Wayback machine что это за сервис?
Содержание:
- How Big is the Wayback Machine Archive?
- Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
- Reasons for using the Wayback Downloader
- Installation Method 1: The Easy Method
- Что такое веб-архив?
- Качаем сайт с web.archive.org
- Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
- FAQ
- What is Internet Archive Wayback Machine and How Does it Work?
- Whois Lookup
- Screenshots
- Screenshot History for Any Website – Screenshots.com
- The Ghosts of Pages Past 2: How to Use Wayback Machine
- Alexa
- Page Freezer
How Big is the Wayback Machine Archive?
The current estimate is that it contains over 362 billion archived web artifacts since its inception.
Wayback Machine Archived Artifacts Grouped by Type
The pie chart clearly shows that web pages make up the majority of the Archive. They represent 91.24% of the total number of artifacts documented.
This is an enormous archive… but clearly not as large as Google’s index, which includes 100s of trillions of indexed pages.
However, the Wayback Machine can show you a number of different past versions of a particular web page. Google’s index does not do this.
The great thing about this is you can run a Wayback Machine search on any website to see how its content has changed. Assuming of course it is present in the archive in the first place.
Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
Я на этом деле конечно уже собаку съел, так что трудностей не возникло. Но прежде, чем закидывать вас инструкциями, давайте повторим сами себе, с чем имеем дело.
Это обычный рекламный вирус, коих стало пруд пруди. И имен у него много: может быть просто WAYBACK MACHINE, а может с дописанной строкой после имени домена WAYBACK MACHINE. В любом случае вирус закидывает вас рекламой, и про ваше любимое казино Вулкан не забывает. До кучи он заражает и свойства ярлыков браузеров.
Кроме того, вирус обожает создавать расписания для запуска самого себя, чтоб жизнь медом не казалась. В результате его деятельности вы вполне можете случайно кликнуть на нежелательную ссылку и скачать себе что-нибудь более серьезное.
Поэтому данный рекламный вирус следует удалять как можно быстрее. Ниже я приведу инструкции по избавлению от вируса WAYBACK MACHINE, но рекомендую использовать автоматизированный вариант.
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Take content from bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content. Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs.
Installation Method 1: The Easy Method
- 1. Register the domain with your hosting company. If you have registered the domain elsewhere, then create an add-on domain in the cPanel of your hosting company. Here is a tutorial from GoDaddy, that explains how to create an add-on domain.
- 2. Login to cPanel and go to «File Manager», as shown in the picture below:
- 3. Browse to the root folder of your domain. Normally this is /public_html/example.com, as shown below. For this tutorial, we used the domain buy-searchengine.com. Then click on «Upload»:
- 4. Then upload the ZIP file, as shown in the picture below. This assumes that you have already downloaded the ZIP file from waybackmachinedownloader.com.
- 5. Extract the ZIP file:
- 6. That’s it! If you purchased the domain and the hosting from different companies, then you still have to change the name servers at your domain registrar, and change them with the name servers from your hosting company.
- 7. If you want to edit the front page, then go to the File Manager and edit the index.html file, using a text editor. You might find it easier to copy part of that file and edit it with an online HTML editor.
WordPress installation instructions
If you also ordered the WordPress conversion, then wait until one of our developers sends you a ZIP file with WordPress files. This might take up to 48 hours after the scraping has finished.
It might sound strange, but you can not use a «Managed WordPress» hosting package. It doesn’t provide enough rights to edit the database. However, any cheap shared hosting package works, as long as it uses Apache. You can get this from providers such as Godaddy or Hostgator. We recommend Namecheap because it’s good enough and costs only $35/year.
- 8. Upload and extract this ZIP file as described above in step 2-6, in the same way as you would do with a zip file with HTML files. In the ZIP file there is also a folder called «database». If you want to save some time, you can remove this folder from the ZIP file, because you do not need to upload it. You will need the folder later though.
- 9. Go to your cPanel and open «MySQL Databases». Create a new database. You can name it anything, but in our example we use the name of our domain. You will need this name later, so pick something easy.
- 10. Create a new user and password. The name can be anything, but you’ll need it later.
- 11. Add this user to the database. Give your new user access to all privileges.
- 12. On your own computer, unzip the folder called «database». For example, unzip this to your desktop.
- 13. Go to your cPanel and open «phpMyAdmin».
- 14. First select your database on the left panel, by clicking on it. Then click «import» and import the database. This is the .sql file in the folder called «database».
- 15. Go to File Manager and find the file called «wp-config.php». Open this file in a text editor.
-
16. In wp-config.php, edit the database name, database user name and database password. Use the values that you created in step 9 and 10.
With some hosts you also have to change the hostname, but with 95%+ of hosting companies, you can leave this as «localhost». For example with iPage it is «UsernameOfYourAccount.ipagemysql.com» - 17. That’s it! Your WordPress website should now work.
Что такое веб-архив?
Для того, чтобы узнать, что такое веб-архив, стоит вспомнить события, произошедшие более 20 лет назад. В 1996 году по инициативе американского программиста, Брюстера Кайла, был создан сайт archiveorg. Благодаря этому ресурсу, любой пользователь может найти сохранённые копии сайтов разных лет.

Со временем библиотека Web archive расширилась и к 2016 году включала в себя 502 миллиарда копий веб-страниц. Это является одним из лучших примеров коллаборации с целью принести обществу пользу. Для того, чтобы посмотреть в реальном времени сайты, которые функционировали некоторое время назад, достаточно зайти в архив и найти его в системе.
Основной целью, которую преследовал Кайл, было сохранение исторические ценности интернет-пространства. Web archive может использовать каждый пользователь, при этом бесплатно. Для работы веб-архива по сохранению интернет-ресурсов может быть только одно препятствие. Если в настройках сайта нет запрета на сохранение информации с ресурса, такой сайт сможет войти в базу веб-архива.
Как происходит пополнение веб-архива? Для этого было создано программное обеспечение, посещающее и сохраняющее сайта с определённой частотой. Так же есть возможность делать сохранения ресурсов вручную. Например, при посещении сайта можно сохранить страницу о курсах СЕО для начинающих или любую другую часть ресурса. Это поможет сохранить информацию с течением времени.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:

Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:

Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:

Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.

Долистал я до 23 октября 2017-го и вижу уже другое содержимое:

Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:

А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
 После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
 Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
 Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page
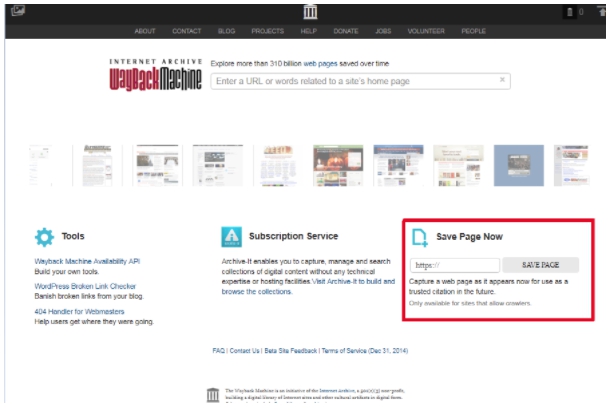 Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
FAQ
I download from Wayback Machine but can use only a home page of the site, why?
The site you download from Wayback Machine needs to be installed on the server. You can’t just view all its pages on your PC. Also, make sure you’ve installed thefile called .htaccess on the server – it is responsible for the correctness of URLs working. Mind that it is compatible with Apache servers only. Finally, checkwhether you used a demo or paid archive.org Downloader. The demo version has a limit of 4 pages.
Why does Wayback Machine Downloader work slowly?
Sometimes, when you download Wayback Machine sites, you have to wait for several hours until the process is completed, especially is the site is large. This is primarily the fault of the Web Archive itself rather than the archive.org Downloader. The Archive is slow; moreover, it can block IPs, which try to downloadWayback Machine files too fast. The speed can further drop down if the original site contains many broken links.
Don’t I break the copyright laws by using the Wayback Machine Downloader?
If you use the archive.org Downloader to restore your own site, then, obviously, you don’t violate any laws, and the content belongs to you. When it comes to accessing third-party sites by using Wayback downloads, the legislative norms can vary from one country to another. But anyway, the risk is minimal, as few peoplecare much about their former websites. Thus, there are no recorded cases of complaints about using third-party expired content.
How long should I wait for the delivery of a WordPress conversion?
The conversion itself usually takes no more than 1-2 business days. But you need to keep in mind that depending on the Wayback Machine download site size, thedownload process can take from several hours to several days.
Will the Downloader tool archive entire website or a single page that I specify?
The Wayback Machine Downloader always extracts entire sites (up to 20 thousand pages per domain.) All the pages that can be accessed from the starting page willbe automatically downloaded.
What is the total number of files the Wayback Machine Downloader can extract?
The Wayback Machine Downloader will try to get all files that are found on the domain. But sometimes, attempts fail if the Web Archive declines the requests. Commonly, the webarchive extractor makes up to five attempts using different IP-addresses.
If you have additional questions of how to download from archive.org effectively and correctly, read the full review on the official site of the download WaybackMachine tool. It contains detailed guides and instructions on archive downloading, extracting, installing, and using.
What is Internet Archive Wayback Machine and How Does it Work?
Internet Archive Wayback Machine is a digital archive of the World Wide Web and other information on the Internet like millions of free books, movies, software, music, websites, and more. Wayback Machine is launched by the Internet Archive (a non-profit organization) in October 2001 to search the history of over three hundred billion web pages on the Internet.
Accessing the archived versions of Web sites using the Internet Archive Wayback Machine is pretty simple. Only you have to type in a URL, select a date range, and then begin surfing on an archived version of the Web.
It’s a true fact that many businesses and companies depend on it to develop business strategies and understand their competitors as well as customers. Internet Archive WaybackMachine freely provides the options to view the history of an archived website and how it was developed.
Internet Wayback Machine is frequently used by journalists and citizens to search for the web pages no longer accessible to the public, dated news reports or changes to website contents over a long period of time.
Although, Internet Archive Wayback Machine offers pretty much everything which can be found in an ideal internet archiving site. But if you are interested in knowing about some of the best Internet Archive Wayback Machine alternatives or similar sites like Wayback machine then this guide is just perfect for you.
Whois Lookup
You can use Whois not only to get complete information (domain name searches, registration & availability) about a website but also the archive version of websites. You can even find out the domain registration date and expiration date using the Whois.net site.

Simply, enter the URL of the website in the search bar and hit the Search button and Whois will do the rest of work for you. Whois is available for free and you don’t even have to register for any free account in order to use any of its services.
Thus, we can say that Whois Lookup is one of the most trusted sources of domain history and best alternatives to Wayback Machine.
You might also like to see: Top 20 Best Free Notepad++ Alternatives for Windows
Screenshots
Screenshots can be a good alternative to Wayback Machine, if you want to see how a website actually looked like in the past. Internet archiving websites, including Wayback Machine, copy the web page code and save it for future reference. However, Screenshots just takes a snapshot of a web page and then archives it.
How it Works
Screenshots use the WHOIS database of DomainTools to find the websites to archive and then use snapshots to make a record of them. The time and frequency of taking snapshots for a particular website depends on how many times it got updated with new content.
If a website gets updated frequently with big changes, then it will also be archived more often and you will find more snapshots of it in Screenshots’ history. However, if a website doesn’t get updated frequently or there are not many changes in the design of the website, then you should expect fewer snapshots.
So far, Screenshots has been able to amass over 250 millions snapshots, which is actually nothing compared to 436 billion pages collected by Wayback Machine. However in our experience, Screenshots covered snapshots of many of the popular websites quite well. They had many snapshots of blogs, but not so many of business websites.
Although, snapshots for average websites that have been created hardly a year ago and don’t have much presence were not archived by Screenshots. On the other hand, Wayback Machine showed their complete history. So we guess Screenshots is best when you want to check history of popular websites.
Practical Use
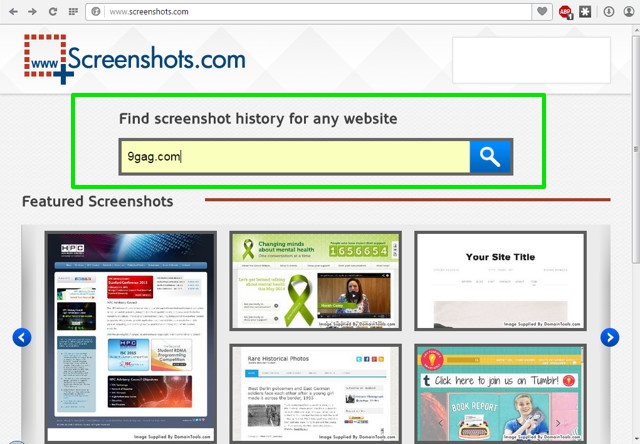
Using Screenshots is dead simple, you either browse snapshots of featured images based on news, popularity and frequency of updates or search for a particular website in the search bar. While searching, make sure you enter complete address, for example “beebom.com” not “beebom”.
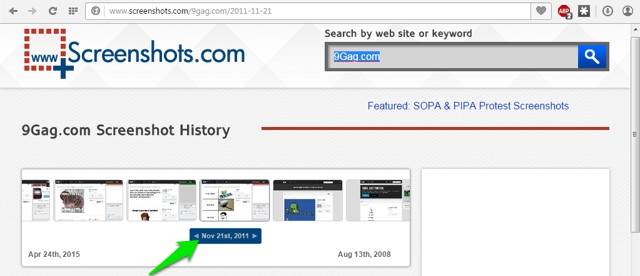
When you will search, you will find all the snapshots in a horizontal pane with a blue slider below it. You will find the latest snapshot taken date at the left of the pane and oldest on the right.
To search snapshots, just start moving the slider from left to right and you will see all the snapshots with the date they were taken, below them. Clicking on the snapshots will show a preview of them below.
You will see all the details about the website you searched for in the right panel to the Preview window. The details include, latest and oldest screenshots date, total number of screenshots, WHOIS first history record for the domain, total number of domains on the same hosting and link to complete WHOIS record of the website. You will also find some similar websites that you may like to checkout.
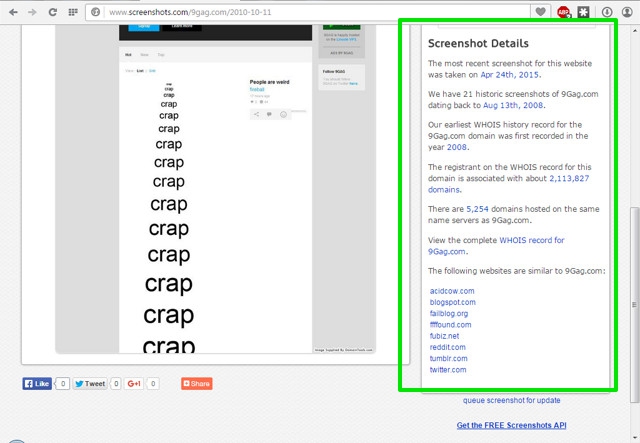
Key Features: Takes screeshonts instead of copying code, easy to use with simple interface and provides complete WHOIS record of the domain.
Cons: Takes screenshots less frequently and doesn’t archives less popular websites.
Screenshot History for Any Website – Screenshots.com
The first internet Wayback machine alternative which makes our list is Screenshots. This internet archive website takes the screenshot of any website and saves it in a database that allows users to access the cached copy of that website in future. The website claims to have 250 million historical website screenshots.
It will provide you complete information about the website you searched for within a few minutes. All you have to do is enter the URL of the website which you want to check in the Search field and hit on the Search button.
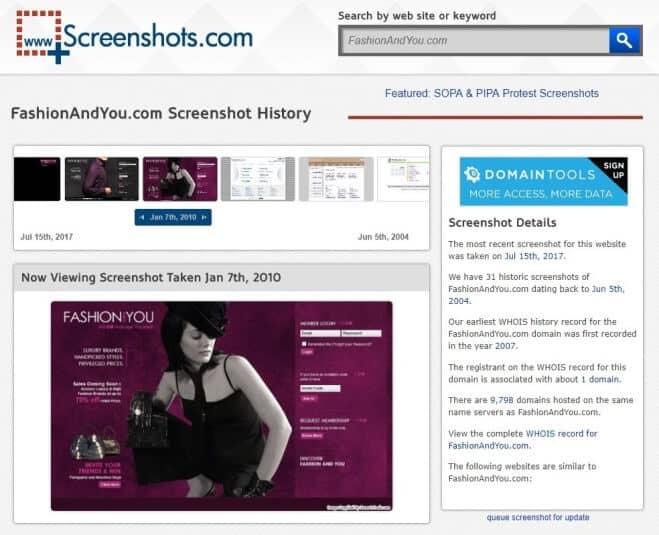
The results will show you two screenshots out of which one will show you the current state of the website and another one will show you how the website looked a while ago. If a website is updated multiple times, Screenshots is going to display multiple variations of the same. This site uses the Whois database of DomainTools to find the websites to archive.
When it comes to the matters of archived screenshots of any website or webpages then Screenshots.com is the most appropriate Internet Archive Wayback Machine alternative site.
You might also like: Top 10 Best uTorrent Alternatives to Download Movies Free
The Ghosts of Pages Past 2: How to Use Wayback Machine
Visit https://archive.org/web/
At the top of the page you’ll see a search box. Type in the domain you’d like to examine and if it has been archived you’ll see something like this:
You can use the timeline at the top of the page to select a particular year. You could also look at one of the circles in the calendar for the year you can currently see. Remember though that only days highlighted with a coloured circle have archived pages.
Hovering on a coloured circle will show you the number of snapshots Wayback Machine took on that day.
Clicking one of the snapshots takes you to the archived version of the page as it looked at that time.
You can click on any links you see on the archived page to browse an archived version of the site. You’ll then see how other pages within the site appeared at that time also.
Alternatively, you can click on the timeline at the top of the page to examine archives from a different year.
It’s that simple!
Alexa
Alexa is well known for checking website ranking, keyword research, and competitive analysis. But it is also one of the best Internet Archive Wayback Machine alternatives which you can use to view the archived state of any website.
The user-friendly interface of this website makes it very easy for one to use it and find out what they are looking for.
Owned by Amazon.com, Alexa provides complete information about a website that includes domain information, how old the website is, links, referring domains to the website and much more.

You can even find out the browsing details and past history of any website using Alexa. Clicking on “How did example.com look in the past?” will redirect you to http://web.archive.org to see the calendar view maps (the number of times a particular site has crawled by the Wayback Machine, not how many times the site was actually updated).
If you want to see detailed information about any website, you need to create a free account on Alexa. In short, we can say that Alexa is one of the most reliable Internet Archive Wayback alternatives for everybody.
Do you know? How to Download Movies from Hotstar on Android and Computer
Page Freezer
Page Freezer is an extremely easy-to-use web and social media archiving service that automatically archives all your website content. This popular alternative to Wayback Machine is used by both webmasters and internet users as webmasters can use it for automatic archiving of web pages and users can find out the archived version of websites that are present on the internet.

The user-friendly interface of Page Freezer makes it very easy for one to see the archived version of the web pages of a website. The only problem with this Internet Wayback Machine alternatives is that you will have to login in order to see the archived web pages or protect your website records.