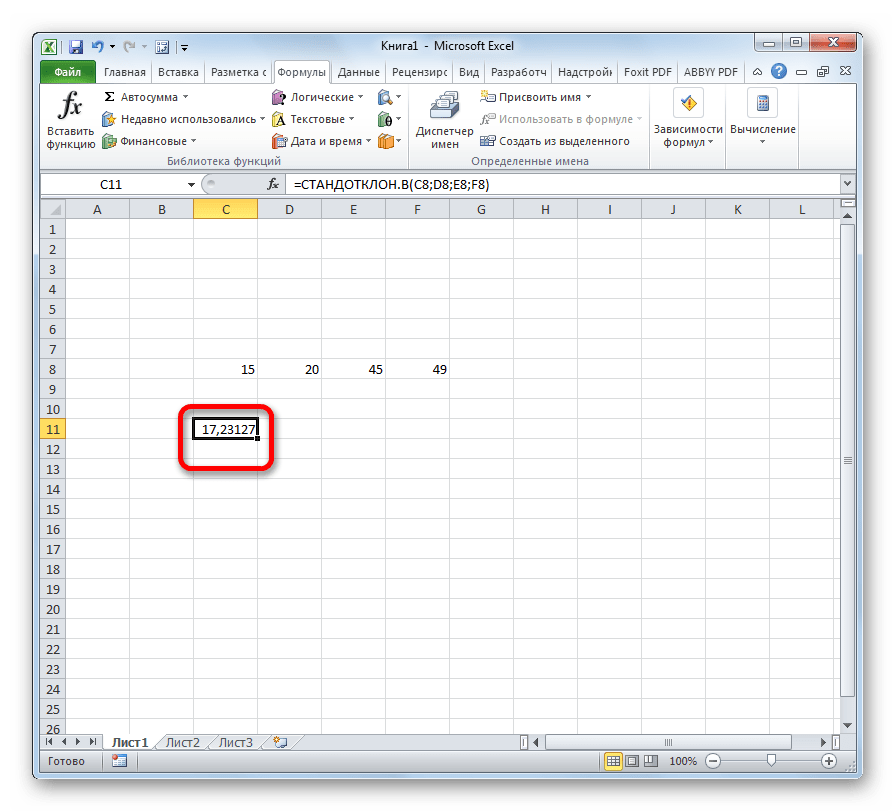
Результат расчета будет выведен в ту ячейку, которая была выделена в самом начале процедуры поиска среднего квадратичного отклонения.
Способ 2: вкладка «Формулы»
Также рассчитать значение среднеквадратичного отклонения можно через вкладку «Формулы».
- Выделяем ячейку для вывода результата и переходим во вкладку «Формулы».
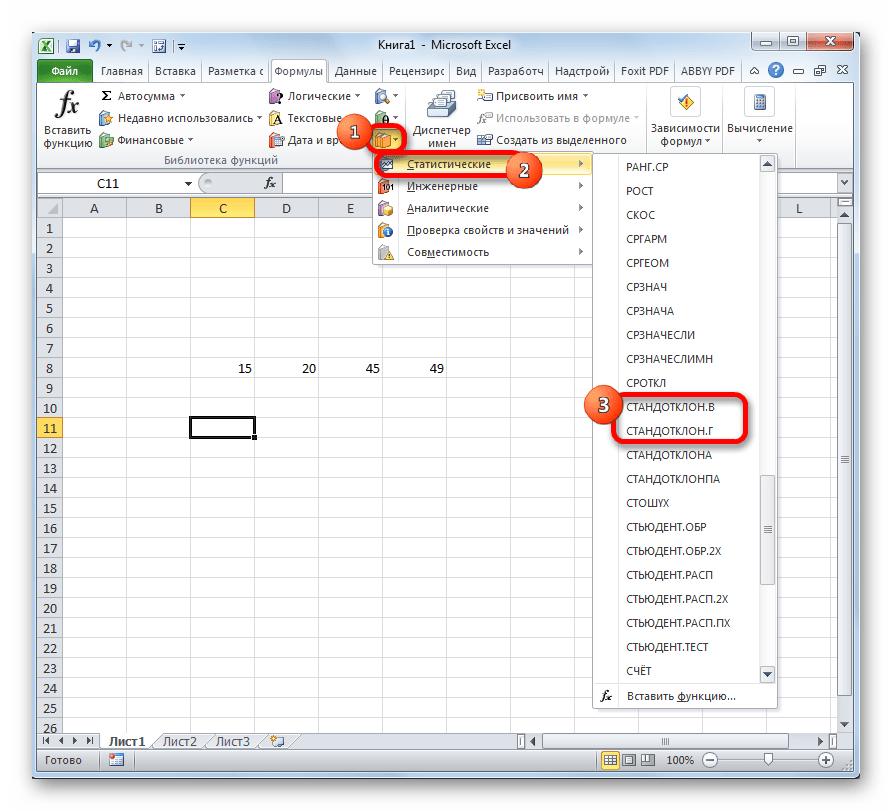
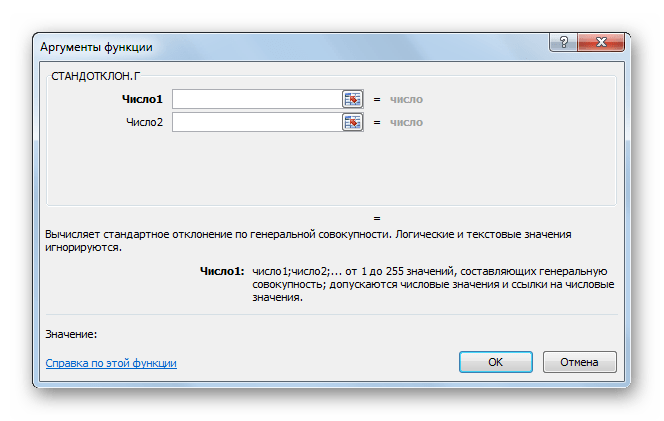
После этого запускается окно аргументов. Все дальнейшие действия нужно производить так же, как и в первом варианте.
Способ 3: ручной ввод формулы
Существует также способ, при котором вообще не нужно будет вызывать окно аргументов. Для этого следует ввести формулу вручную.
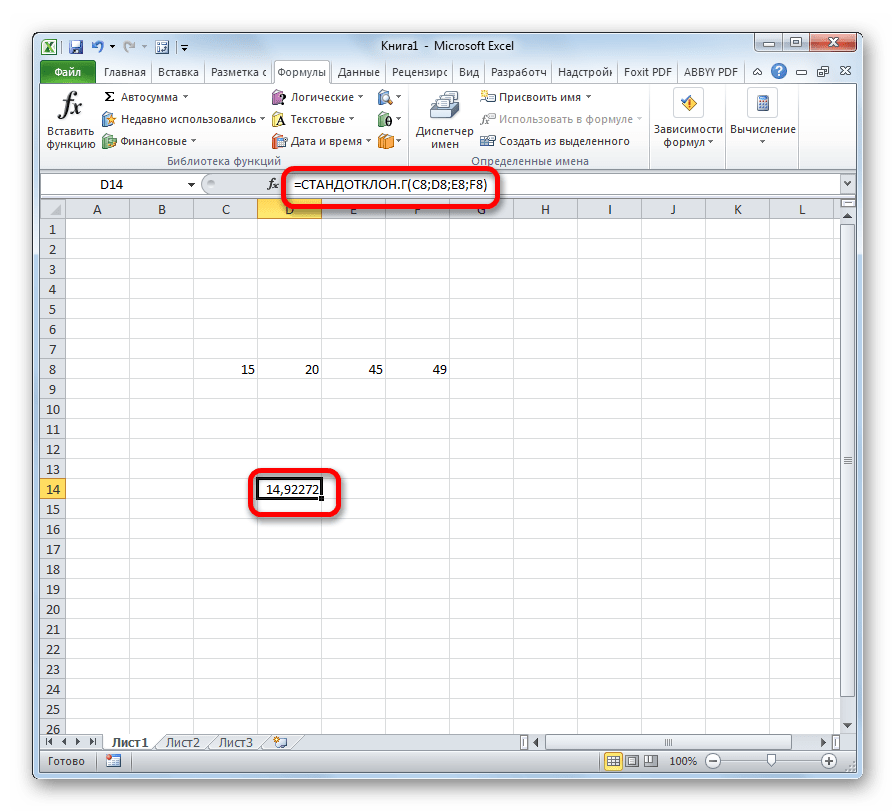
- Выделяем ячейку для вывода результата и прописываем в ней или в строке формул выражение по следующему шаблону:
=СТАНДОТКЛОН.Г(число1(адрес_ячейки1); число2(адрес_ячейки2);…) или =СТАНДОТКЛОН.В(число1(адрес_ячейки1); число2(адрес_ячейки2);…).
Всего можно записать при необходимости до 255 аргументов.
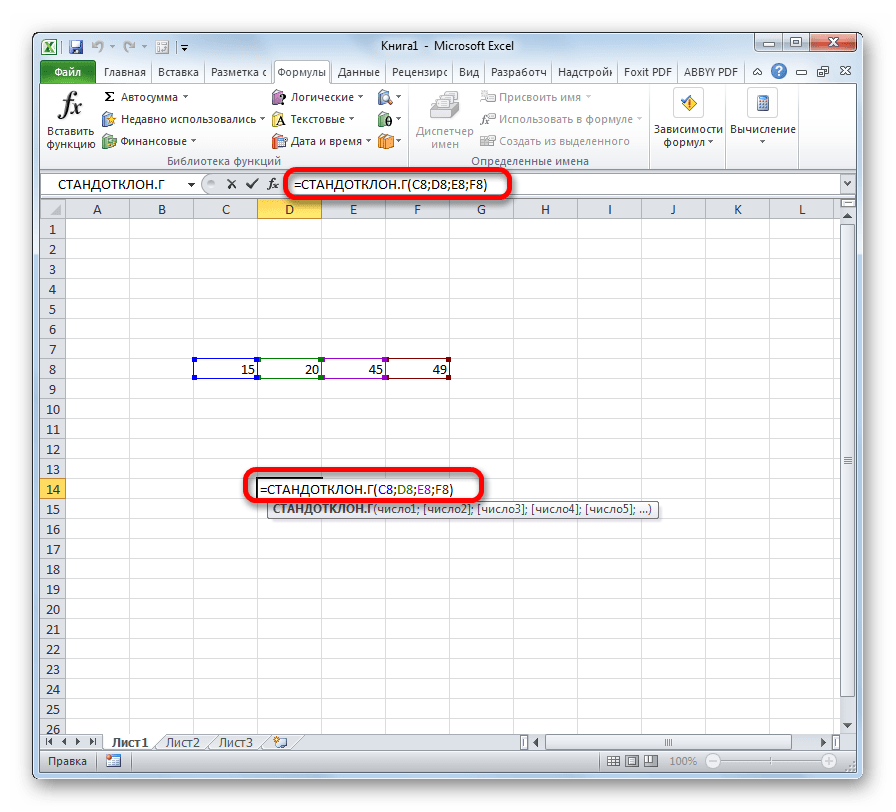
После того, как запись сделана, нажмите на кнопку Enter на клавиатуре.
Как видим, механизм расчета среднеквадратичного отклонения в Excel очень простой. Пользователю нужно только ввести числа из совокупности или ссылки на ячейки, которые их содержат. Все расчеты выполняет сама программа. Намного сложнее осознать, что же собой представляет рассчитываемый показатель и как результаты расчета можно применить на практике. Но постижение этого уже относится больше к сфере статистики, чем к обучению работе с программным обеспечением.
В программе эксель можно посчитать среднеквадратичное отклонение двумя способами: использовать стандартные формулы или воспользоваться специальной функцией. Рассмотрим оба метода расчета и сравним их результаты.
Перед нами таблица, состоящая из двух строк и шести столбцов, на основании этих данных и будем делать расчет.

Первый способ.
Первый шаг. Рассчитаем среднее значение пяти данных показателей, для этого воспользуемся функцией СРЗНАЧ, в ячейке «В3» напишем формулу: =СРЗНАЧ(B2:F2).

Второй шаг. Рассчитаем отклонения каждого показателя от среднего, для этого в ячейке «В4» пишем формулу: =B2-$B$3, знаки доллара ставим, чтобы при копировании данной формулы на другие ячейки, параметр среднего значения всегда вычитался. Копируем соответственно данную формулу на другие ячейки.

Третий шаг. Возведем каждое отклонения от среднего в квадратный корень, для этого в ячейке «В5» пишем формулу: =B4^2, которую копируем на оставшийся диапазон ячеек (с «С5» по «F5»).

Четвертый шаг. Посчитаем сумму квадратных отклонений, для этого в ячейке «В6» напишем формулу =СУММ(B5:F5).

Пятый шаг. У нас все готово, чтобы рассчитать среднеквадратичное отклонения. Для этого нужно сумму отклонений от среднего значения в квадрате (8,8) разделить на количество опытов минус один (5-1) и от получившегося значения изъять квадратный корень. Пишем в ячейке «В8» формулу: =КОРЕНЬ((B6/(5-1))).

В итоге получили цифру равную 1,483
Второй способ.
Программа эксель позволяет избегать такого количества расчетов, а, следовательно, сэкономить время, вам просто нужно воспользоваться для расчета среднеквадратичное отклонения функцией СТАНДОТКЛОН, вы внутри неё указываете диапазон, для которого нужно сделать расчет. В ячейке «В8» пишем формулу =СТАНДОТКЛОН(B2:F2).

В итоге результаты обоих вариантов расчета среднеквадратичного отклонения совпали, а вы выбирайте метод, который наиболее подходит к вам.
Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики
Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра
Формула дисперсии в теории вероятностей имеет вид:
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
s 2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel

Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Расчет дисперсии в Excel
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.
В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
На практике формула стандартного отклонения следующая:
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной.
В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:
Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.
Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Коэффициент вариации в статистике: примеры расчета
Как доказать, что закономерность, полученная при изучении экспериментальных данных, не является результатом совпадения или ошибки экспериментатора, что она достоверна? С таким вопросом сталкиваются начинающие исследователи.Описательная статистика предоставляет инструменты для решения этих задач. Она имеет два больших раздела – описание данных и их сопоставление в группах или в ряду между собой.
- Показатели описательной статистики
- Среднее арифметическое
- Стандартное отклонение
- Коэффициент вариации
- Расчёты в Microsoft Ecxel 2016
Среднее арифметическое
Итак, представим, что перед нами стоит задача описать рост всех студентов в группе из десяти человек. Вооружившись линейкой и проведя измерения, мы получаем маленький ряд из десяти чисел (рост в сантиметрах):
168, 171, 175, 177, 179, 187, 174, 176, 179, 169.
Если внимательно посмотреть на этот линейный ряд, то можно обнаружить несколько закономерностей:
- Ширина интервала, куда попадает рост всех студентов, – 18 см.
- В распределении рост наиболее близок к середине этого интервала.
- Встречаются и исключения, которые наиболее близко расположены к верхней или нижней границе интервала.
Совершенно очевидно, что для выполнения задачи по описанию роста студентов в группе нет необходимости приводить все значения, которые будут измеряться.
Для этой цели достаточно привести всего два, которые в статистике называются параметрами распределения. Это среднеарифметическое и стандартное отклонение от среднего арифметического.
Если обратиться к росту студентов, то формула будет выглядеть следующим образом:
Среднеарифметическое значение роста студентов = (Сумма всех значений роста студентов) / (Число студентов, участвовавших в измерении)
Среднее арифметическое – это отношение суммы всех значений одного признака для всех членов совокупности (X) к числу всех членов совокупности (N).
Если применить эту формулу к нашим измерениям, то получаем, что μ для роста студентов в группе 175,5 см.
Стандартное отклонение
Если присмотреться к росту студентов, который мы измерили в предыдущем примере, то понятно, что рост каждого на сколько-то отличается от вычисленного среднего (175,5 см). Для полноты описания нужно понять, какой является разница между средним ростом каждого студента и средним значением.
На первом этапе вычислим параметр дисперсии. Дисперсия в статистике (обозначается σ2 (сигма в квадрате)) – это отношение суммы квадратов разности среднего арифметического (μ) и значения члена ряда (Х) к числу всех членов совокупности (N). В виде формулы это рассчитывается понятнее:
Значения, которые мы получим в результате вычислений по этой формуле, мы будем представлять в виде квадрата величины (в нашем случае – квадратные сантиметры). Характеризовать рост в сантиметрах квадратными сантиметрами, согласитесь, нелепо. Поэтому мы можем исправить, точнее, упростить это выражение и получим среднеквадратичное отклонение формулу и расчёт, пример:
Таким образом, мы получили величину стандартного отклонения (или среднего квадратичного отклонения) – квадратный корень из дисперсии. С единицами измерения тоже теперь все в порядке, можем посчитать стандартное отклонение для группы:
Получается, что наша группа студентов исчисляется по росту таким образом: 175,50±5,25 см.
Расчёты в Microsoft Ecxel 2016
Можно рассчитать описанные в статье статистические показатели в программе Microsoft Excel 2016, через специальные функции в программе. Необходимая информация приведена в таблице:
| Наименование показателя | Расчёт в Excel 2016* |
| Среднее арифметическое | =СРГАРМ(A1:A10) |
| Дисперсия | =ДИСП.В(A1:A10) |
| Среднеквадратический показатель | =СТАНДОТКЛОН.В(A1:A10) |
| Коэффициент вариации | =СТАНДОТКЛОН.Г(A1:A10)/СРЗНАЧ(A1:A10) |
| Коэффициент осцилляции | =(МАКС(A1:A10)-МИН(A1:A10))/СРЗНАЧ(A1:A10) |
* — в таблице указан диапазон A1:A10 для примера, при расчётах нужно указать требуемый диапазон.
Итак, обобщим информацию:
- Среднее арифметическое – это значение, позволяющее найти среднее значение показателя в ряду данных.
- Дисперсия – это среднее значение отклонений возведенное в квадрат.
- Стандартное отклонение (среднеквадратичное отклонение) – это корень квадратный из дисперсии, для приведения единиц измерения к одинаковым со среднеарифметическим.
- Коэффициент вариации – значение отклонений от среднего, выраженное в относительных величинах (%).
Отдельно следует отметить, что все приведённые в статье показатели, как правило, не имеют собственного смысла и используются для того, чтобы составлять более сложную схему анализа данных. Исключение из этого правила — коэффициент вариации, который является мерой однородности данных.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
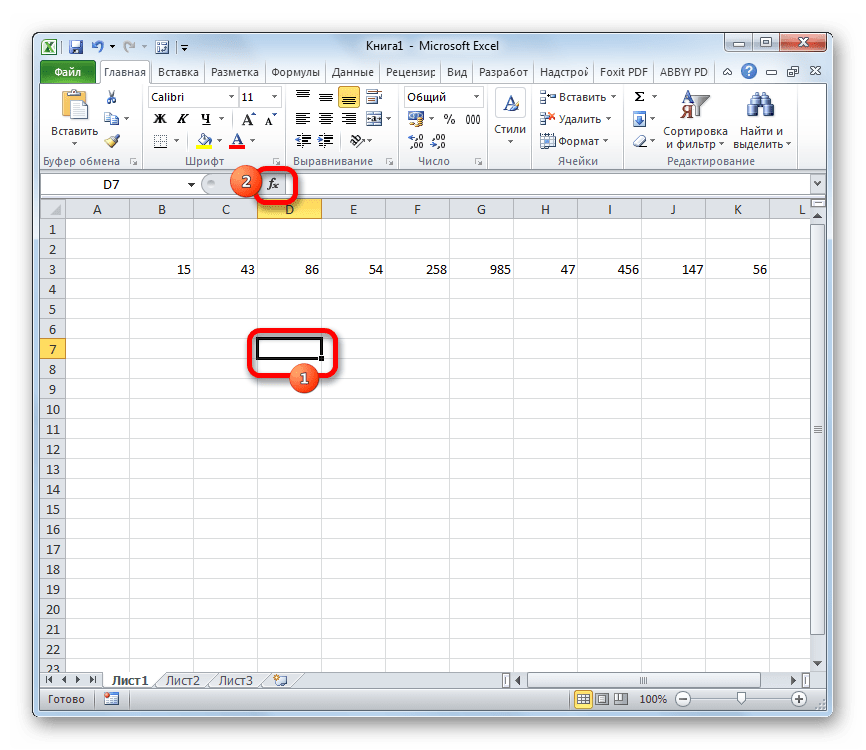
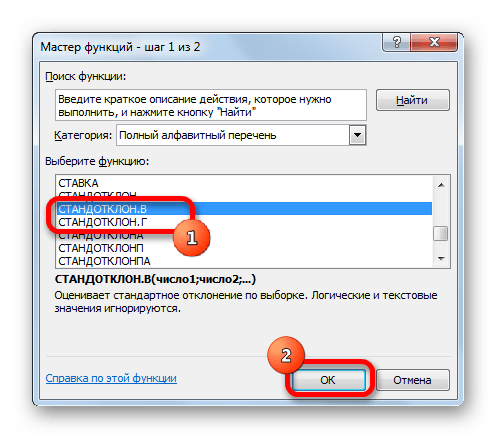
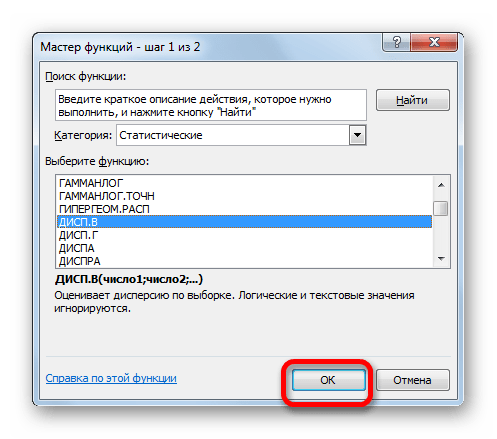
Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
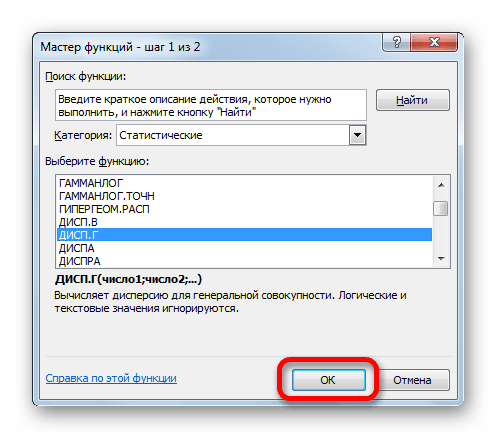
Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
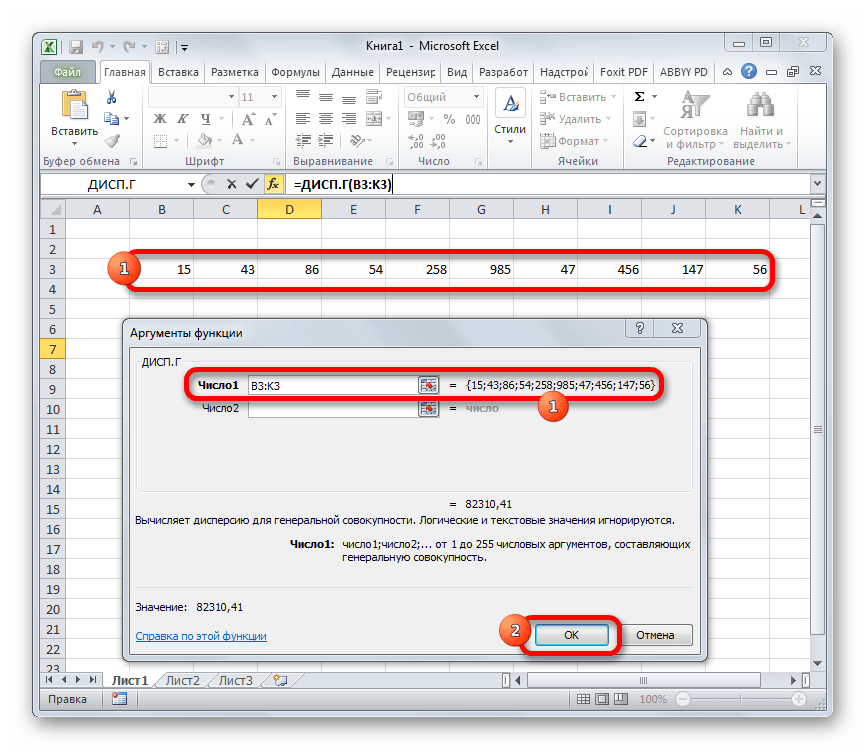
Как видим, после этих действий производится расчет. Итог вычисления величины дисперсии по генеральной совокупности выводится в предварительно указанную ячейку. Это именно та ячейка, в которой непосредственно находится формула ДИСП.Г.
Урок: Мастер функций в Эксель
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.
- Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
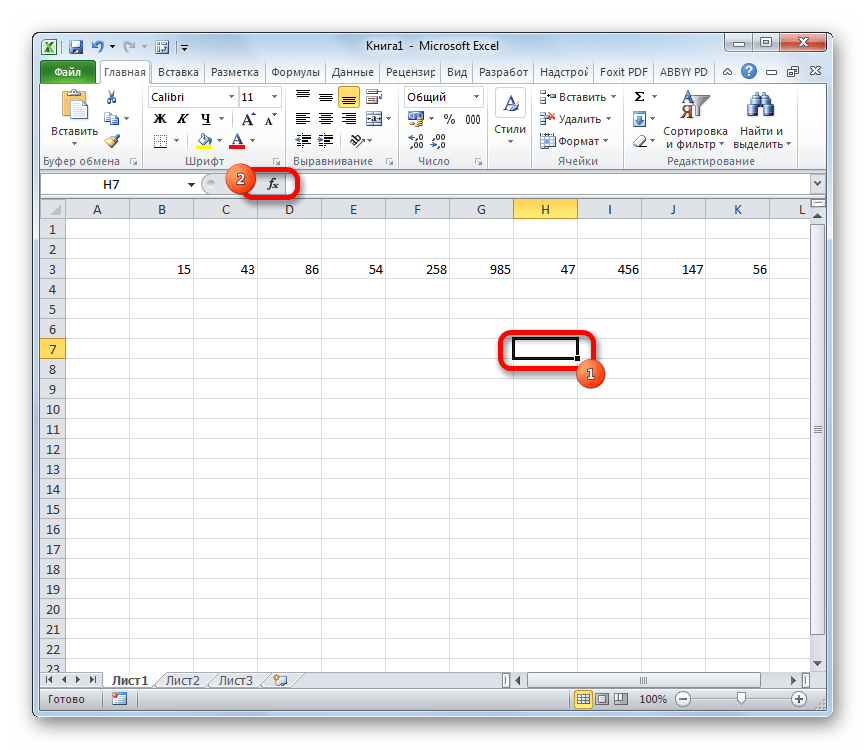
В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
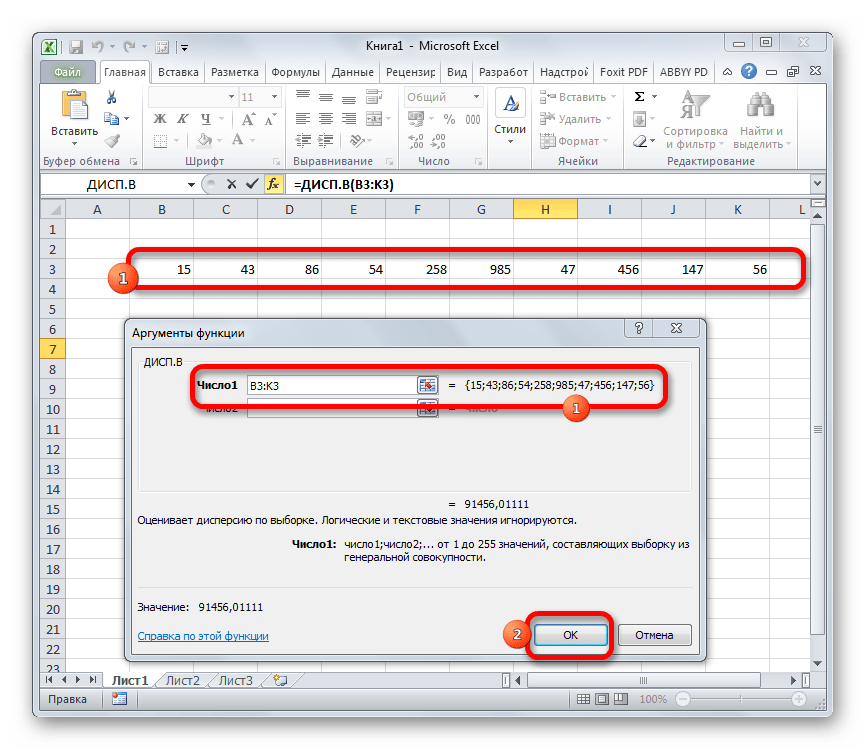
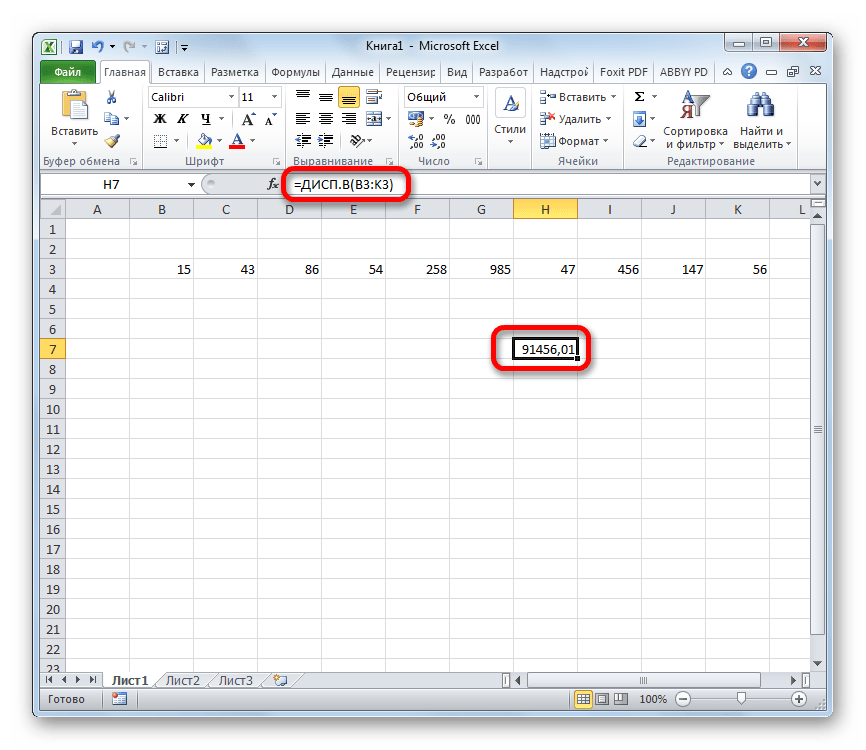
Результат вычисления будет выведен в отдельную ячейку.
Урок: Другие статистические функции в Эксель
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
.
Для второго примера получится:
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
Другие меры разброса
Функция КВАДРОТКЛ()
вычисляет сумму квадратов отклонений значений от их среднего
. Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка
)*СЧЁТ(Выборка
)
, где Выборка
— ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ()
производятся по формуле:

Функция СРОТКЛ()
является также мерой разброса множества данных. Функция СРОТКЛ()
вычисляет среднее абсолютных значений отклонений значений от среднего
. Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка)
, где Выборка
— ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ
()
производятся по формуле:

Необходимо вмешательство менеджмента для выявления причин отклонений.
Для построения контрольной карты я использую исходные данные, среднее значение (μ) и стандартное отклонение (σ). В Excel: μ = СРЗНАЧ($F$3:$F$15), σ = СТАНДОТКЛОН($F$3:$F$15)
Сама контрольная карта включает: исходные данные, среднее значение (μ), нижнюю контрольную границу (μ – 2σ) и верхнюю контрольную границу (μ + 2σ):
Скачать заметку в формате , примеры в формате
Посмотрев на представленную карту, я заметил, что исходные данные демонстрируют вполне различимую линейную тенденцию к снижению доли накладных расходов:
Чтобы добавить линию тренду выделите на графике ряд с данными (в нашем примере – зеленые точки), кликните правой кнопкой мыши и выберите опцию «Добавить линию тренда». В открывшемся окне «Формат линии тренда», поэкспериментируйте с опциями. Я остановился на линейном тренде.
Если исходные данные не разбросаны в соответствии с вокруг среднего значения, то описывать их параметрами μ и σ не вполне корректно. Для описания вместо среднего значения лучше подойдет прямая линейного тренда и контрольные границы, равноудаленные от этой линии тренда.
Линию тренда Excel позволяет построить с помощью функции ПРЕДСКАЗ. Нам потребуется дополнительный ряд А3:А15, чтобы известные значения Х
были непрерывным рядом (номера кварталов такой непрерывный ряд не образуют). Вместо среднего значения в столбце Н вводим функцию ПРЕДСКАЗ:
Стандартное отклонение σ (функция СТАНДОТКЛОН в Excel) вычисляется по формуле:
К сожалению, я не нашел в Excel функции для такого определения стандартного отклонения (по отношению к тренду). Задачу можно решить с помощью формулы массива. Кто не знаком с формулами массива, предлагаю сначала почитать .
Формула массива может возвращать одно значение или массив. В нашем случае формула массива вернет одно значение:
Давайте подробнее изучим, как работает формула массива в ячейке G3
СУММ(($F$3:$F$15-$H$3:$H$15)^2) определяет сумму квадратов разностей; фактически формула считает следующую сумму = (F3 – H3) 2 + (F4 – H4) 2 + … + (F15 – H15) 2
СЧЁТЗ($F$3:$F$15) – число значений в диапазоне F3:F15
КОРЕНЬ(СУММ(($F$3:$F$15-$H$3:$H$15)^2)/(СЧЁТЗ($F$3:$F$15)-1)) = σ
Значение 6,2% есть точка нижней контрольной границы = 8,3% – 2 σ
Фигурные кавычки с обеих сторон формулы означают, что это формула массива. Для того, чтобы создать формулу массива, после ввода формулы в ячейку G3:
H4 – 2*КОРЕНЬ(СУММ(($F$3:$F$15-$H$3:$H$15)^2)/(СЧЁТЗ($F$3:$F$15)-1))
необходимо нажать не Enter, а Ctrl + Shift + Enter. Не пытайтесь ввести фигурные скобки с клавиатуры – формула массива не заработает. Если требуется отредактировать формулу массива, сделайте это так же, как и с обычной формулой, но опять же по окончании редактирования нажмите не Enter, а Ctrl + Shift + Enter.
Формулу массива, возвращающую одно значение, можно «протаскивать», как и обычную формулу.
В результате получили контрольную карту, построенную для данных, имеющих тенденцию к понижению
P.S. После того, как заметка была написана, я смог усовершенствовать формулы, используемые для вычисления стандартного отклонения для данных с тенденцией. Ознакомиться с ними вы можете в Excel-файле
В данной статье я расскажу о том, как найти среднеквадратическое отклонение
. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение
дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом (греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Как написать коэффициент в экселе

Одним из основных статистических показателей последовательности чисел является коэффициент вариации. Для его нахождения производятся довольно сложные расчеты. Инструменты Microsoft Excel позволяют значительно облегчить их для пользователя.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии.
Для расчета стандартного отклонения используется функция СТАНДОТКЛОН.
Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…) = СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.
Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».
Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1».
Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д.
Когда все нужные данные введены, жмем на кнопку «OK»
В предварительно выделенной ячейке отображается итог расчета выбранного вида стандартного отклонения.
Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».
В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».
Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки.
После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».
Результат вычисления среднего арифметического выводится в ту ячейку, которая была выделена перед открытием Мастера функций.
Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий.
Это можно сделать после её выделения, находясь во вкладке «». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный».
После этих действий формат у элемента будет соответствующий.
Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения.
Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда.
Понятие корреляции
Корреляция (от латинского «correlatio» – соотношение, взаимосвязь) – математический термин, который означает меру статистической вероятностной зависимости между случайными величинами (переменными).
Пример: возьмем два вида взаимосвязи:
- Первый – ручка в руке человека. В какую сторону движется рука, в такую сторону и ручка. Если рука находится в состоянии покоя, то и ручка не будет писать. Если человек чуть сильнее надавит на нее, то след на бумаге будет насыщеннее. Такой вид взаимосвязи отражает жесткую зависимость и не является корреляционным. Это взаимосвязь – функциональная.
- Второй вид – зависимость между уровнем образования человека и прочтением литературы. Заранее неизвестно, кто из людей больше читает: с высшим образованием или без него. Эта связь – случайная или стохастическая, ее изучает статистическая наука, которая занимается исключительно массовыми явлениями. Если статистический расчет позволит доказать корреляционную связь между уровнем образованности и прочтением литературы, то это даст возможность делать какие-либо прогнозы, предсказывать вероятностное наступление событий. В этом примере с большой долей вероятности можно утверждать, что больше читают книги люди с высшим образованием, те, кто более образован. Но поскольку связь между данными параметрами не функциональная, то мы можем и ошибиться. Всегда можно рассчитать вероятность такой ошибки, которая будет однозначно невелика и называется уровнем статистической значимости (p).
Примерами взаимосвязи между природными явлениями являются: цепочка питания в природе, организм человека, который состоит из систем органов, взаимосвязанных между собой и функционирующих как единое целое.
Каждый день мы сталкиваемся с корреляционной зависимостью в повседневной жизни: между погодой и хорошим настроением, правильной формулировкой целей и их достижением, положительным настроем и везением, ощущением счастья и финансовым благополучием. Но мы ищем связи, опираясь не на математические расчеты, а на мифы, интуицию, суеверия, досужие домыслы. Эти явления очень сложно перевести на математический язык, выразить в цифрах, измерить. Другое дело, когда мы анализируем явления, которые можно просчитать, представить в виде цифр. В таком случае мы можем определить корреляцию с помощью коэффициента корреляции (r), отражающего силу, степень, тесноту и направление корреляционной связи между случайными переменными.
Сильная корреляция между случайными величинами – свидетельство наличия некоторой статистической связи конкретно между этими явлениями, но эта связь не может переноситься на эти же явления, но для другой ситуации. Часто исследователи, получив в расчетах значительную корреляцию между двумя переменными, основываясь на простоте корреляционного анализа, делают ложные интуитивные предположения о существовании причинно-следственных взаимосвязей между признаками, забывая о том, что коэффициент корреляции носит вероятностный характер.
Пример: количество травмированных во время гололеда и число ДТП среди автотранспорта. Эти величины будут коррелировать между собой, хотя они абсолютно не взаимосвязаны между собой, а имеют только связь с общей причиной этих случайных событий – гололедицей. Если же анализ не выявил корреляционной взаимосвязи между явлениями, это еще не является свидетельством отсутствия зависимости между ними, которая может быть сложной нелинейной, не выявляющейся с помощью корреляционных расчетов.
Первым, кто ввел в научный оборот понятие корреляции, был французский палеонтолог Жорж Кювье. Он в XVIII веке вывел закон корреляции частей и органов живых организмов, благодаря которому появилась возможность восстанавливать по найденным частям тела (останкам) облик всего ископаемого существа, животного. В статистике термин корреляции впервые применил в 1886 году английский ученый Френсис Гальтон. Но он не смог вывести точную формулу для расчета коэффициента корреляции, но это сделал его студент – известнейший математик и биолог Карл Пирсон.